已经开始听喜马拉雅Fm电台有2个月,听里面的故事,感觉能听到自己,特别是蕊希电台,始于声音,陷于故事,忠于总结。感谢喜马拉雅Fm陪我度过了这2个月,应该是太爱了,然后就开始对Fm下手了。QAQ
该博客基于以下博客,提取和修改。
https://www.jianshu.com/p/8ff95111b18a
https://www.imooc.com/article/48315
需要解决问题
1.m4a文件储存在json文本中 --f12审查元素,使用json.loads读取信息 2.将其他主播的所有音频文件也下载 3.下载文件时,对提取的文件进行分类 --提取主播id,使用meta进行传递
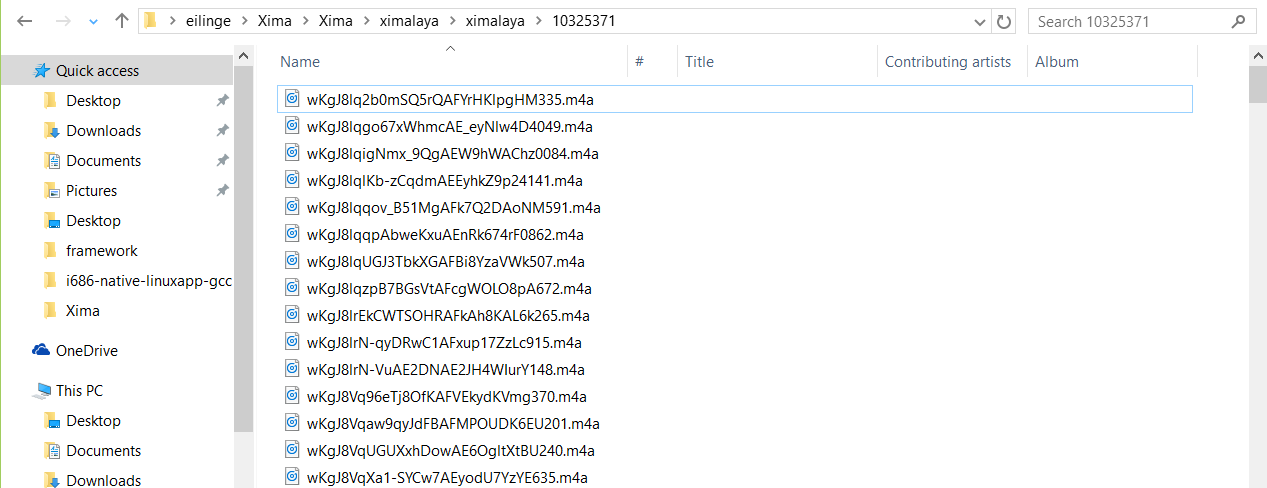
三、先给大家看看成果

一、提取网页源码
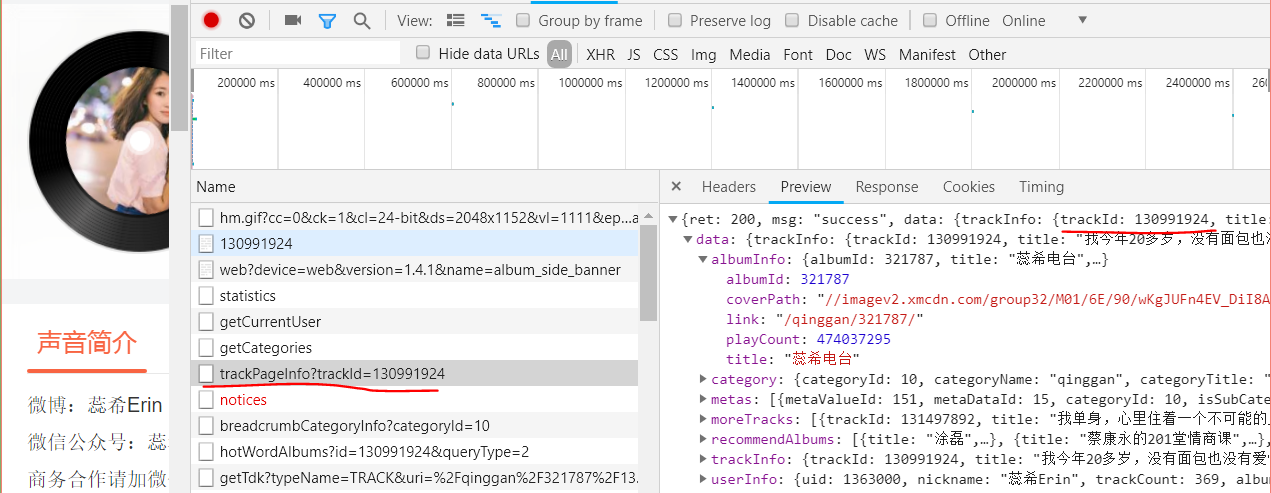
1.1_提取trackId:"https://www.ximalaya.com/qinggan/321787/130991924"
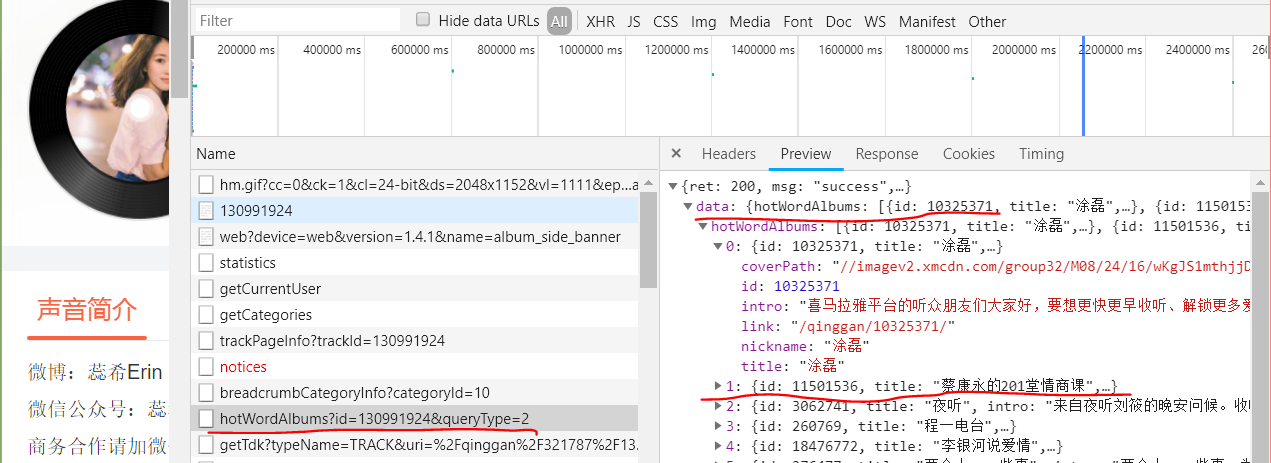
1.2_提取其他主播Id
1.3_主播所有作品的trackId:"http://www.ximalaya.com/revision/album/getTracksList?albumId=321787&pageNum=13"

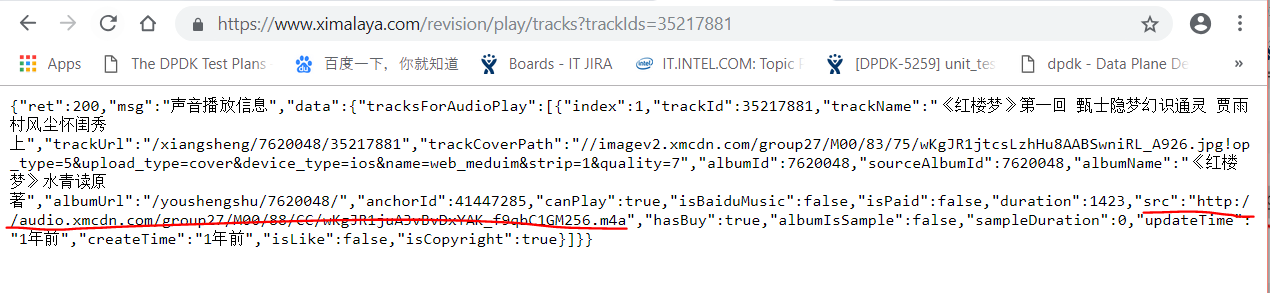
1.4_提取.m4a文件:https://www.ximalaya.com/revision/play/tracks?trackIds=35217881
二、代码设置:middlewares.py,settings.py,items.py就不细讲了,可以看我之前的博客。
2.1_pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import scrapy from os.path import join,basename,dirname import os import urlparse from scrapy.pipelines.files import FilesPipeline from Xima.settings import FILES_STORE from scrapy.exceptions import DropItem class XimaPipeline(FilesPipeline): def get_media_requests(self,item,info): yield scrapy.Request(item['m4_urls'],meta={"file_name":item['file_name'],'m4_urls':item['m4_urls']}) def file_path(self,request,response=None,info=None): #get_media_requests函数是返回了一个request对象的,而这个request对象就是file_path函数接收的那个 item = request.meta return join(FILES_STORE, item['file_name'] + '\' + basename(item['m4_urls'])) def item_completed(self, results, item, info): file_paths = [x['path'] for ok, x in results if ok] if not file_paths: raise DropItem("Item contains no files") return item
2.2_爬取代码
# -*- coding: utf-8 -*- import scrapy from Xima.items import XimaItem import json import pdb from Xima.settings import USER_AGENT import random class XimaSpider(scrapy.Spider): name = 'xima' allowed_domains = ['www.ximalaya.com'] start_urls = ['https://www.ximalaya.com/revision/seo/hotWordAlbums?id=321787&queryType=1'] headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Connection': 'keep-alive', 'Content-Length': '11', 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'Host': 'www.ximalaya.com', 'Origin': 'www.ximalaya.com', 'Referer': 'https://www.ximalaya.com/revision/seo/hotWordAlbums?id=321787&queryType=1', 'User-Agent': random.choice(USER_AGENT), 'X-Requested-With': 'XMLHttpRequest', } def start_requests(self): yield scrapy.Request(self.start_urls[0],callback=self.parse_1) def parse_1(self,response): for each_url in json.loads(response.body)['data']['hotWordAlbums']: for i in xrange(20): new_url = 'http://www.ximalaya.com/revision/album/getTracksList?albumId='+str(each_url['id'])+'&pageNum='+str(i) yield scrapy.Request(new_url,callback=self.parse,meta={'trackid':str(each_url['id'])}) def parse(self, response): if json.loads(response.body)['data']['tracks']: for sel in json.loads(response.body)['data']['tracks']: stackids = sel['trackId'] meta1 = response.meta yield scrapy.Request('https://www.ximalaya.com/revision/play/tracks?trackIds=%s'%stackids,callback=self.m4a,meta=meta1) def m4a(self,response): xima = XimaItem() if json.loads(response.body)['data']['tracksForAudioPlay'][0]['src']: xima['file_name'] = response.meta['trackid'] xima['m4_urls'] = json.loads(response.body)['data']['tracksForAudioPlay'][0]['src'] yield xima