1.目录略览
线程的基本概念:介绍线程的优点,代价,并发编程的模型。如何创建运行java 线程。
线程间通讯的机制:竞态条件与临界区,线程安全和共享资源与不可变性。java内存模型,线程间的通信,java ThreadLocal类,线程信号
死锁相关,资源竞争相关:死锁,如何避免死锁,饥饿和公平,嵌套管程锁死,Slipped conditions(从一个线程检查某一特定条件到该线程操作此条件期间,这个条件已经被其它线程改变,导致第一个线程在该条件上执行了错误的操作),锁,读锁和写锁,重入写死,信号量,阻塞队列,线程池,CAS(compare and swap 理论),同步器,无阻塞算法,阿姆达尔定律(计算处理器平行运算之后效率提升的能力)。
所看的文章链接:
http://ifeve.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B%E6%A8%A1%E5%9E%8B/comment-page-1/#comment-27224
原英文:
http://tutorials.jenkov.com/java-concurrency/index.html
2.内容读感
2.1 java并发性和多线程介绍
单CPU时代,一个时间点只能执行单一的程序,后面即使是到了多任务阶段,计算机的多进程应该属于伪多进程。并不是真正意义上的同时运行,而是由CPU来完成进程调度,按照一定的规则(抢占式,非抢占式)来使每一个任务都有机会获得一定的时间片。这似乎就涉及到了CPU上下文切换,线程运行时的保存,PC寄存器修改等操作过程了。有时间可以写写这里面的过程作为对大学时代的回顾。
随着多任务的发展,程序编写的时候,不能假设是完全占有全部的CPU时间,内存以及其他的资源。一个好的程序应该可以在不需要资源的时候,主动释放,以便其他的程序可以使用。
后来到了多线程技术,一个程序内部可以有多个线程并发执行。一个线程的执行可以看作是一个CPU在执行这个程序,当一个程序中多个线程都被执行时,就好像多个CPU在同时执行该程序。
多线程比多任务更挑战,多线程是在一个程序内部并行执行的,会对相同的内存空间进行并发读写操作。这样如果是多个CPU的话,就会有出现相同这些问题。
java 多线程和并发性
java是最先支持多线程的开发的语言之一,由于多线程中出现的问题和多任务以及分布式系统中出现的存在类似,也会参考多任务和分布式系统的,所以统称为了”并发性”。
2.2 优点
1.资源利用率
2.程序设计在某些情况下更加简单
3.程序响应更快
2.2.1 资源利用率
由于CPU比一些其他的处理要快很多,比如CPU在等待磁盘读取的时候,CPU是空闲的,这个时候CPU可以进行其他的处理,通常情况下CPU和内存IO比网络和磁盘的要快的多。
举的栗子:


but : 疑问来了: 肿么实现这里面的读取A的时候 同时处理B了?
第一种方式就是按照读取同一个文件来处理的,第二种是否应该考虑在读文件的时候加一个阻塞,然后读完了以后才会唤醒,这期间CPU就可以进行其他的处理,比如处理A文件。嗯,觉得应该是这样的,但是这里具体使用java的类还未知,编程 的实现还未知,可以往后看了,觉得后面应该有答案。
2.2.2 程序设计更简单
单线程程序中如果要实现上面的读取和处理的顺序,必须要记录每个文件读取和处理的状态。而多线程的话,可以启动两个线程,每个线程负责一个文件的读取,当第二个线程读取的时候会被阻塞,这个时候其他的线程可以使用CPU来处理已经读取完成的文件,这种方式又和我上面写的那个方式有些不同,具体哪种好,还需要比较才可知。
2.2.3 程序响应更快
再来个栗子:


第一个是单线程的监听,有请求后,就直接进行处理,其中新的请求无法被服务器端接受。
第二个是监听到请求后,就将该请求传递给了工作者线程,然后立刻返回监听,由工作者线程来处理请求并且进行返回。
桌面应用也是一样的模式:当点击了一个耗时的任务时,这个线程既要执行任务又要更新窗口和按钮,在任务 执行过程中,这个应用程序看起来如同没有反应一样。反之,任务可以传递给工作者线程。工作者来处理任务,而窗口线程继续响应用户的请求。工作者完成后,发送信号给窗口线程。 嗯 这个过程就涉及到了信号的问题。— 线程间的通讯了。
2.3 多线程的代价
从单线程应用到多线程的应用也会需要一些代价,需要在获得的好处和付出的代价之间进行衡量,如果存在疑问的时候 需要尝试测量应用程序的性能和响应能力,而不是猜测。----这里应该如何进行性能测试? 两个程序都部署在相同的机器上来测QPS响应时间等性能么。
2.3.1设计更复杂
当多线程访问共享数据的时候,代码需要特别注意。线程之间的交互十分复杂,不正确的同步容易产生难以发现的错误。 ---- 不知道这里的线程间的同步是指的什么? 线程间通讯了还是指内存数据的访问以及设定。
2.3.2上下文切换的开销
上下文切换:CPU从执行一个线程切换到另外一个线程的时候,需要先存储当前线程的本地数据,比如PC寄存器的值,然后载入另外一个线程的本地数据,最后开始执行。上下文切换的相关概念可以见:
2.3.3 增加资源消耗
线程在运行时会从计算机中等到一些资源,除了CPU还有内存等等。也需要占用操作系统的资源来管理线程。觉得还是贴代码吧。但是这个运行了不太会看占用的性能,只看到了CPU确实快到100%了。
package javaTest;
publicclass MultiThread {
publicstaticvoid main(String[] args){
for(inti = 0; i < 100; i++ ){
new Thread(new Runnable(){
publicvoid run(){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("finished ");
}}).start();
}
System.out.println("main here ");
}
}
启1000个线程的时候,可以看到占用70M的内存,2000的时候 占用90M,3000的时候 直接报错,outofMemory。
3.并发编程模型
并发系统可以用多种并发编程模型实现。并发模型指定了系统中的线程如何通过协作来完成分配的任务。不同的并发模型采用不同的方式来拆分作业,同时线程间的协作和交互方式也不同。
3.1 并发模型与分布式系统之间的相似性
在并发系统中线程之间可以相互通信。而分布式系统中进程之间也可以相互通信。线程和进程有很多相似的特性。分布式系统可能面临处理网络失效,远程主机或者进程宕机的问题,不过巨型服务器上的并发系统也可能遇到相似的问题,如CPU失效,网卡失效或者磁盘损坏。
有些思想可以相互借鉴的,比如负载均衡和分配作业的模型。在日志 记录,失效转移,幂等性等错误上也有相似的。
3.2 并行工作者

委派者将传入的工作分配给不同的工作者,每个工作者负责完整的任务。工作者可以运行在不同的线程上,甚至是不同的CPU上(在想java怎么控制多CPU的多线程的,需要在哪设置参数么。)这是最常见的并发模型,我之前工作的项目实现就是用这个模型来处理。java.util.concurrent 包里面许多并发实用工具是设计用于这个模型的。
3.2.1 并发工作者模型的优点
容易理解。只需要添加更多的工作者来提高系统的并行性。
可以写个爬虫程序,然后调试用多少个线程可以实现效率最好。因为爬虫程序是一个网络IO密集型的工作。如果是单线程,CPU可能会处于长期等待时间。—— 怎么判断需要多少的线程数 也是一个问题。
3.2.2 并行工作者模式的缺点
3.2.2.1 共享状态可能会复杂
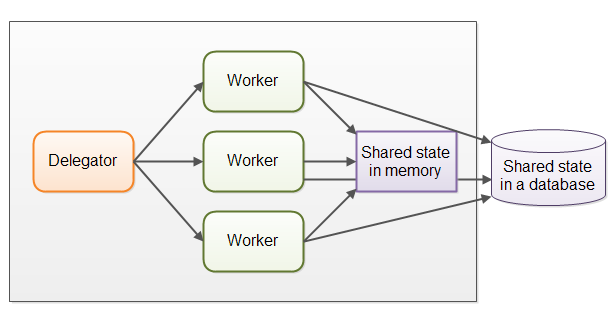
并行工作者模型中会存在共享数据的问题,从共享内存到共享数据库数据。也还有共享状态这么一说。共享状态是指的业务数据,数据缓存,数据库连接池等.
线程需要以某种方式来存取共享数据,来保证这个数据的修改对其他的线程是可见的(数据的修改需要同步到主存中,而不仅仅保存在这个线程的CPU缓存中 ——问题来了: 每个线程的内存模型是怎么样的,占用的CPU缓存是在CPU的什么地方?)。线程需要避免竟态,死锁以及很多其他共享状态的并发性问题。
在等待访问共享数据的时候,线程之间相互的等待会丢失部分的并行性。许多并发数据结构是阻塞的,高竞争会导致一定程度的串行化。
非阻塞并发算法可以降低竞争并提升性能,但是实现比较困难。
可持久化数据结构是另外一种选择。修改的时候,前一个版本不收影响,如果一个线程修改了数据,修改的线程会得到一个新结构的指向,而其他线程仍然是引用旧的结构。旧结构没有被修改可以保持一致性。Scala编程中包含了几个持久化的数据结构。
可持久化数据结构是指像RDD的数据类型,不是指持久化存储。也比如Java中的String,CopyOnWriteArrayList类。参考
但是由于涉及到链表实现,表现不太好。。为啥不好 我也不知道。但是可以考虑用数组来实现,顺序读取数据.
3.2.2.2 无状态的工作者
由于使用的是共享状态,其他线程都可以修改,工作者每次需要重读状态,以确保每次都能访问到最新的副本。工作者无法在内部保存这个状态在需要的时候要重新读取成为无状态。
重新读取数据会导致速度变慢。 — 不知道这个重新读取状态的操作是自行实现么? 我估计应该是。但是要怎么控制,莫不是加上了事物控制,也许是CPU自己控制的?
3.2.2.3 任务顺序是不确定的
无法保证哪个作业是最先或者最后执行的,导致很难在特定的时间点推断系统的状态。也很难保证一个作业在另外一个作业之前执行。
3.3 流水线模式
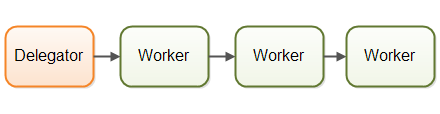
流水线并发模型,每个工作者完成作业中的部分工作。完成了自己这部分工作的时候就会将作业装发给下一个工作者。每个工作者在自己的线程中运行,不会和其他工作者共享状态。
通常使用非阻塞IO来设计流水线并发模型的系统。非阻塞IO可以用来设定工作者之间的边界。工作者会尽可能的多运行知道遇到并启动一个IO操作。然后交出作业的控制权。当IO操作完成时,下一个工作者继续,直到它也碰到并启动一个IO操作。—— 如果可以在网上找到这些实践的例子才是极好的。

由于实际应用中,作业不会沿着单一流水线运行,大多数系统会有多个作业,所以应该是这样的:
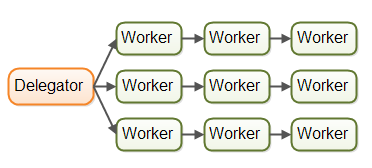
作业可以被转发到一个工作者上并发处理,比如作业可能同时转发到作业执行器和作业日志器。——疑惑在 这个任务是怎么转发的????
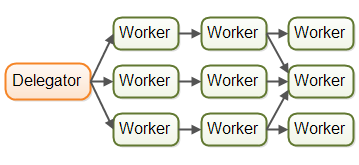
当然有可能会有更复杂的。
3.3.1 反应器,事件驱动系统
采用流水线并发模型的系统有时候也称为反应器系统或事件驱动系统。系统内的工作者对系统内出现的事件做出反应,这些事件也有可能来自于外部世界或者发自其他工作者。事件可以是HTTP或者文件成功加载在内存中了 — 怎么知道文件是否成功加载到内存中的
目前的反应器/事件驱动平台:
Akka
Node.JS
栗子来了,应该是这些平台的实现可以看看
3.3.1 Actor 和 Channels
他们是两种比较类似的流水线模型。
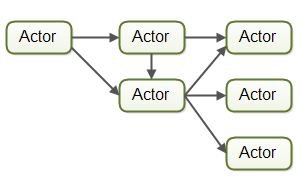
Actor 模型中每个工作者被成为actor.Actor 之间可以直接异步发送和处理消息。Actor可以被用来实现一个或者多个作业处理流水线。根据这个名字,没节操的觉得这个才是之前采用的模式。
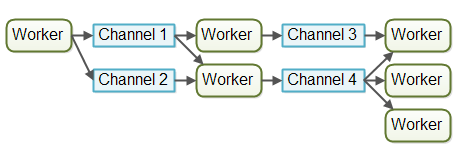
Channel 模型中工作者之间不直接进行通信,它们在不同的通道中发布自己的消息,其他的工作者可以在通道上监听消息,发送者无需知道谁在监听。更加灵活并且松散。
3.4 流水线模型的优点
3.4.1 无需共享状态
可以不用考虑并发访问共享对象产生的并发性问题。
3.4.2 有状态的工作者
由于无共享状态,可以在内存中保存他们的操作数据,会有更高的性能。
3.4.3 较好的硬件整合(mechanical sympathy)
方便像单线程编码一样的思考。
3.4.4 合理的作业顺序
可以保证作业的顺序,更进异步可以将所有到达的作业写入到日志中,该日志可以用来重头开始重建系统当时的状态。在保证了作业的顺序后,就可以根据日志文件来处理备份,数据恢复,数据复制等工作了。
3.5 流水线模型的缺点
作业的执行往往分布到多个作业者上,对于执行者的确定比较难,有时作业者的代码是写成回掉处理,如果嵌套过多会出现所谓的回调地狱现象。追踪比较困难。 —— 找一个实现了流水线模型的代码看看吧。
3.6 函数式并发(Functional Parallelism)
函数式并发的基本思想:采用函数调用实现程序。函数可以看为“代理人”(agent)或者”actor”,函数之间也可以互相发送消息。
"函数都是通过拷贝来传递参数的,所以除了接收函数外没有实体可以操作数据。这对于避免共享数据的竞态来说是很有必要的。同样也使得函数的执行类似于原子操作。每个函数调用的执行独立于任何其他函数的调用。” 要去理解下函数式并发的概念才能理解吧。
Java 7 中的 java.util.concurrent 中的 ForkAndJoinPool可以帮助实现。还有java8中的 streams