START:Flume是Cloudera提供的一个高可用的、高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地。这里的日志是一个统称,泛指文件、操作记录等许多数据。
一、Flume基础理论
1.1 常见的分布式日志收集系统

Scribe是facebook开源的日志收集系统,在facebook内部已经得到大量的应用。 Chukwa 是一个开源的用于监控大型分布式系统的数据收集系统。这是构建在 hadoop 的 hdfs 和 map/reduce 框架之上的,继承了 hadoop 的可伸缩性和鲁棒性。而 Flume 是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
1.2 Flume的数据流模型
Flume的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。
Flume传输的数据的基本单位是Event,如果是文本文件,通常是一行记录,这也是事务的基本单位。Event 从 Source 流向 Channel,再到 Sink,本身为一个byte数组,并可携带headers信息。Event代表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去。
1.3 Flume的三大核心组件
Flume运行的核心是Agent。它是一个完整的数据收集工具,含有三个核心组件,分别是source、channel、sink。通过这些组件,Event可以从一个地方流向另一个地方,如图1所示。
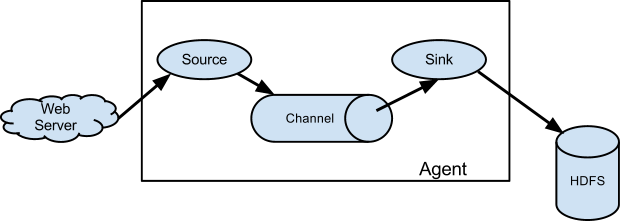
图1 Flume数据流模型
一个flume系统可以由一个或多个agent组成,多个agent只要做一些简单的配置就可以串在一起,比如将两个agent(foo、bar)串在一起工作,只要将bar的source(入口)接在foo的sink(出口)上就可以了。如图2所示。
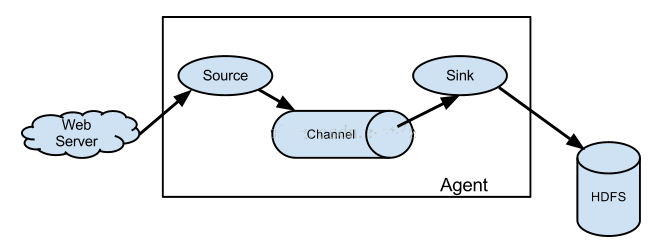
图2 多级Agent连接模型
图3则展示了将4个agent串在一起,agent1、agent2和agent3都是获取web服务器的数据,然后将各自获得到的数据统一地发送给agent4,最后由agent4将收集到的数据存储在hdfs里面。
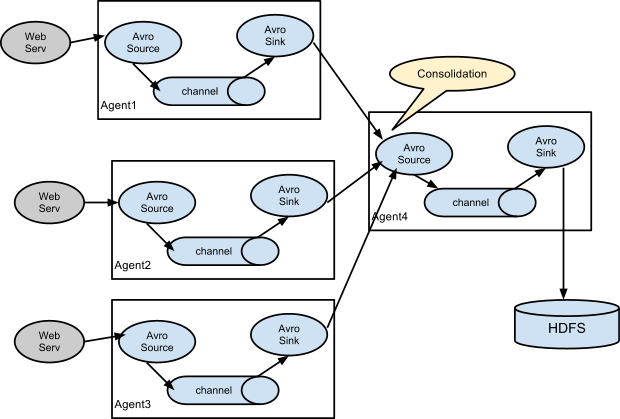
图3 多对一的合并模型
(1)什么是Agent?
Flume的核心是agent。agent是一个java进程,运行在日志收集端,通过agent接收日志,然后暂存起来,再发送到目的地。
(2)三大核心组件
①Source:专用于收集日志,可以处理各种类型各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义等。
②Channel:专用于临时存储数据,可以存放在memory、jdbc、file、数据库、自定义等。其存储的数据只有在sink发送成功之后才会被删除。
③Sink:专用于把数据发送到目的地点,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义等。
理解Source、Channel与Sink:
source为水源,是aent获取数据的入口;
channel为管道,是数据(由resource获得)流动的通道,主要作用是用来传输和存储数据;
sink为水槽,用来接收channel传入的数据并将数据输出到指定地方。
大家可以把agent看作一个水管,source就是水管的入口,sink就是水管的出口,把数据当作水来看,数据流也就意味着水流。数据由source获得流经channel,最后传给sink。如图1就演示了一个完整的agent流程,由webserver获取数据,数据经channel流向sink,最后由sink将数据存储在hdfs里面。
1.3 Flume的可靠性保证
Flume的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。
Flume使用事务性的方式保证传送Event整个过程的可靠性。Sink必须在Event被存入Channel后,或者,已经被传达到下一站agent里,又或者,已经被存入外部数据目的地之后,才能把Event从Channel中remove掉。这样数据流里的event无论是在一个agent里还是多个agent之间流转,都能保证可靠,因为以上的事务保证了event会被成功存储起来。而Channel的多种实现在可恢复性上有不同的保证。也保证了event不同程度的可靠性。比如Flume支持在本地保存一份文件channel作为备份,而memory channel将event存在内存queue里,速度快,但丢失的话无法恢复。
二、Flume基础实践
2.1 Flume基本安装
(1)下载flume的安装包,这里选择的是1.4.0版本的,我已经将其上传到了网盘中(http://pan.baidu.com/s/1kTEFUfX)
(2)解压缩bin与src包,并重命名
Step1.解压缩两个包
tar -zvxf libs/apache-flume-1.4.0-bin.tar.gz
tar -zvxf libs/apache-flume-1.4.0-src.tar.gz
Step2.将源码包拷贝到bin目录中
cp -ri apache-flume-1.4.0-src/* apache-flume-1.4.0-bin/
Step3.【可选】重命名为flume
mv apache-flume-1.4.0-bin flume
2.2 Flume基本配置
本次实践示例Source来自Spooling Directory,Sink流向HDFS。监控/root/edisonchou文件目录下的文件,一旦有新文件,就立刻将文件内容通过agent流向HDFS的hdfs://hadoop-master:9000/testdir/edisonchou文件中。在这之前,我们需要对flume进行基本的配置。
首先,进入flume的conf目录下,新建一个example.conf,其对三大核心组件的配置如下:
(1)配置source
agent1.sources.source1.type=spooldir agent1.sources.source1.spoolDir=/root/edisonchou agent1.sources.source1.channels=channel1 agent1.sources.source1.fileHeader = false agent1.sources.source1.interceptors = i1 agent1.sources.source1.interceptors.i1.type = timestamp
(2)配置channel
agent1.channels.channel1.type=file agent1.channels.channel1.checkpointDir=/root/edisonchou_tmp/123 agent1.channels.channel1.dataDirs=/root/edisonchou_tmp/
(3)配置sink
agent1.sinks.sink1.type=hdfs agent1.sinks.sink1.hdfs.path=hdfs://hadoop-master:9000/testdir/edisonchou agent1.sinks.sink1.hdfs.fileType=DataStream agent1.sinks.sink1.hdfs.writeFormat=TEXT agent1.sinks.sink1.hdfs.rollInterval=1 agent1.sinks.sink1.channel=channel1 agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d
2.3 监控指定目录测试
(1)启动hadoop,老命令:start-all.sh
(2)新建文件夹/root/edisonchou,并在HDFS中新建目录/testdir/edisonchou
(3)在flume目录中执行以下命令启动示例agent
bin/flume-ng agent -n agent1 -c conf -f conf/example.conf -Dflume.root.logger=DEBUG,console

出现上图所示时,说明agent启动成功了。
(4)新开一个SSH连接,在该连接中新建一个文件test,随便写点内容,然后将其移动到/root/edisonchou目录中,这时再查看上一个连接中的控制台信息如下,可以发现以下几点信息:
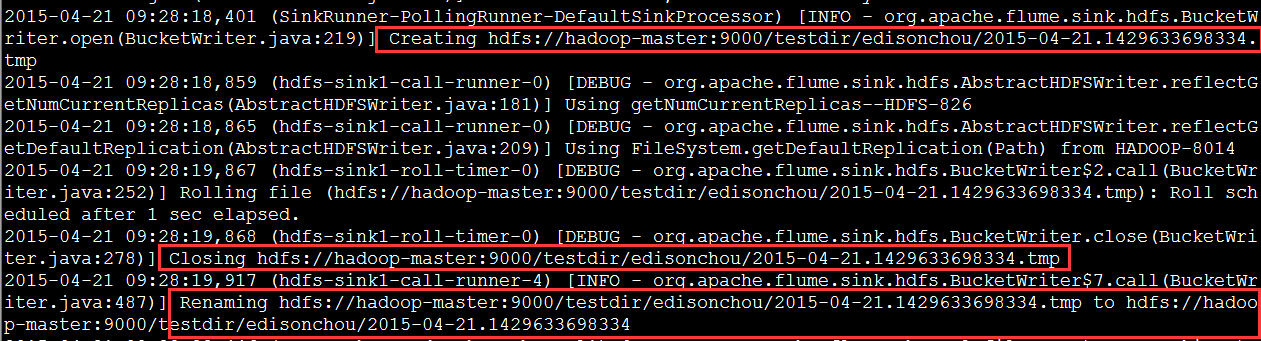
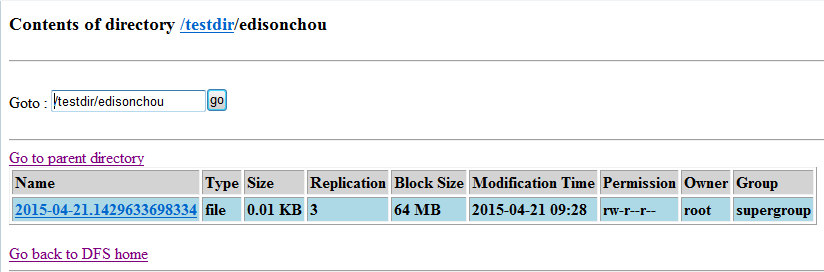
可以发现,当我们向监控目录/root/edisonchou中新增一个文件时,agent立即向HDFS写入了这个文件,其中经历了大概三步:创建、关闭、重命名。在重命名步骤中,主要是将.tmp后缀移除。下图展示了我们向监控目录加入的文件test已经通过agent加入了HDFS中:
参考资料
(1)hanlong,《Flume—开源分布式日志收集系统》:http://www.cnblogs.com/hanganglin/articles/4224928.html
(2)windcarp,《Flume采集处理日志文件》:http://www.cnblogs.com/windcarp/p/3872578.html
(3)我的小人生,《Flume 1.4的介绍及使用》:http://www.cnblogs.com/fuhaots2009/p/3473122.html
(4)残夜,《Flume日志收集》:http://www.cnblogs.com/oubo/archive/2012/05/25/2517751.html
(5)sandyfog,《Flume的概述和简单实例》:http://www.cnblogs.com/sandyfog/p/3795967.html
(6)apache,《flume文档》:http://flume.apache.org/documentation.html