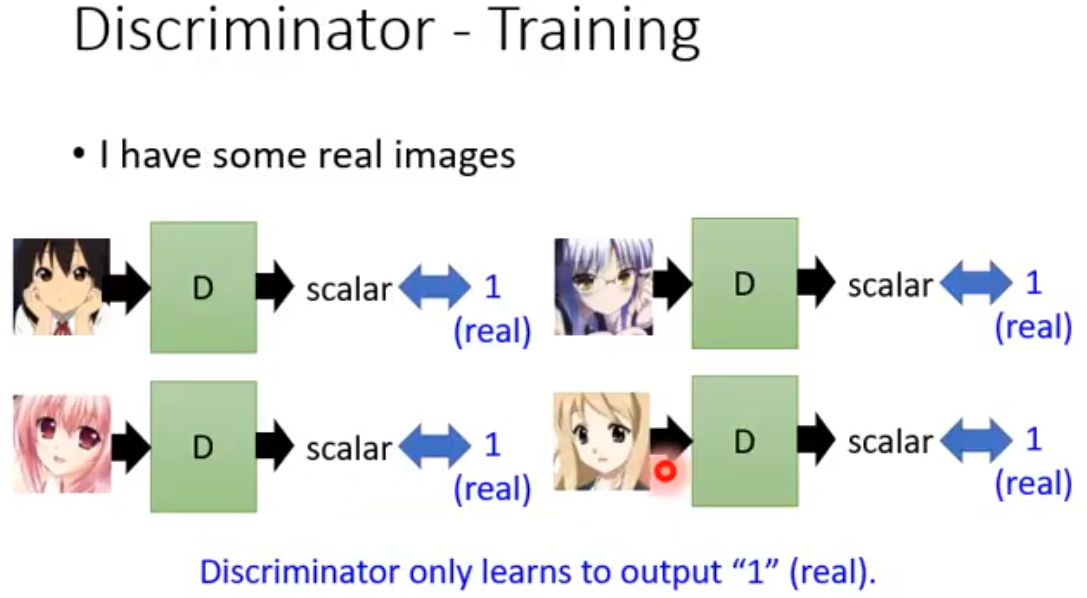


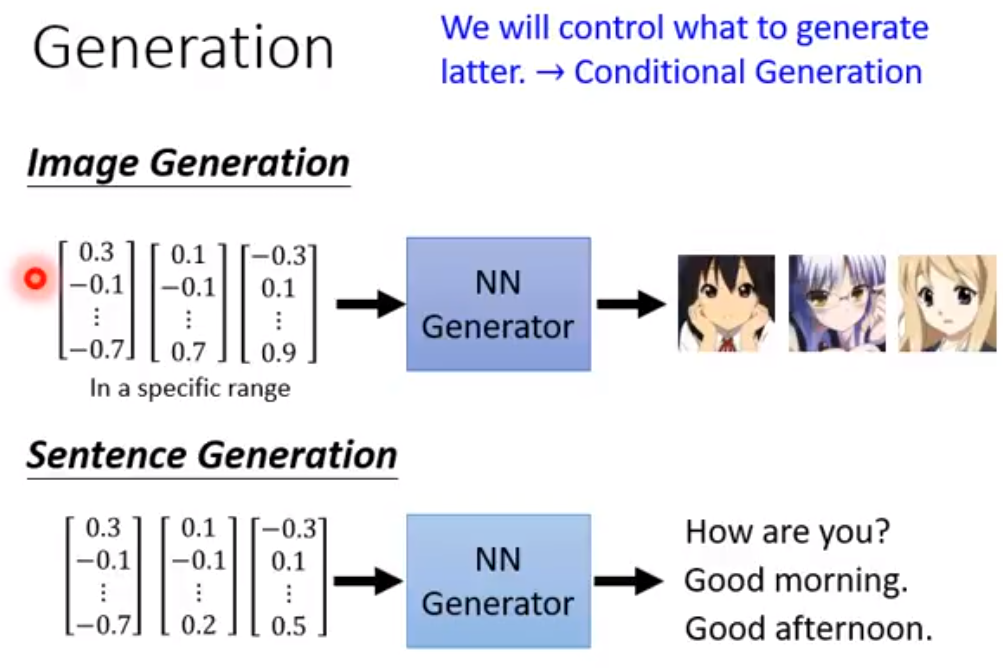
比较有用的是conditioned generator,能够控制输入的vector来控制对应的文字音像
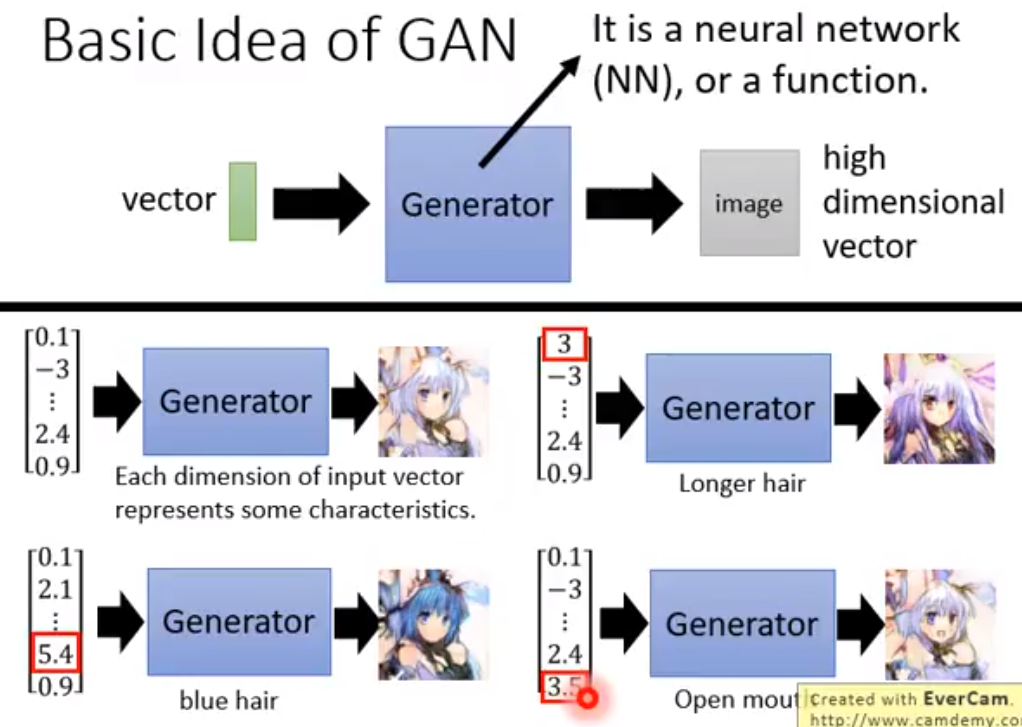
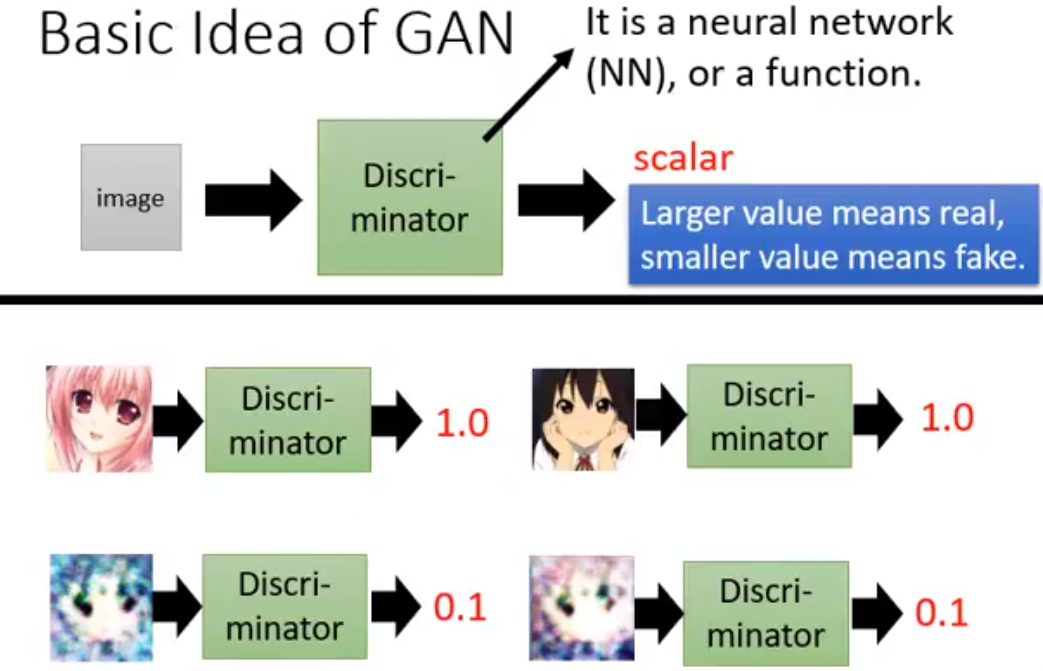
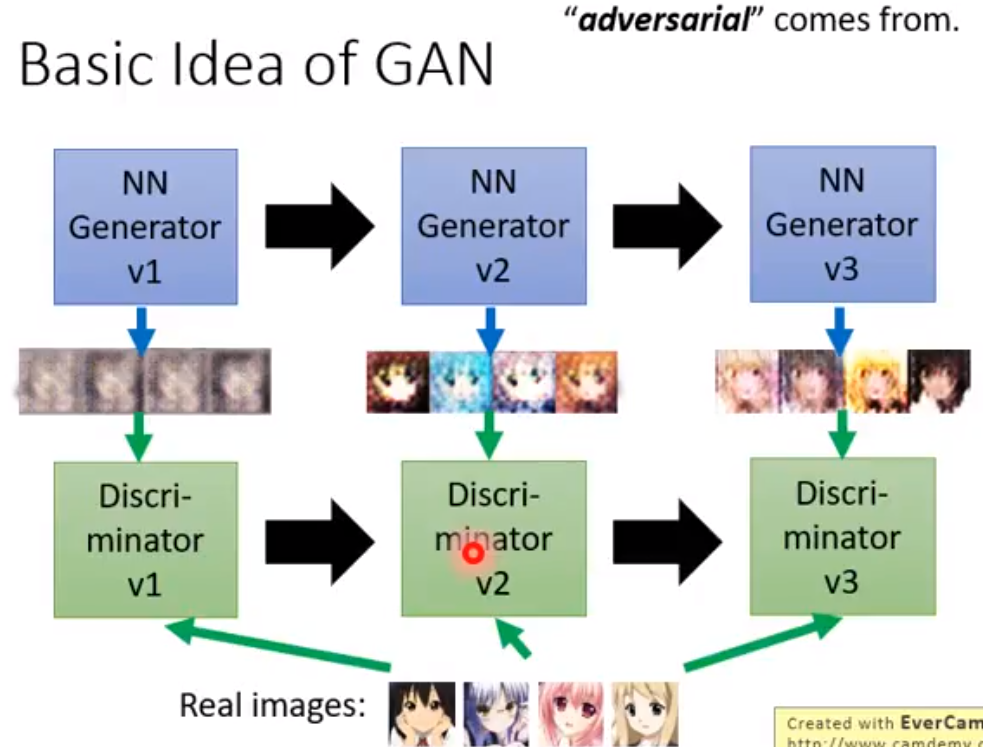
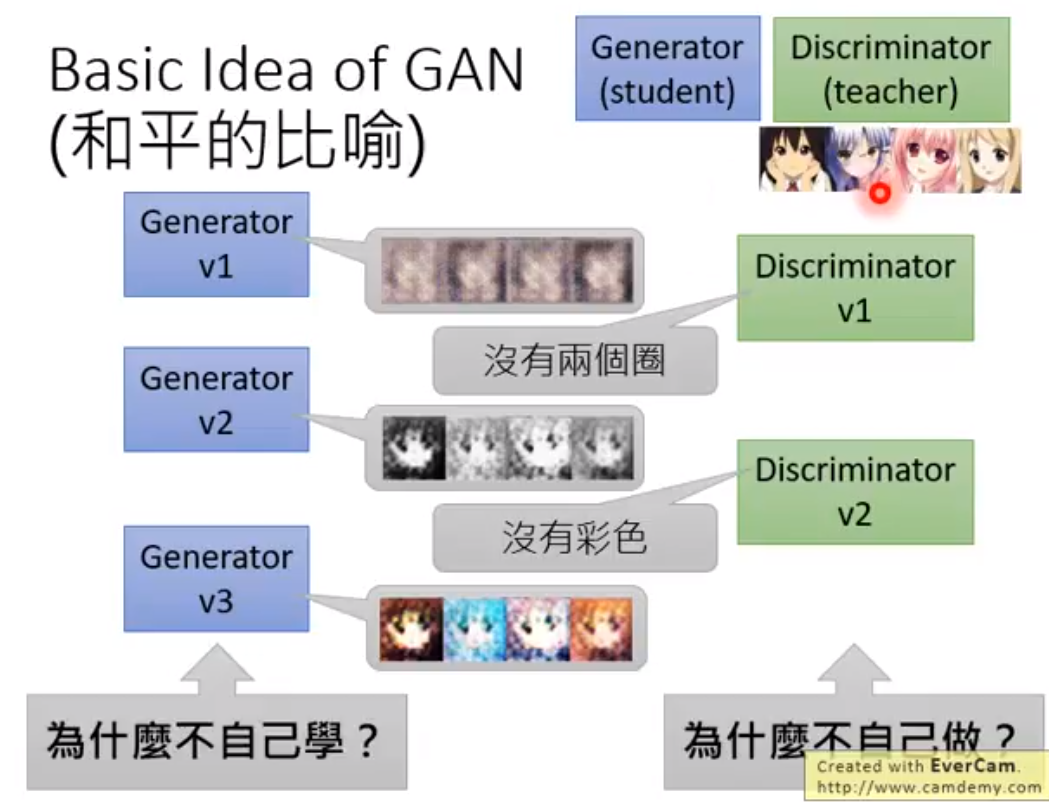

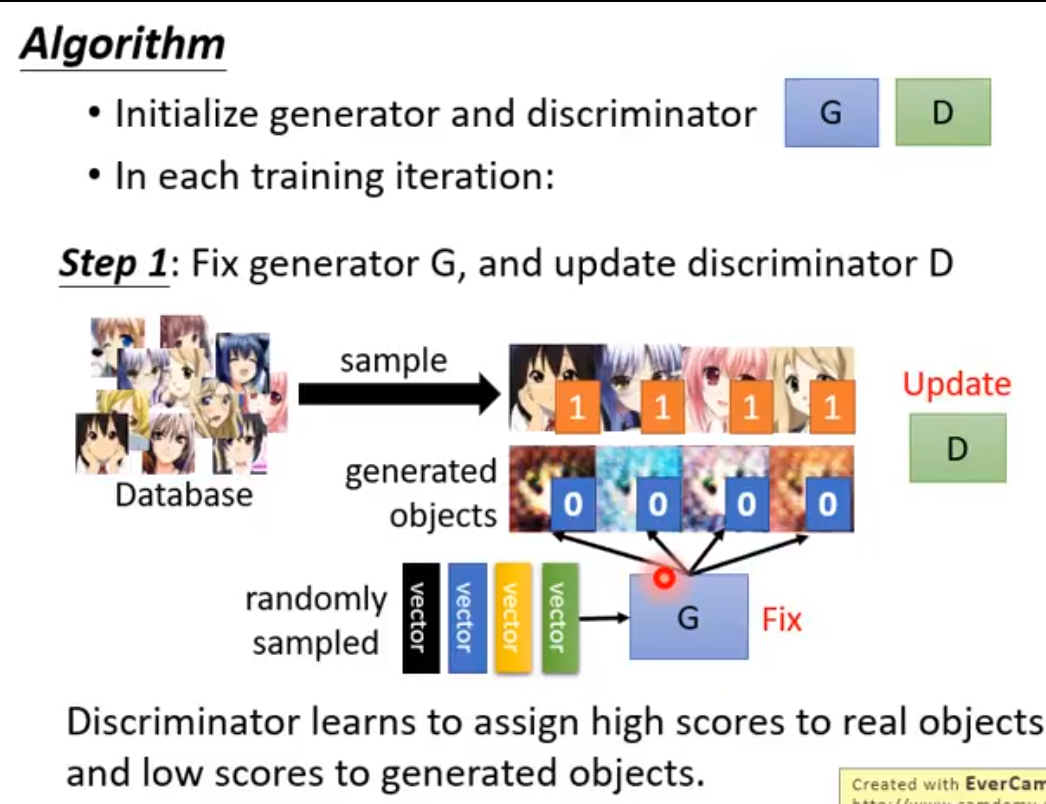
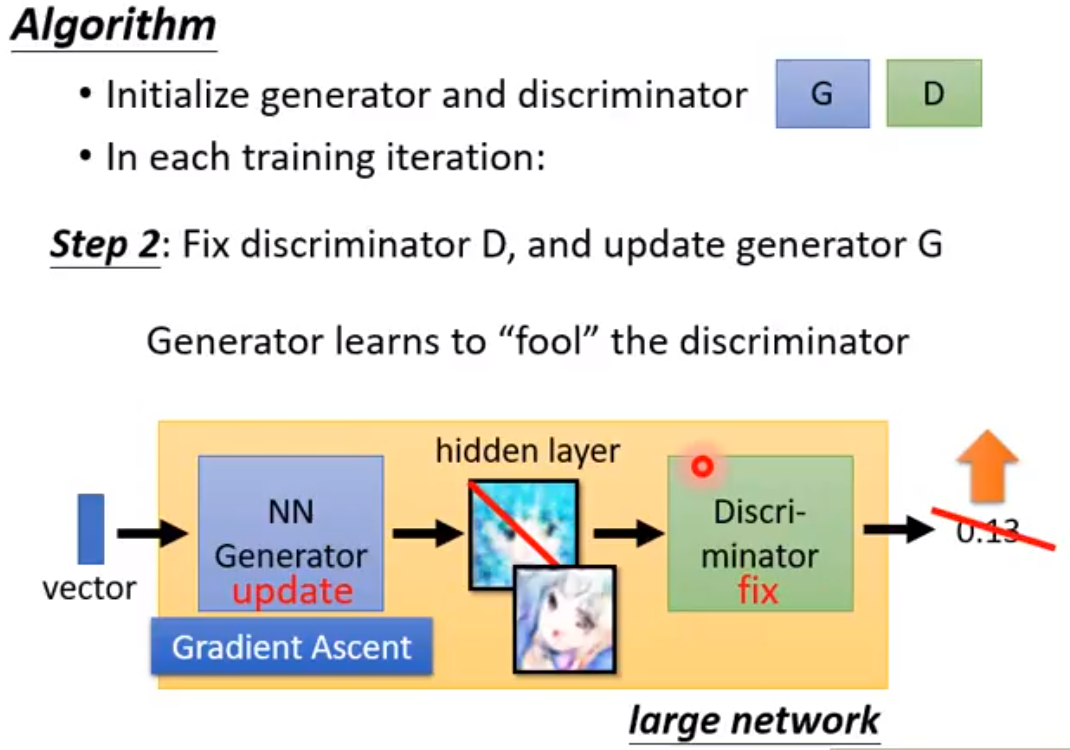


https://zhuanlan.zhihu.com/p/24767059



单纯生成人脸意义不大,因为随便拍一个路人就行了。
但是能从左右照片生成正面照片,就很神奇了





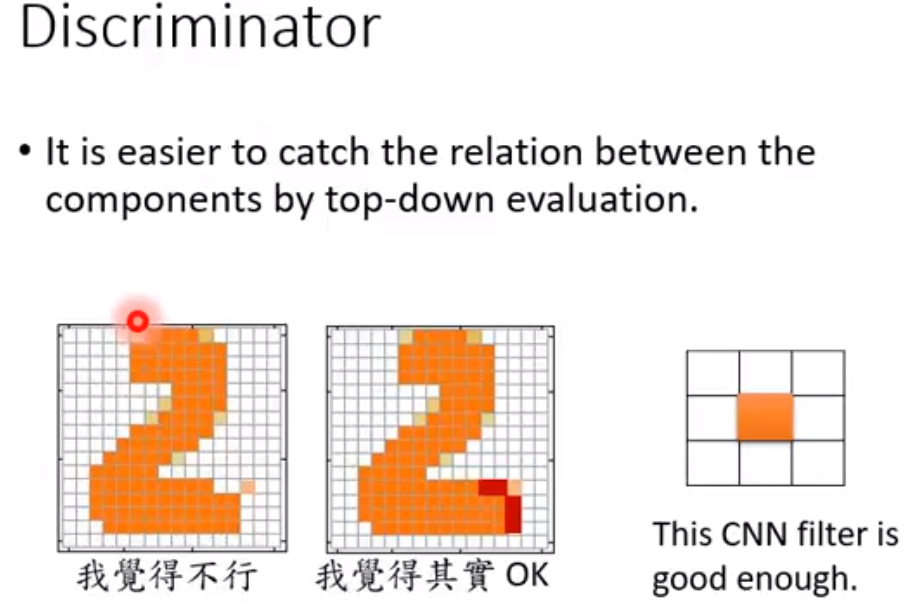
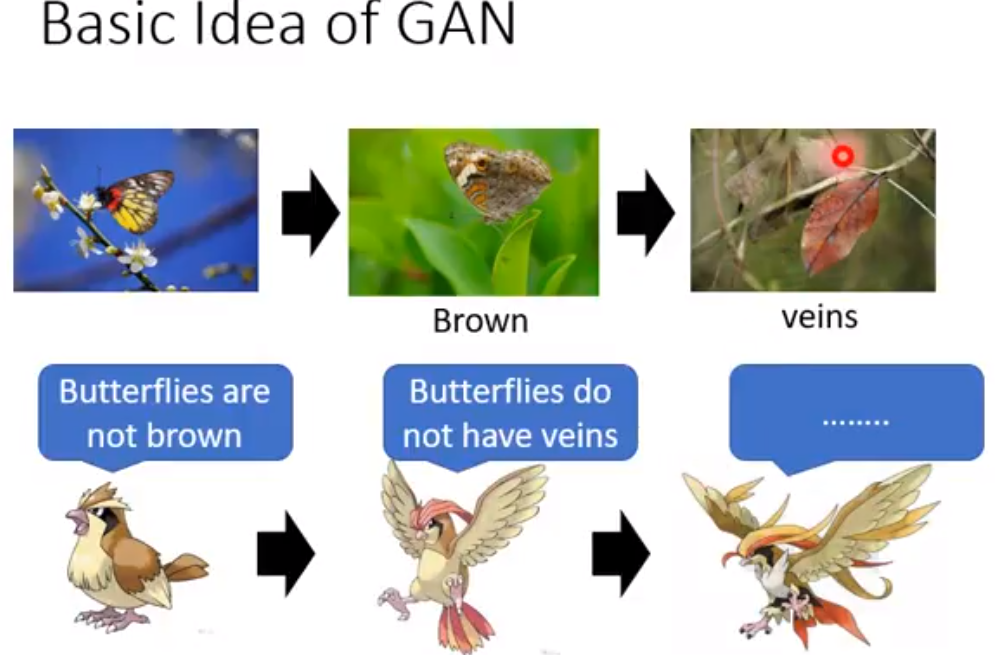
必须学会辨别转折
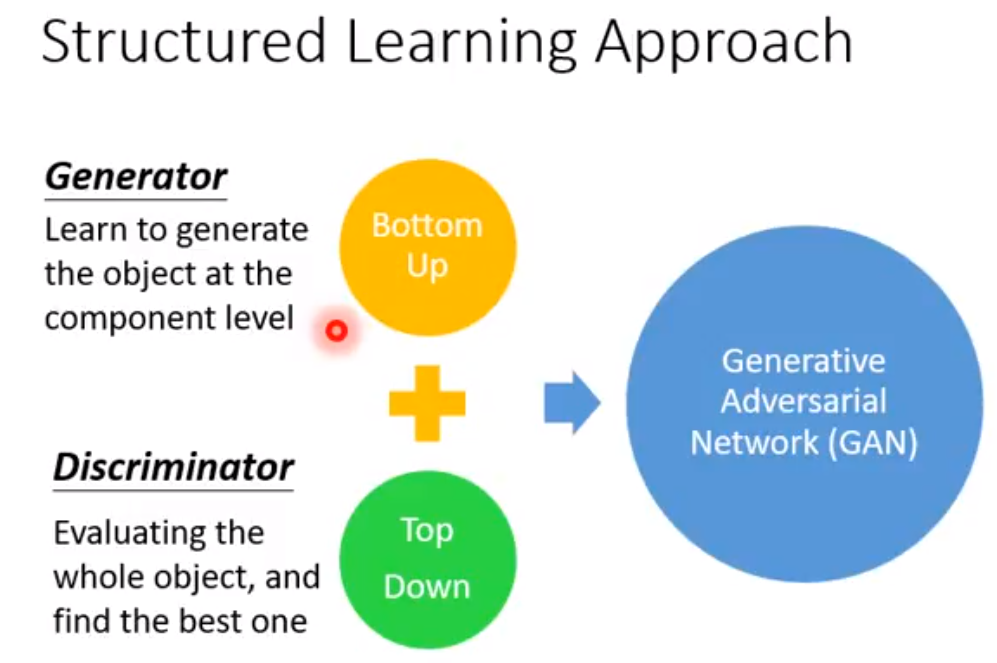
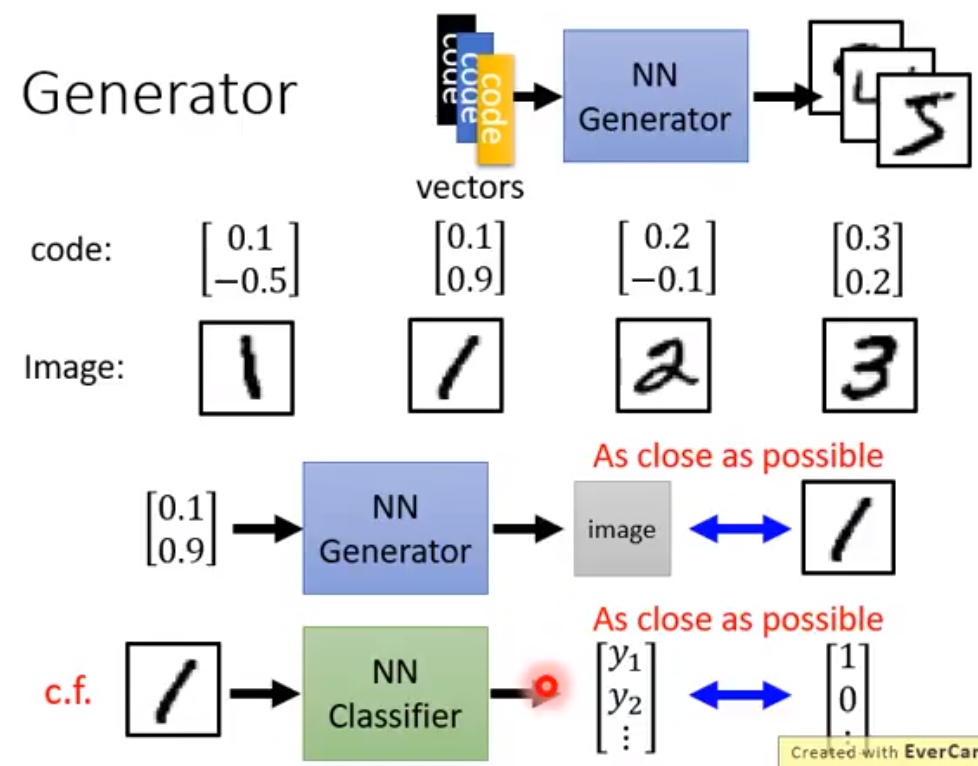

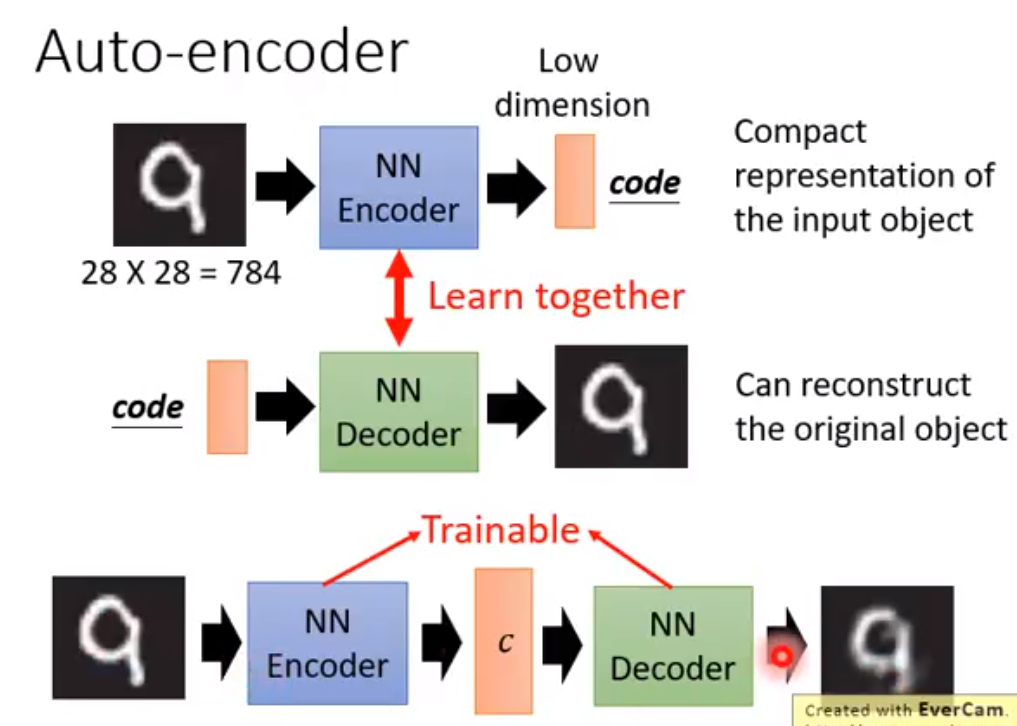

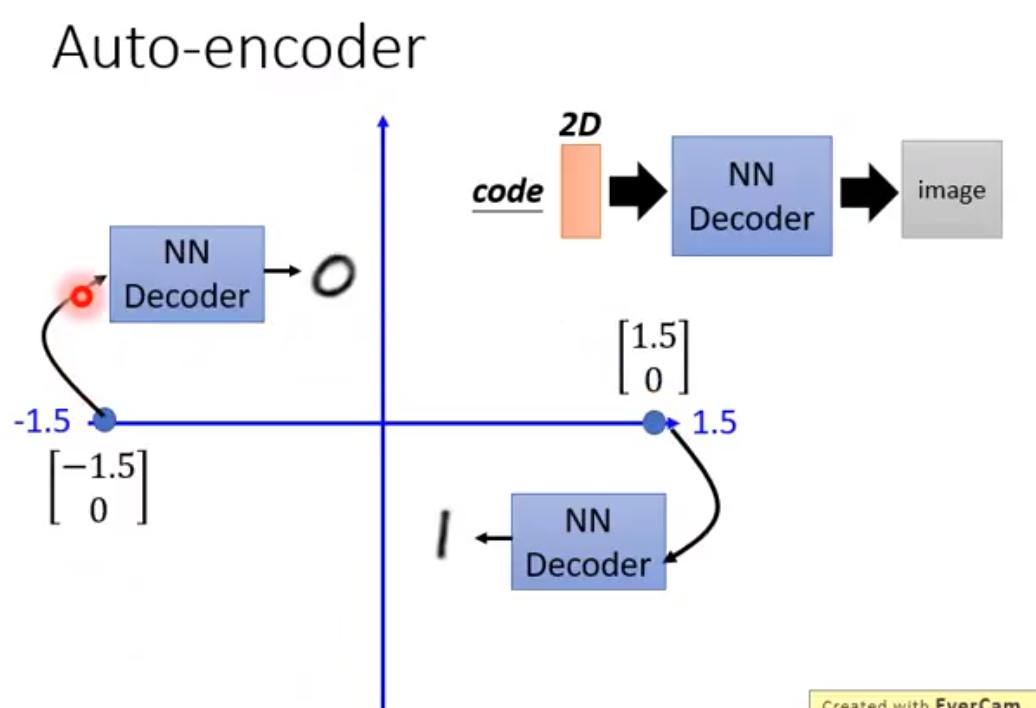
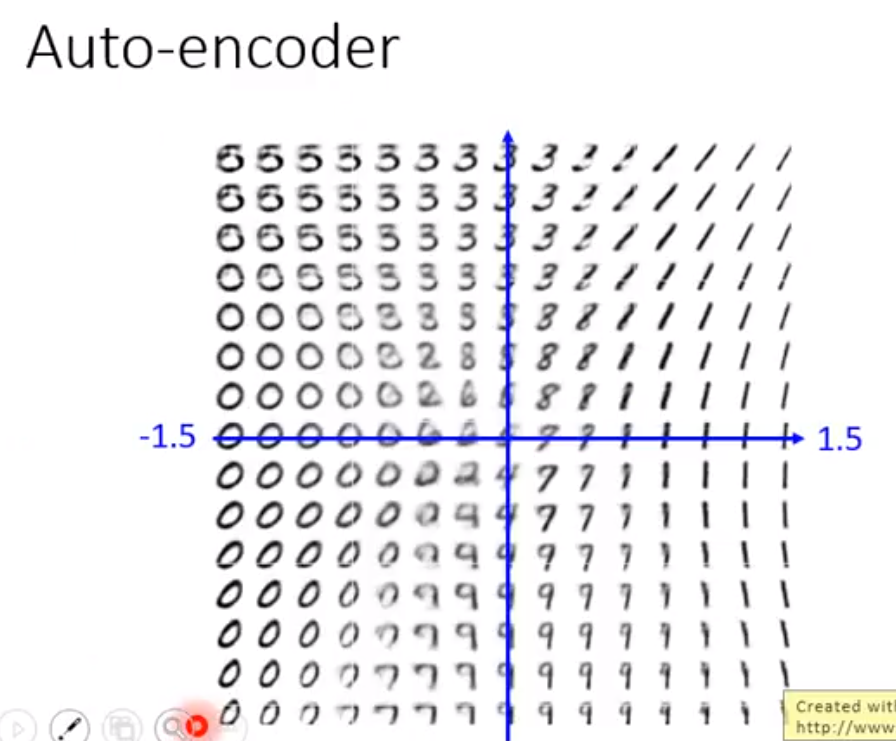
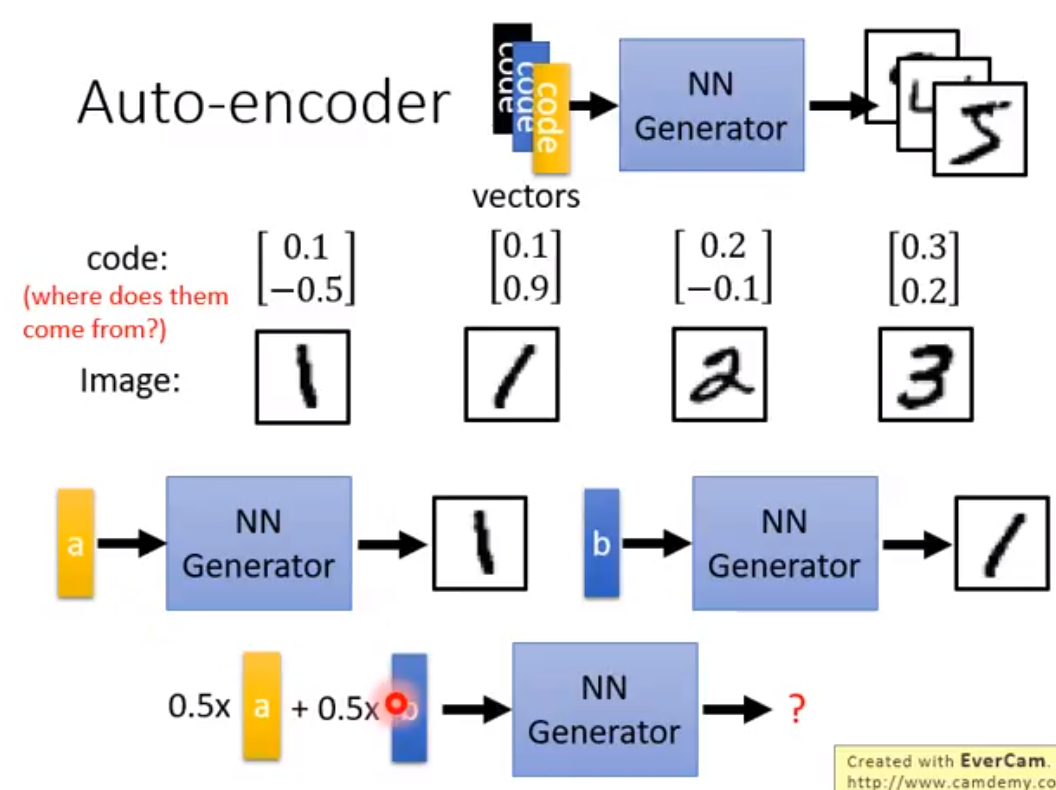

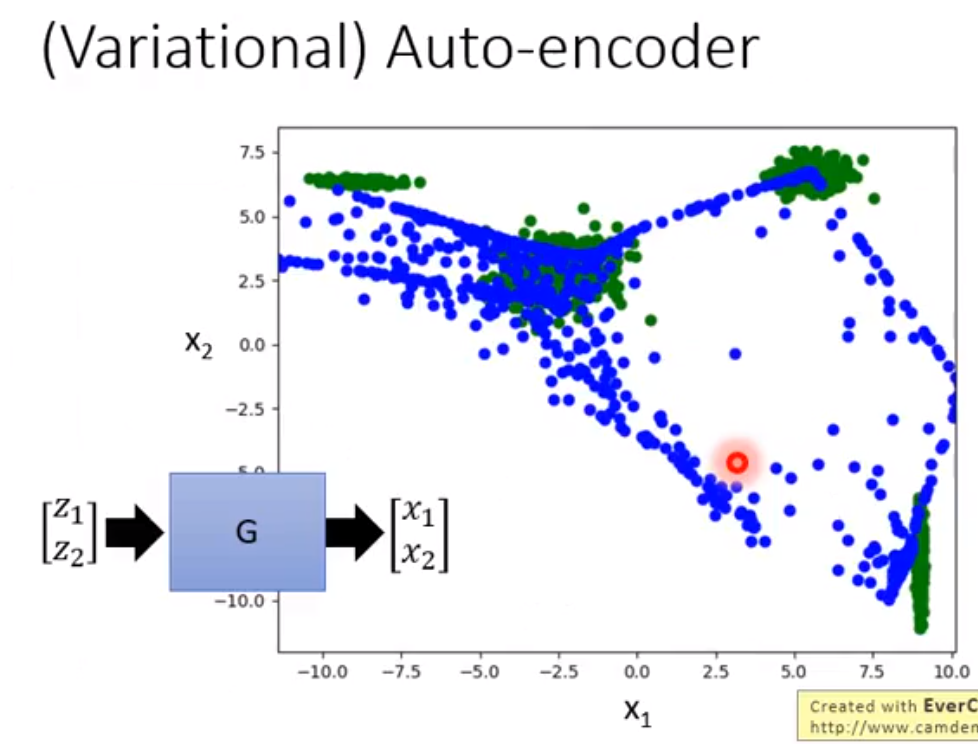
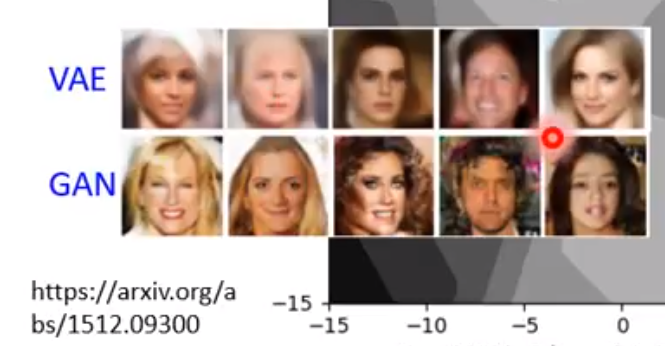
Variational Auto Encoder 可以把decoder train地更加稳定,可以在输入的vector不在训练集里的时候,也能输出一些合理的结果。


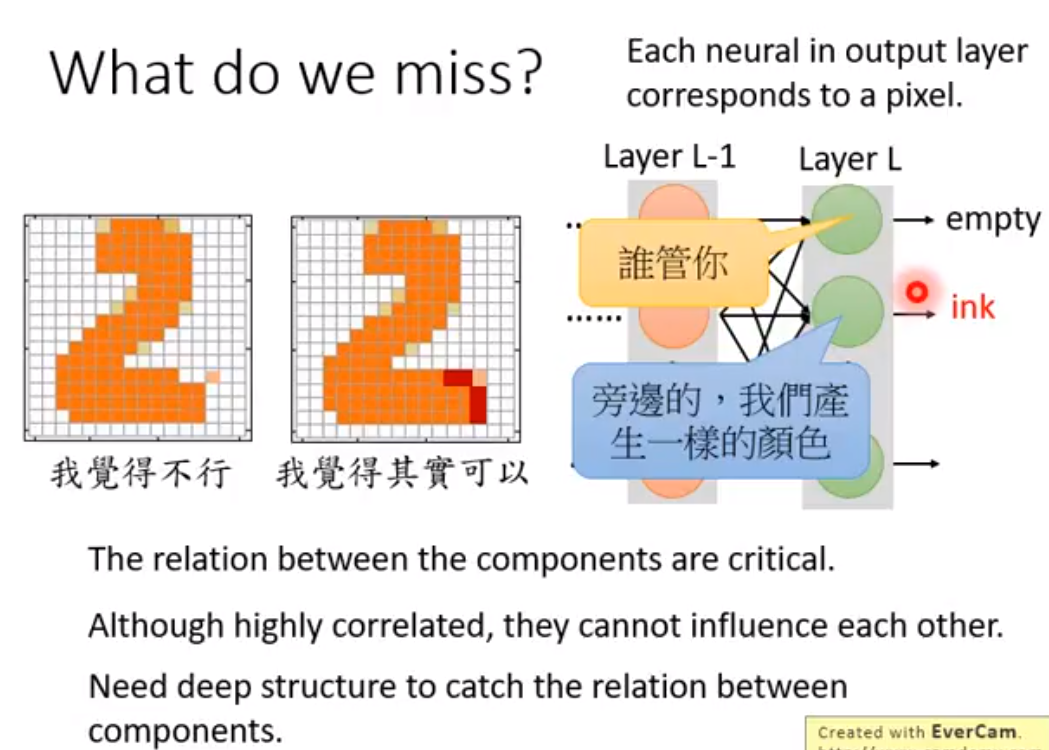
但是不行,因为输出的pixel之间没有互相联系,但是如果多加几个hidden layer就可以了。所以如果把VAE加了更多的层能产生和GAN接近的结果