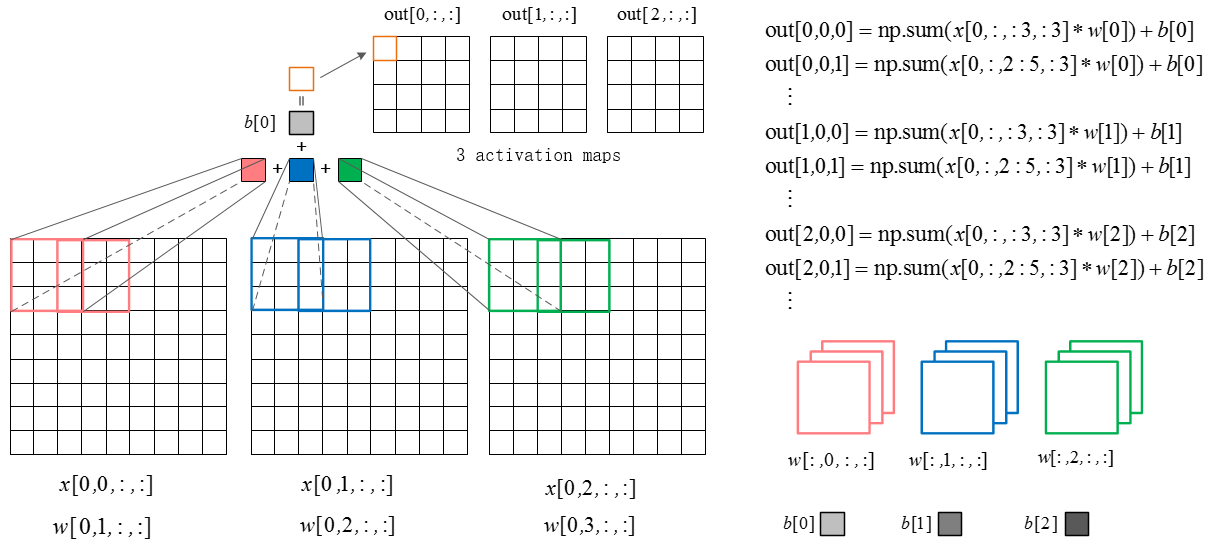
1、参数共享的道理
如果在图像某些地方探测到一个水平的边界是很重要的,那么在其他一些地方也会同样是有用的,这是因为图像结构具有平移不变性。所以在卷积层的输出数据体的55x55个不同位置中,就没有必要重新学习去探测一个水平边界了。
在反向传播的时候,都要计算每个神经元对它的权重的梯度,但是需要把同一个深度切片上的所有神经元对权重的梯度累加,这样就得到了对共享权重的梯度。这样,每个切片只更新一个权重集。
2、归一化层效果有限,可以不用
3、全连接层转化为卷积层
在两种变换中,将全连接层转化为卷积层在实际运用中更加有用。
让卷积网络在一张更大的输入图片上滑动(译者注:即把一张更大的图片的不同区域都分别带入到卷积网络,得到每个区域的得分),得到多个输出,这样的转化可以让我们在单个向前传播的过程中完成上述的操作。面对384x384的图像,让(含全连接层)的初始卷积神经网络以32像素的步长独立对图像中的224x224块进行多次评价,其效果和使用把全连接层变换为卷积层后的卷积神经网络进行一次前向传播是一样的。
这一技巧在实践中经常使用,一次来获得更好的结果。比如,通常将一张图像尺寸变得更大,然后使用变换后的卷积神经网络来对空间上很多不同位置进行评价得到分类评分,然后在求这些分值的平均值。
4、使用多个小卷积核代替大卷积核
假设所有的数据有 C 个通道,那么单独的7x7卷积层将会包含 C*(7*7*C)=49C*C 个参数,而3个3x3的卷积层的组合仅有3*(C*(3*3*C))=27C*C个参数。直观说来,最好选择带有小滤波器的卷积层组合,而不是用一个带有大的滤波器的卷积层。前者可以表达出输入数据中更多个强力特征,使用的参数也更少。唯一的不足是,在进行反向传播时,中间的卷积层可能会导致占用更多的内存。
5、层的尺寸设置规律
(1)输入层(包含图像的)应该能被2整除很多次。常用数字包括32(比如CIFAR-10),64,96(比如STL-10)或224(比如ImageNet卷积神经网络),384和512。
(2)卷积层应该使用小尺寸滤波器(比如3x3或最多5x5),使用步长S=1。还有一点非常重要,就是对输入数据进行零填充,这样卷积层就不会改变输入数据在空间维度上的尺寸。如果必须使用更大的滤波器尺寸(比如7x7之类),通常只用在第一个面对原始图像的卷积层上。
(3)汇聚层负责对输入数据的空间维度进行降采样。最常用的设置是用用2x2感受野的最大值汇聚,步长为2。注意这一操作将会把输入数据中75%的激活数据丢弃(因为对宽度和高度都进行了2的降采样)。另一个不那么常用的设置是使用3x3的感受野,步长为2。最大值汇聚的感受野尺寸很少有超过3的,因为汇聚操作过于激烈,易造成数据信息丢失,这通常会导致算法性能变差。
减少尺寸设置的问题:上文中展示的两种设置是很好的,因为所有的卷积层都能保持其输入数据的空间尺寸,汇聚层只负责对数据体从空间维度进行降采样。如果使用的步长大于1并且不对卷积层的输入数据使用零填充,那么就必须非常仔细地监督输入数据体通过整个卷积神经网络结构的过程,确认所有的步长和滤波器都尺寸互相吻合,卷积神经网络的结构美妙对称地联系在一起。
6、计算上的考量
- 来自中间数据体尺寸:卷积神经网络中的每一层中都有激活数据体的原始数值,以及损失函数对它们的梯度(和激活数据体尺寸一致)。通常,大部分激活数据都是在网络中靠前的层中(比如第一个卷积层)。在训练时,这些数据需要放在内存中,因为反向传播的时候还会用到。但是在测试时可以聪明点:让网络在测试运行时候每层都只存储当前的激活数据,然后丢弃前面层的激活数据,这样就能减少巨大的激活数据量。
- 来自参数尺寸:即整个网络的参数的数量,在反向传播时它们的梯度值,以及使用momentum、Adagrad或RMSProp等方法进行最优化时的每一步计算缓存。因此,存储参数向量的内存通常需要在参数向量的容量基础上乘以3或者更多。
- 卷积神经网络实现还有各种零散的内存占用,比如成批的训练数据,扩充的数据等等。
一旦对于所有这些数值的数量有了一个大略估计(包含激活数据,梯度和各种杂项),数量应该转化为以GB为计量单位。把这个值乘以4,得到原始的字节数(因为每个浮点数占用4个字节,如果是双精度浮点数那就是占用8个字节),然后多次除以1024分别得到占用内存的KB,MB,最后是GB计量。如果你的网络工作得不好,一个常用的方法是降低批尺寸(batch size),因为绝大多数的内存都是被激活数据消耗掉了。
转自:https://zhuanlan.zhihu.com/p/22038289?refer=intelligentunit