1、Factorization Machines(FM)
FM主要目标是:解决大规模稀疏数据下的特征组合问题。根据paper的描述,FM有一下三个优点:
- 可以在非常稀疏的数据中进行合理的参数估计
- FM模型的时间复杂度是线性的
- FM是一个通用模型,它可以用于任何特征为实值的情况
算法原理:在一般的线性模型中,是各个特征独立考虑的,没有考虑到特征与特征之间的相互关系。但实际上,大量的特征之间是有关联的。一般的线性模型为:

Wide & Deep、DeepFM系列算法原理与优缺点对比
2、Field-aware Factorization Machines(FFM)
FFM把相同性质的特征归于同一个field。因此,隐向量不仅与特征相关,也与field相关。这也是FFM中“Field-aware”的由来。
算法原理:设样本一共有n nn个特征, f ff 个field,那么FFM的二次项有n f nfnf个隐向量。而在FM模型中,每一维特征的隐向量只有一个。FM可以看作FFM的特例,是把所有特征都归属到一个field时的FFM模型。根据FFM的field敏感特性,可以导出其模型方程。
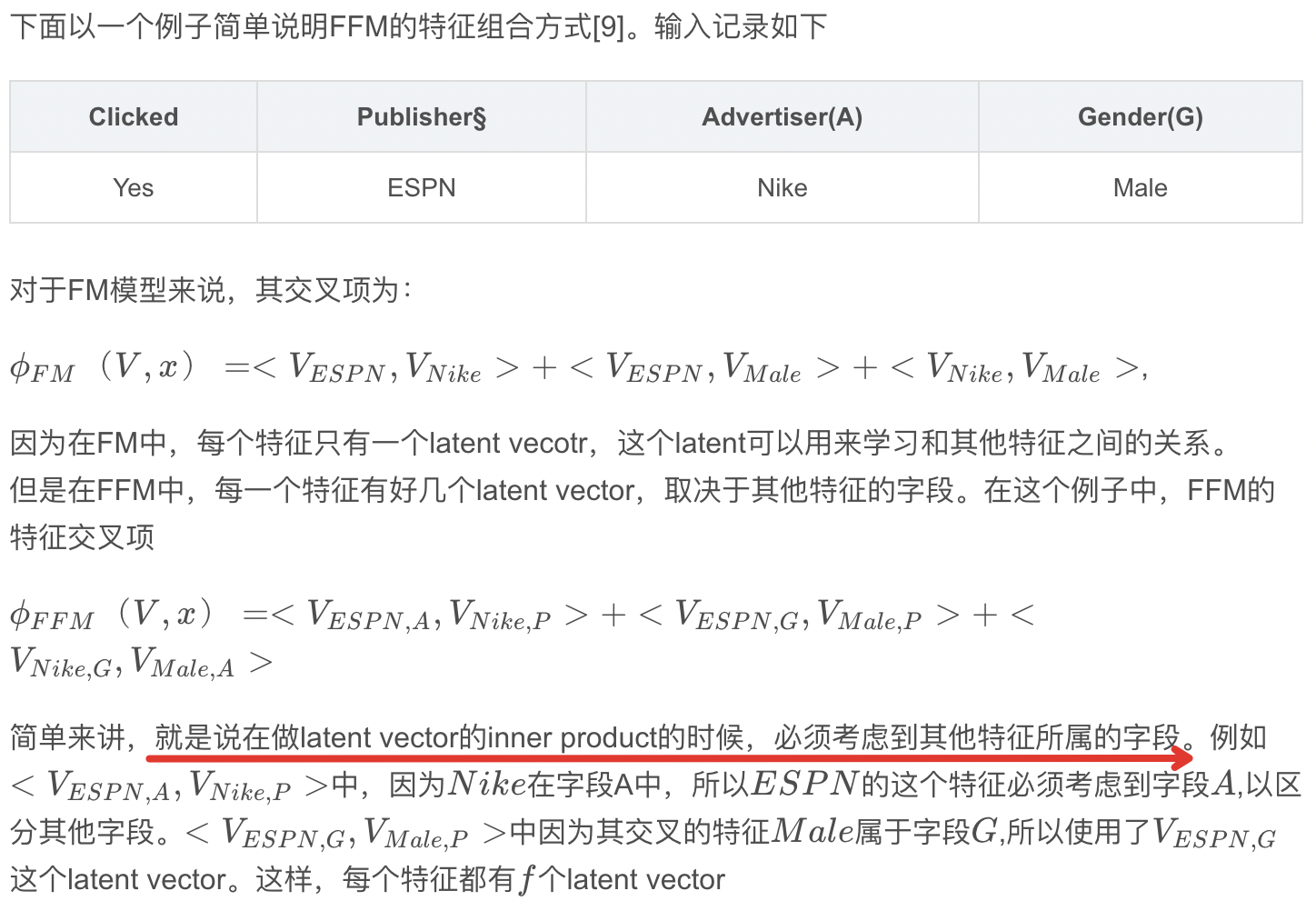
3、Google Wide&Deep(2016年)——记忆能力和泛化能力的综合权衡

Google Wide&Deep模型的主要思路正如其名,把单输入层的Wide部分和经过多层感知机的Deep部分连接起来,一起输入最终的输出层。其中Wide部分的主要作用是让模型具有记忆性(Memorization),单层的Wide部分善于处理大量稀疏的id类特征,便于让模型直接“记住”用户的大量历史信息;Deep部分的主要作用是让模型具有“泛化性”(Generalization),利用DNN表达能力强的特点,挖掘藏在特征后面的数据模式。最终利用LR输出层将Wide部分和Deep部分组合起来,形成统一的模型。Wide&Deep对之后模型的影响在于——大量深度学习模型采用了两部分甚至多部分组合的形式,利用不同网络结构挖掘不同的信息后进行组合,充分利用和结合了不同网络结构的特点。
在此解释一下Dense Embedding:矩阵乘法。是针对稀疏特征的一种降维方式,它降维的方式可以类比为一个全连接层(没有激活函数),通过 embedding 层的权重矩阵计算来降低维度。假设:
- feature_num : 原始特征数
- embedding_size: embedding之后的特征数
- [feature_num, embedding_size] 权重矩阵shape
- [m, feature_num] 输入矩阵shape,m为样本数
- [m, embedding_size] 输出矩阵shape,m为样本数
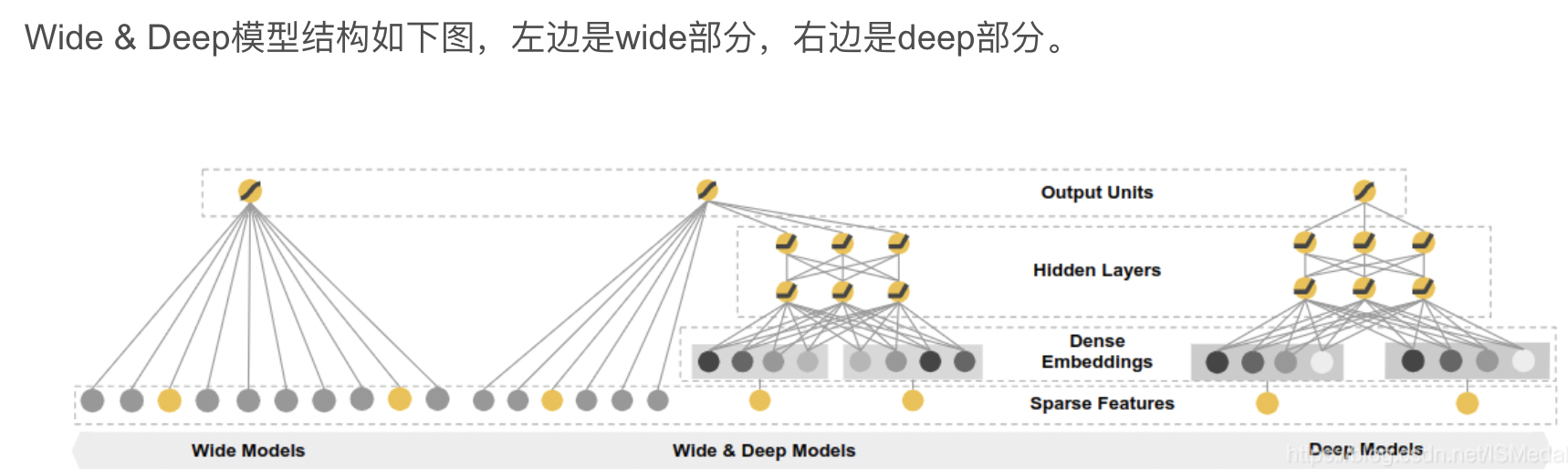
4、DeepFM
对于一个基于CTR预估的推荐系统,最重要的是学习到用户点击行为背后隐含的特征组合。在不同的推荐场景中,低阶组合特征或者高阶组合特征可能都会对最终的CTR产生影响。
人工方式的特征工程,通常有两个问题:一个是特征爆炸。以通常使用的Poly-2模型为例,该模型采用直接对2阶特征组合建模来学习它们的权重,这种方式构造的特征数量跟特征个数乘积相关,例如:加入某类特征有1万个可能的取值(如APP),另一类特征也有1万个可能的取值(如用户),那么理论上这两个特征组合就会产生1亿个可能的特征项,引起特征爆炸的问题;如果要考虑更高阶的特征,如3阶特征,则会引入更高的特征维度,比如第三个特征也有1万个(如用户最近一次下载记录),则三个特征的组合可能产生10000亿个可能的特征项,这样高阶特征基本上无法有效学习。另一个问题是大量重要的特征组合都隐藏在数据中,无法被专家识别和设计 (关于这个的一个有名的例子是啤酒和尿片的故事)。依赖人工方式进行特征设计,存在大量有效的特征组合无法被专家识别的问题。实现特征的自动组合的挖掘,就成为推荐系统技术的一个热点研究方向,深度学习作为一种先进的非线性模型技术在特征组合挖掘方面具有很大的优势。
针对上述两个问题,广度模型和深度模型提供了不同的解决思路。
(1)其中广度模型包括FM/FFM等大规模低秩(Low-Rank)模型,FM/FFM通过对特征的低秩展开,为每个特征构建隐式向量,并通过隐式向量的点乘结果来建模两个特征的组合关系实现对二阶特征组合的自动学习。作为另外一种模型,Poly-2模型则直接对2阶特征组合建模来学习它们的权重。FM/FFM相比于Poly-2模型,优势为以下两点。第一,FM/FFM模型所需要的参数个数远少于Poly-2模型:FM/FFM模型为每个特征构建一个隐式向量,所需要的参数个数为O(km),其中k为隐式向量维度,m为特征个数;Poly-2模型为每个2阶特征组合设定一个参数来表示这个2阶特征组合的权重,所需要的参数个数为O(m^2)。第二,相比于Poly-2模型,FM/FFM模型能更有效地学习参数:当一个2阶特征组合没有出现在训练集时,Poly-2模型则无法学习该特征组合的权重;但是FM/FFM却依然可以学习,因为该特征组合的权重是由这2个特征的隐式向量点乘得到的,而这2个特征的隐式向量可以由别的特征组合学习得到。总体来说,FM/FFM是一种非常有效地对二阶特征组合进行自动学习的模型。
(2)深度学习是通过神经网络结构和非线性激活函数,自动学习特征之间复杂的组合关系。目前在APP推荐领域中比较流行的深度模型有FNN/PNN/Wide&Deep;FNN模型是用FM模型来对Embedding层进行初始化的全连接神经网络。PNN模型则是在Embedding层和全连接层之间引入了内积/外积层,来学习特征之间的交互关系。Wide&Deep模型由谷歌提出,将LR和DNN联合训练,在Google Play取得了线上效果的提升。
但目前的广度模型和深度模型都有各自的局限。广度模型(LR/FM/FFM)一般只能学习1阶和2阶特征组合;而深度模型(FNN/PNN)一般学习的是高阶特征组合。在之前的举例中可以看到无论是低阶特征组合还是高阶特征组合,对推荐效果都是非常重要的。Wide&Deep模型依然需要人工特征工程来为Wide模型选取输入特征。
DeepFM模型结合了广度和深度模型的有点,联合训练FM模型和DNN模型,来同时学习低阶特征组合和高阶特征组合。此外,DeepFM模型的Deep component和FM component从Embedding层共享数据输入,这样做的好处是Embedding层的隐式向量在(残差反向传播)训练时可以同时接受到Deep component和FM component的信息,从而使Embedding层的信息表达更加准确而最终提升推荐效果。DeepFM相对于现有的广度模型、深度模型以及Wide&Deep; DeepFM模型的优势在于:
- DeepFM模型同时对低阶特征组合和高阶特征组合建模,从而能够学习到各阶特征之间的组合关系
- DeepFM模型是一个端到端的模型,不需要任何的人工特征工程
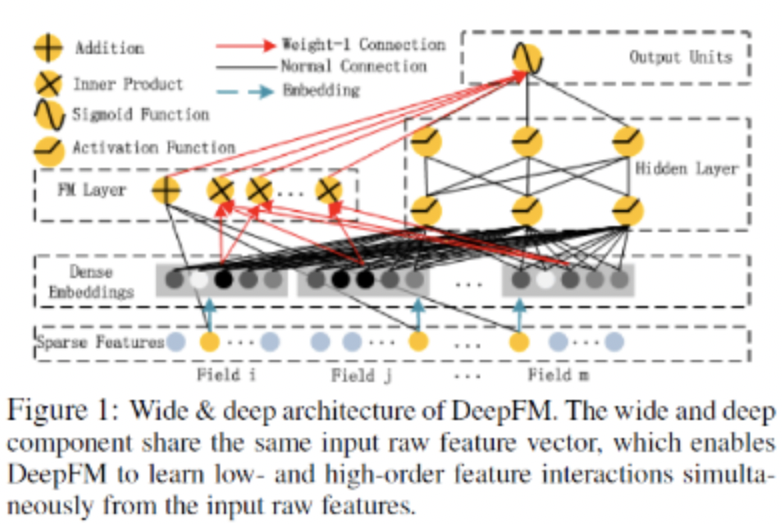

深度部分是一个前馈神经网络,可以学习高阶的特征组合。需要注意的是原始的输入的数据是很多个字段的高维稀疏数据。因此引入一个embedding layer将输入向量压缩到低维稠密向量。embedding layer的结构如下图所示:
embedding layer有两个有趣的特性:
- 输入数据的每个字段的特征经过embedding之后,都为k kk维(lantent vector的维度),所以embedding后的特征维度是 字 段 数 × k
- 在FM里得到的隐变量V现在作为了嵌入层网络的权重,FM模型作为整个模型的一部分与其他深度学习模型一起参与整体的学习, 实现端到端的训练。

5、PPNet 参数个性化CTR模型
在语音识别领域中,2014年和2016年提出的LHUC算法(learning hidden unit contributions)核心思想是做说话人自适应(speaker adaptation),其中一个关键突破是在DNN网络中,为每个说话人学习一个特定的隐式单位贡献(hidden unit contributions),来提升不同说话人的语音识别效果。借鉴LHUC的思想,快手推荐团队在精排模型上展开了尝试。经过多次迭代优化,推荐团队设计出一种gating机制,可以增加DNN网络参数个性化并能够让模型快速收敛。快手把这种模型叫做PPNet(Parameter Personalized Net)。据快手介绍,PPNet于2019年全量上线后,显著的提升了模型的CTR目标预估能力。
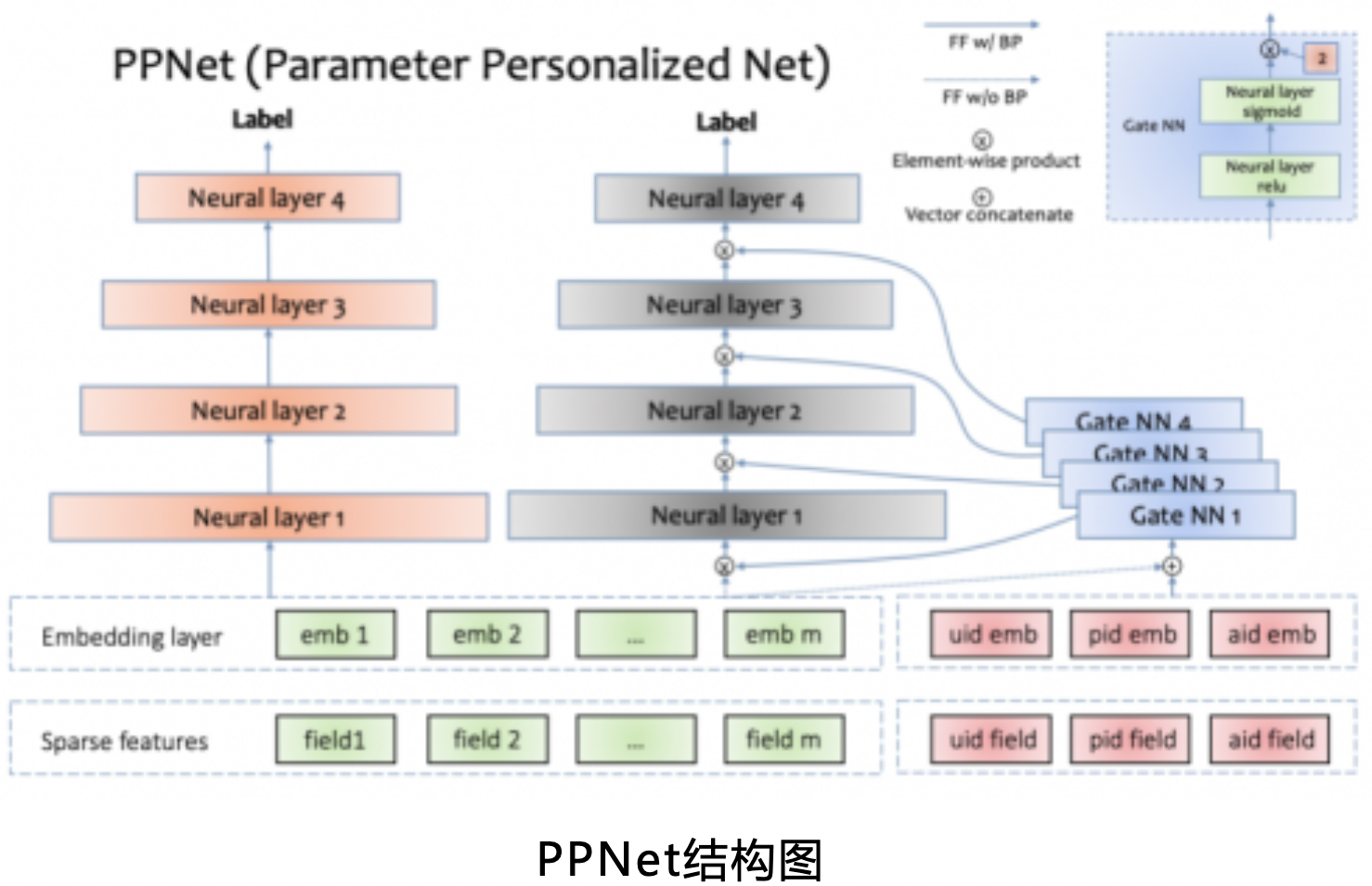
PPNet的左侧是目前常见的DNN网络结构,右侧是PPNet特有的模块,包括Gate NN和只给Gate NN作为输入的id特征。其中uid,pid,aid分别表示user id,photo id,author id。左侧的所有特征的embedding会同这3个id特征的embedding拼接到一起作为所有Gate NN的输入。
需要注意的是,左侧所有特征的embedding并不接受Gate NN的反传梯度,这样操作的目的是减少Gate NN对现有特征embedding收敛产生的影响。
Gate NN的数量同左侧神经网络的层数一致,其输出同每一层神经网络的输入做element-wise product来做用户的个性化偏置。
Gate NN是一个2层神经网络,其中第二层网络的激活函数是2 * sigmoid,目的是约束其输出的每一项在[0, 2]范围内,并且默认值为1。当Gate NN输出是默认值时,PPNet同左侧部分网络是等价的。
通过Gate NN为神经网络层输入增加个性化偏置项,可以显著提升模型的目标预估能力。PPNet通过Gate NN来支持DNN网络参数的个性化能力,来提升目标的预估能力,理论上来讲,可以用到所有基于DNN模型的预估场景,如个性化推荐,广告,基于DNN的强化学习场景等。
6、Wide & Deep 与 deepFM 区别
- 两者的DNN部分模型结构相同;
- wide&deep需要做特征工程,二阶特征交叉需要靠特征工程来实现,通过wide部分发挥作用;
- DeepFM完全不需要做特征工程,直接输入原始特征即可,二阶特征交叉靠FM来实现,并且FM和DNN共享相同的embedding;
7、在CTR预估以及推荐系统等场合模型对比
- LR: LR最大的缺点就是无法组合特征,依赖于人工的特征组合,这也直接使得它表达能力受限,基本上只能处理线性可分或近似线性可分的问题。
- FM: FM通过隐向量latent vector做内积来表示组合特征,从理论上解决了低阶和高阶组合特征提取的问题。但是实际应用中受限于计算复杂度,一般也就只考虑到2阶交叉特征。后面又进行了改进,提出了FFM,增加了Field的概念。
- CNN: CNN模型的缺点是:偏向于学习相邻特征的组合特征。
- RNN: RNN模型的缺点是:比较适用于有序列(时序)关系的数据。
- FNN: 先使用预先训练好的FM,得到隐向量,然后作为DNN的输入来训练模型。缺点在于:受限于FM预训练的效果,Embedding的参数受FM的影响,不一定准确;预训练阶段增加了计算复杂度,训练效率低; FNN只能学习到高阶的组合特征。模型中没有对低阶特征建模。
- PNN: PNN为了捕获高阶组合特征,在embedding layer和first hidden layer之间增加了一个product layer。但是内积的计算复杂度依旧非常高,原因是:product layer的输出是要和第一个隐藏层进行全连接的;product layer的输出需要与第一个隐藏层全连接,导致计算复杂度居高不下;和FNN一样,只能学习到高阶的特征组合。没有对于1阶和2阶特征进行建模。
- Wide&Deep:同时学习低阶和高阶组合特征,它混合了一个线性模型(Wide part)和Deep模型(Deep part)。这两部分模型需要不同的输入,而Wide part部分的输入,依旧依赖人工特征工程。
但是,这些模型普遍都存在一个问题:偏向于提取低阶或者高阶的组合特征。不能同时提取这两种类型的特征。 需要专业的领域知识来做特征工程。无论是FNN还是PNN,他们都有一个绕不过去的缺点:对于低阶的组合特征,学习到的比较少。
8、DeepFM:在Wide&Deep的基础上进行改进,不需要预训练FM得到隐向量,不需要人工特征工程,能同时学习低阶和高阶的组合特征;FM模块和Deep模块共享Feature Embedding部分,可以更快的训练,以及更精确的训练学习。
参考文献:https://blog.csdn.net/john_xyz/article/details/78933253
https://blog.csdn.net/ISMedal/article/details/100578354
https://zhuanlan.zhihu.com/p/66928413