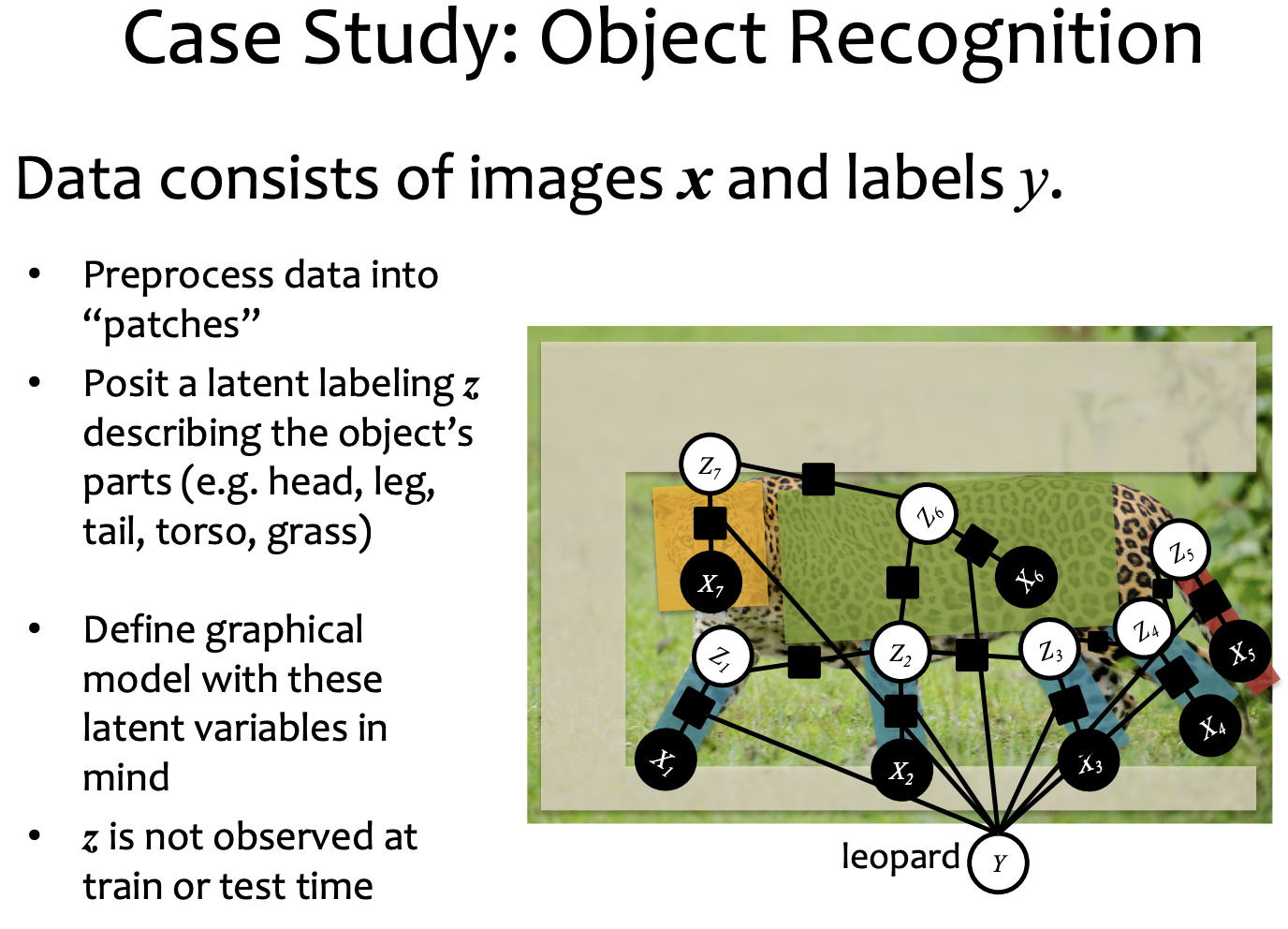
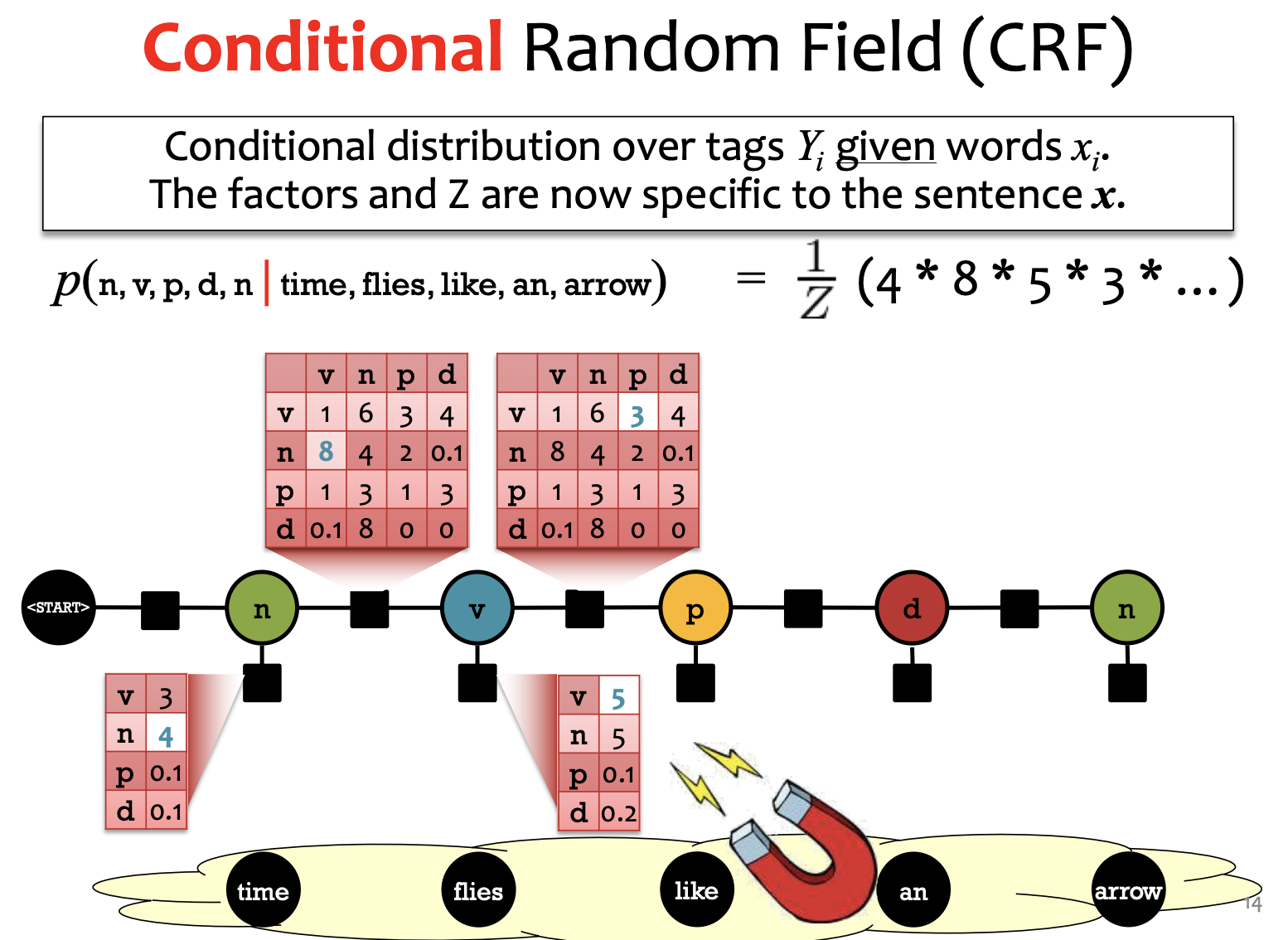
between tags and words, there's table 1.
between tags, there's table 2.
combine the two tables, p(...) to get the results.
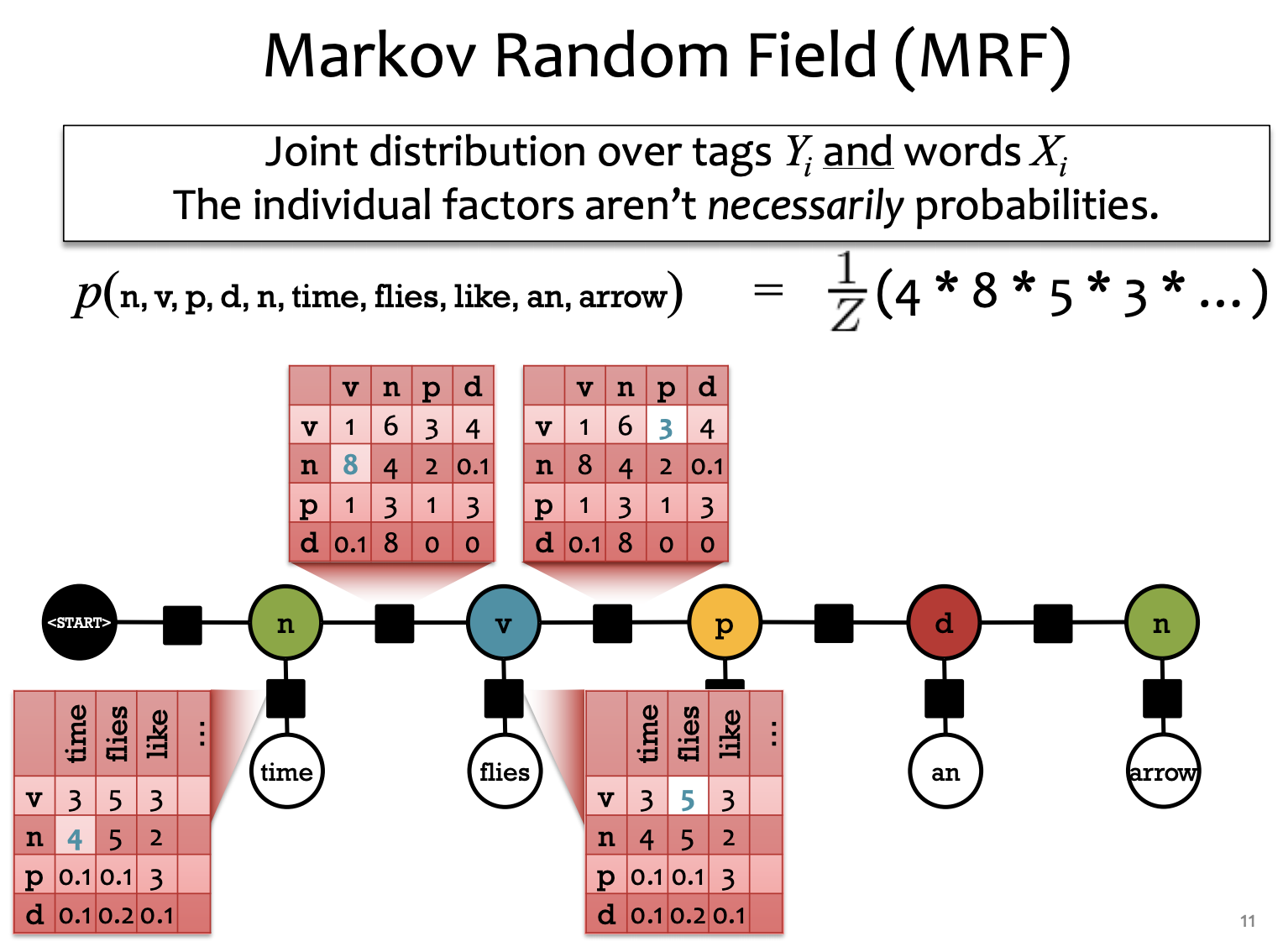
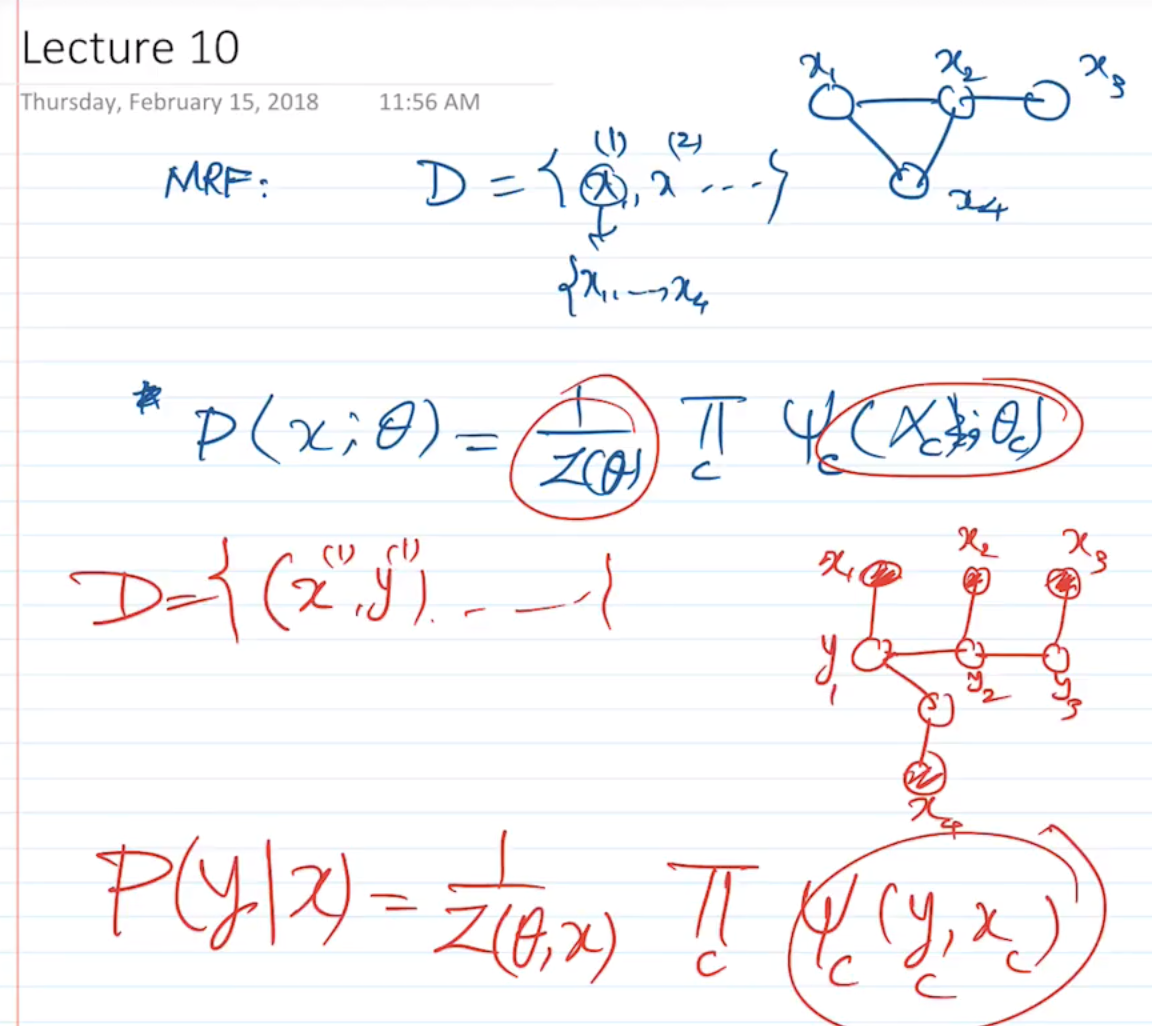
MRF: factors of the tables not necessarily probabilities
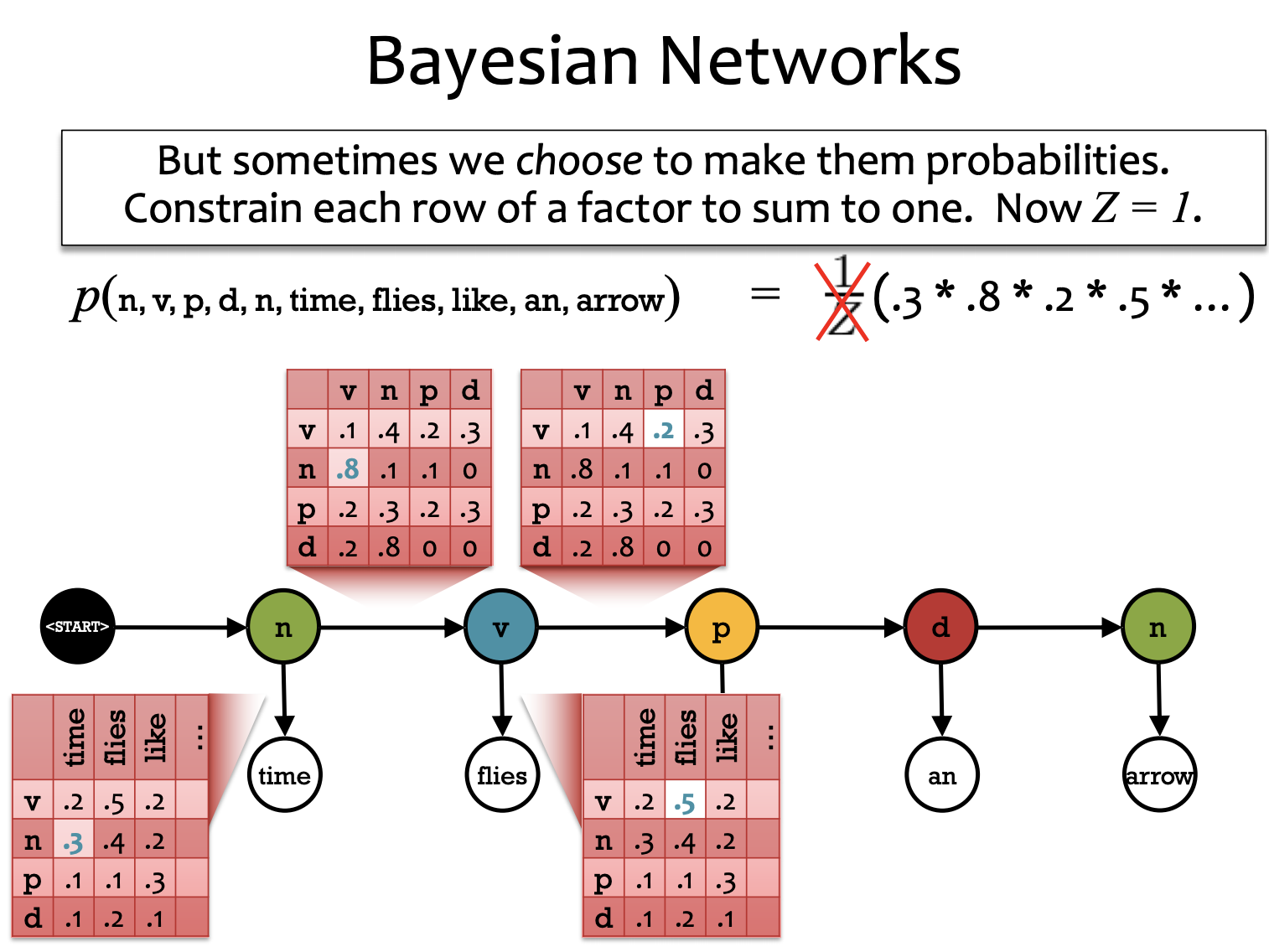
BN: must be probabilities. => BN is easier to learn than MRF


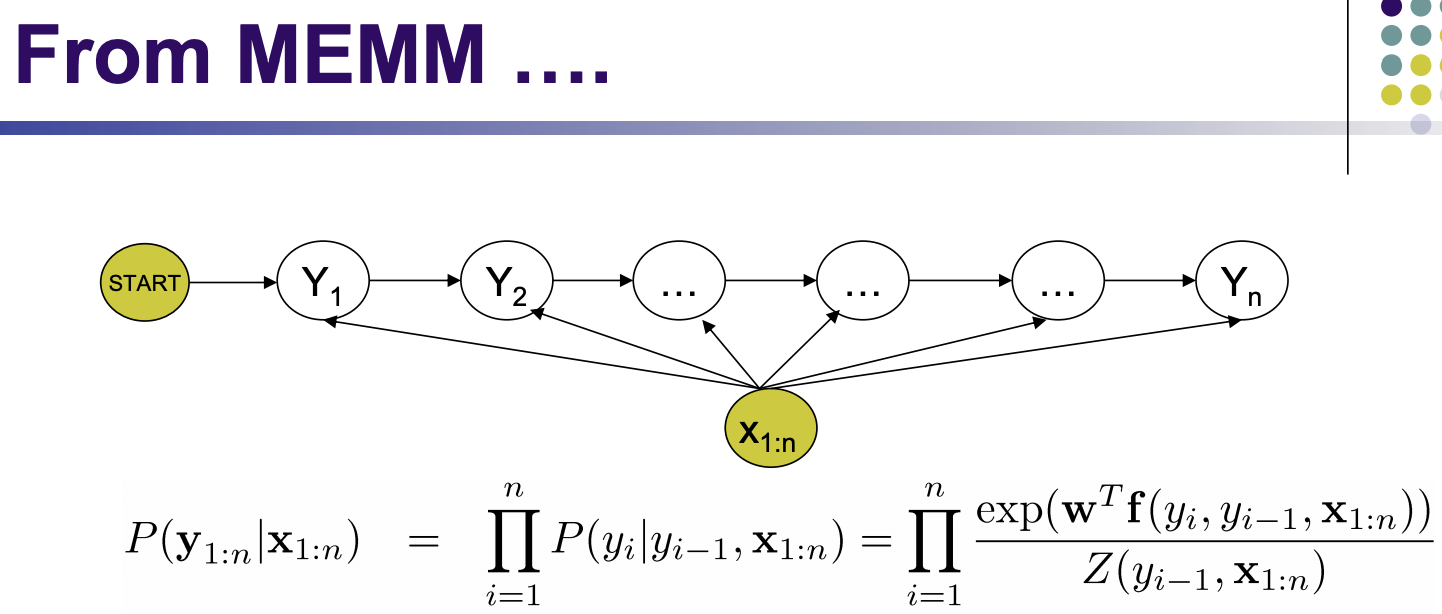
Maximum-Entropy Markov Model (MEMM)

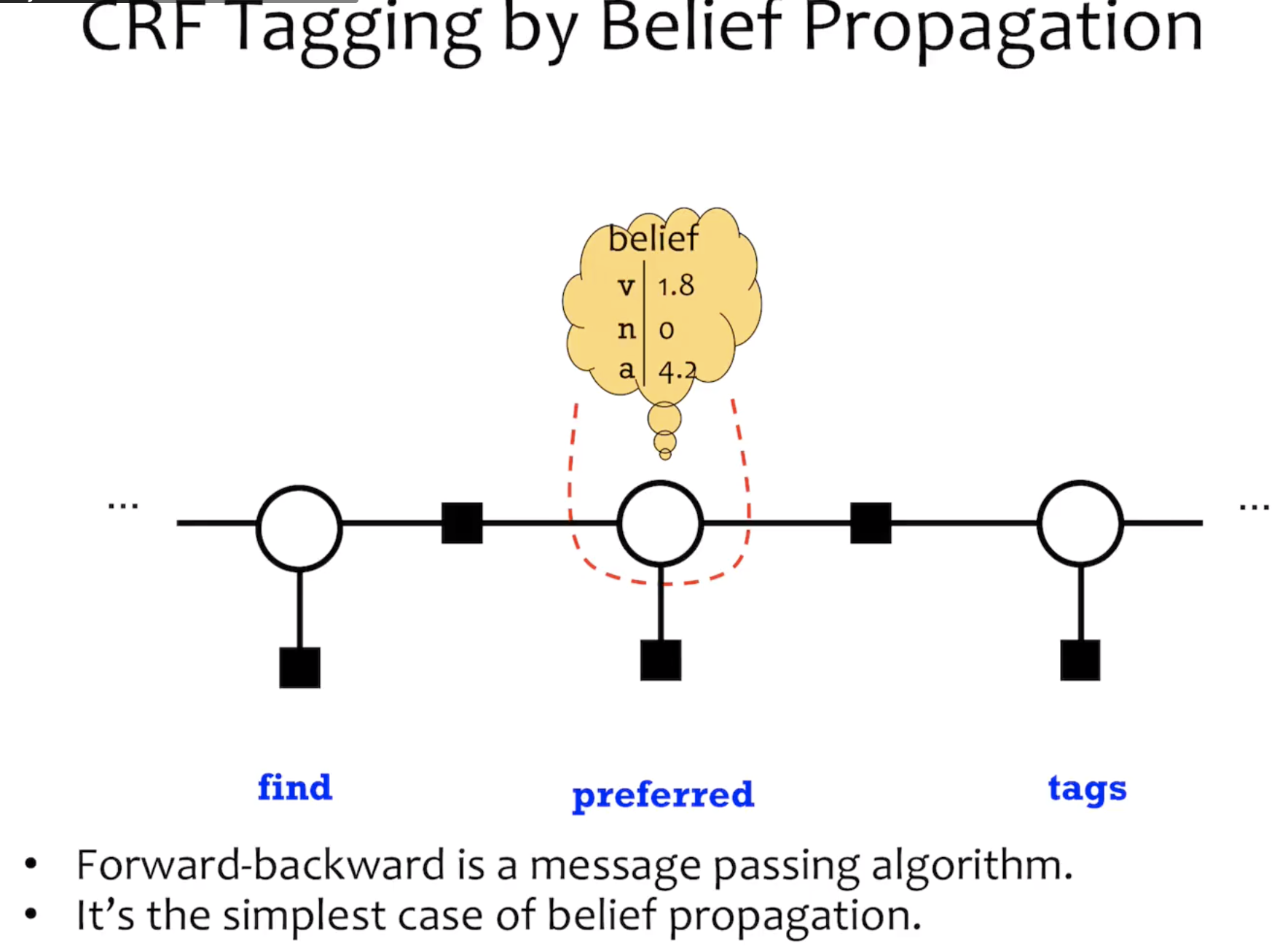


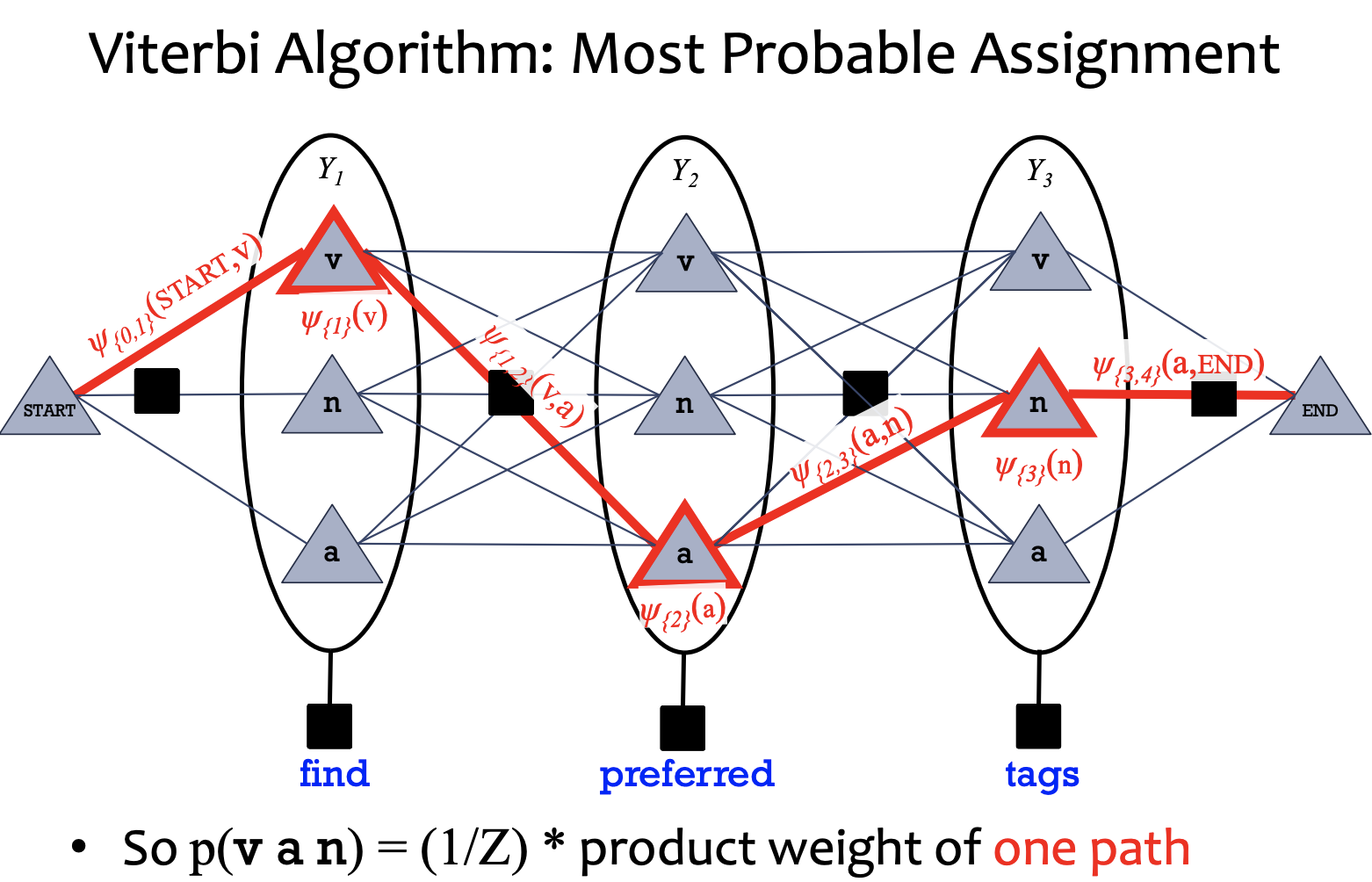
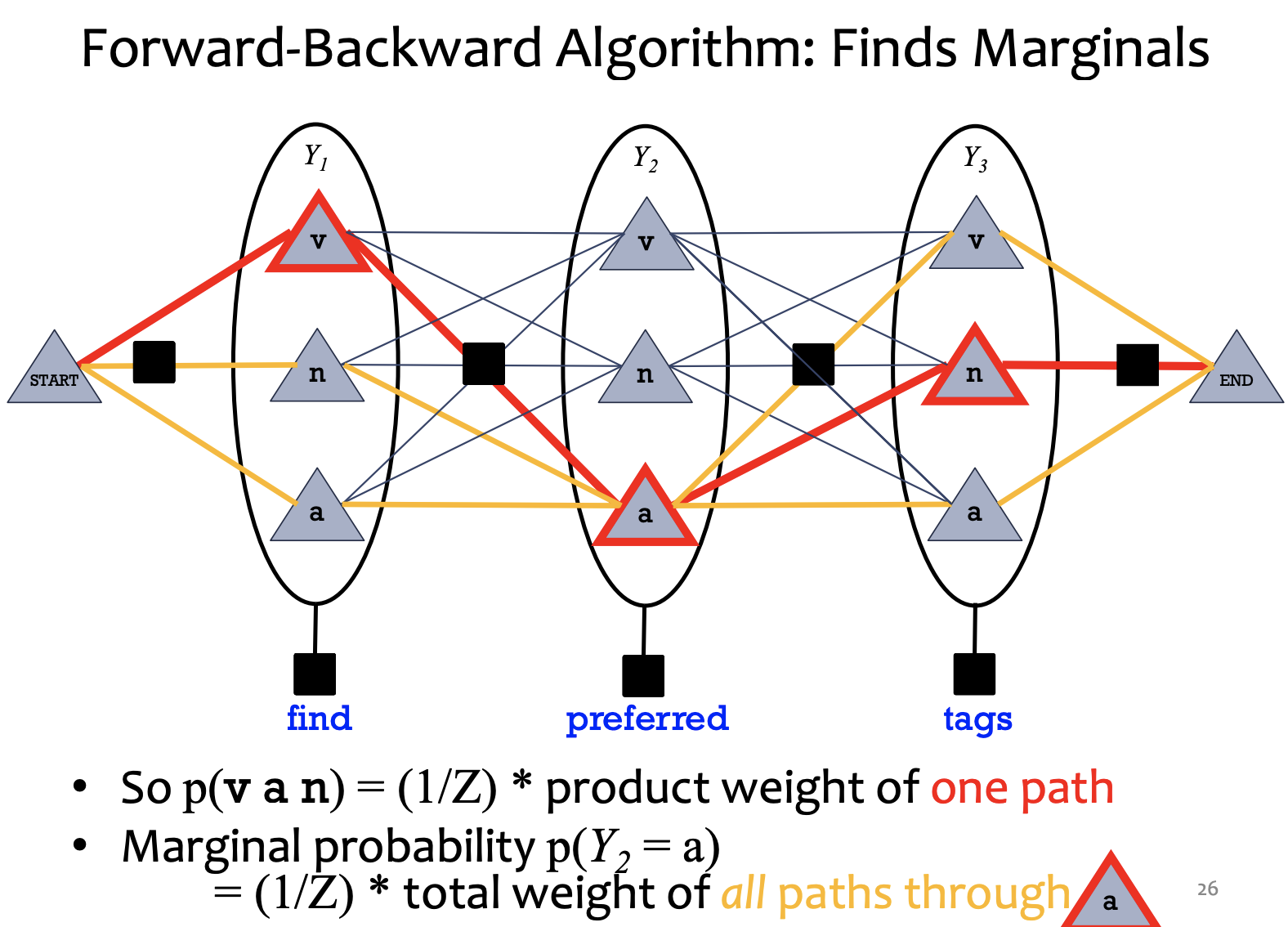
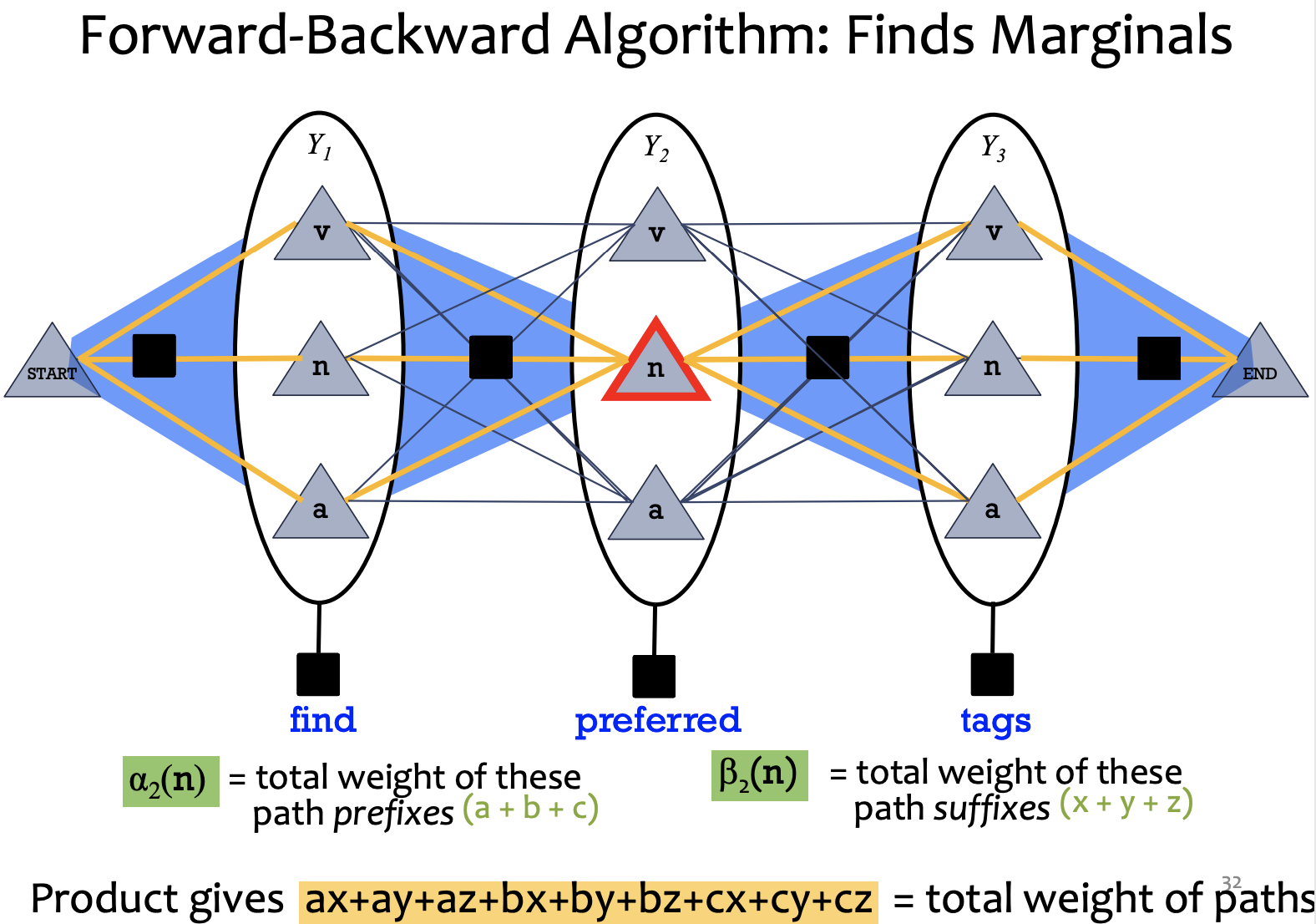
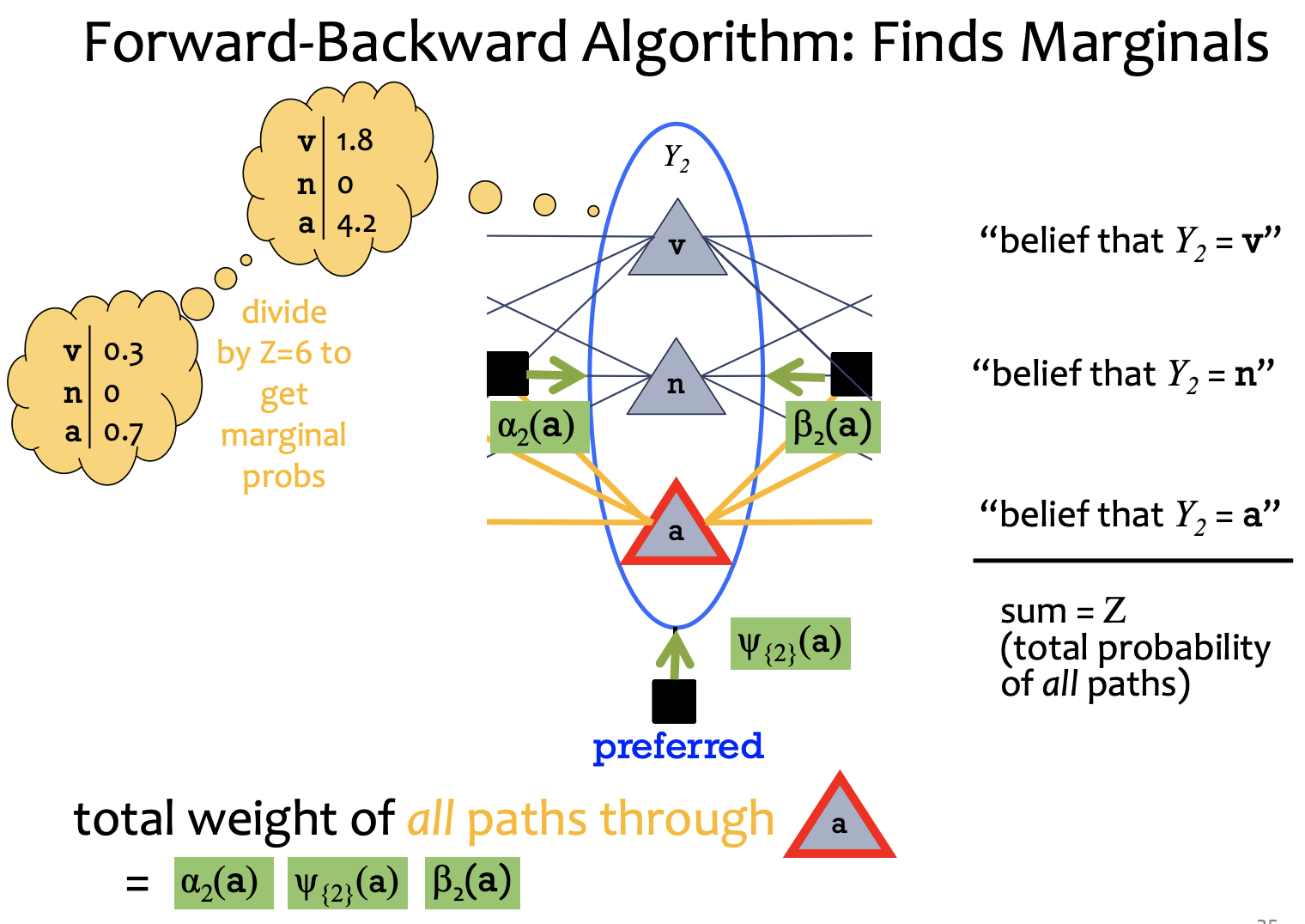
Marginals:
1) forward:


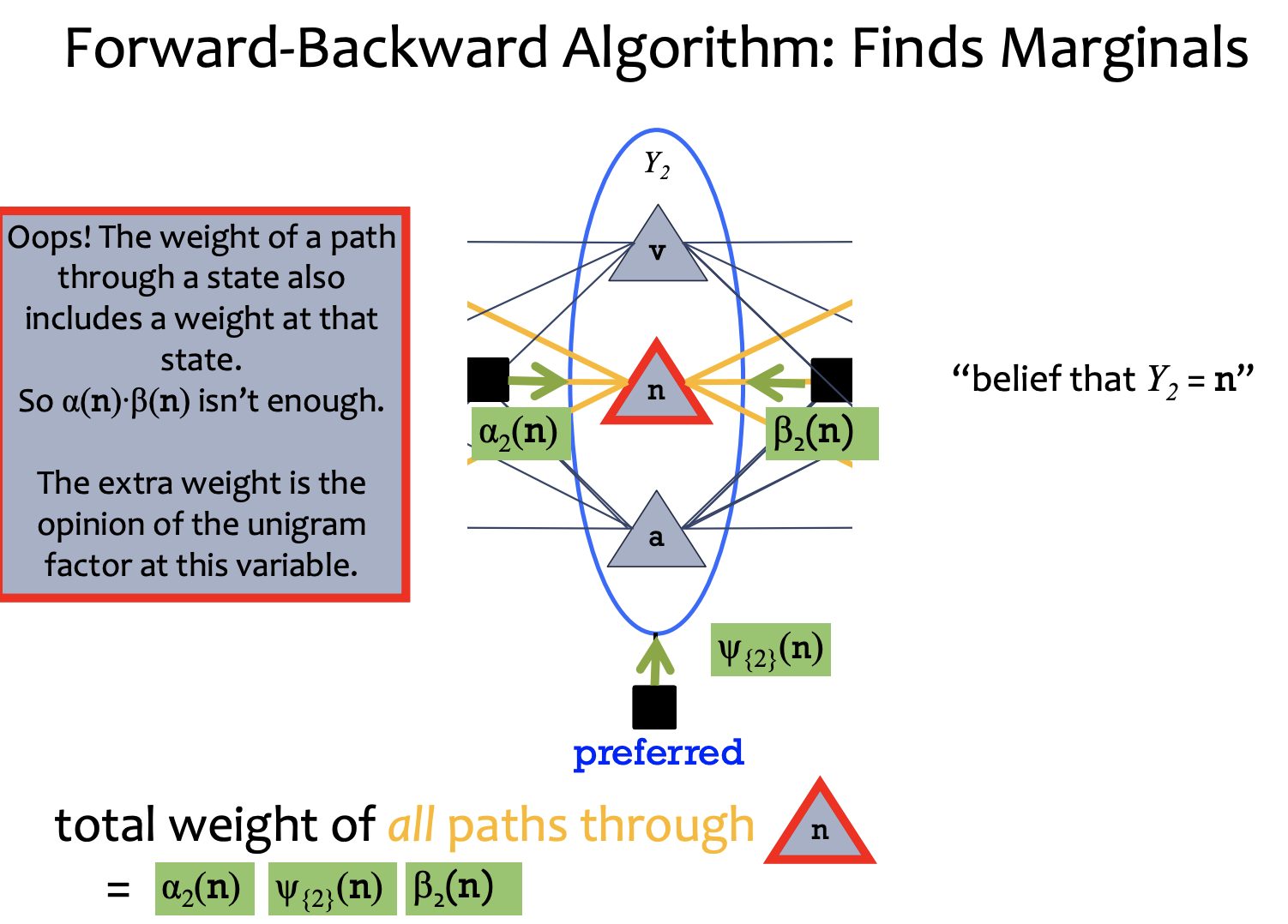
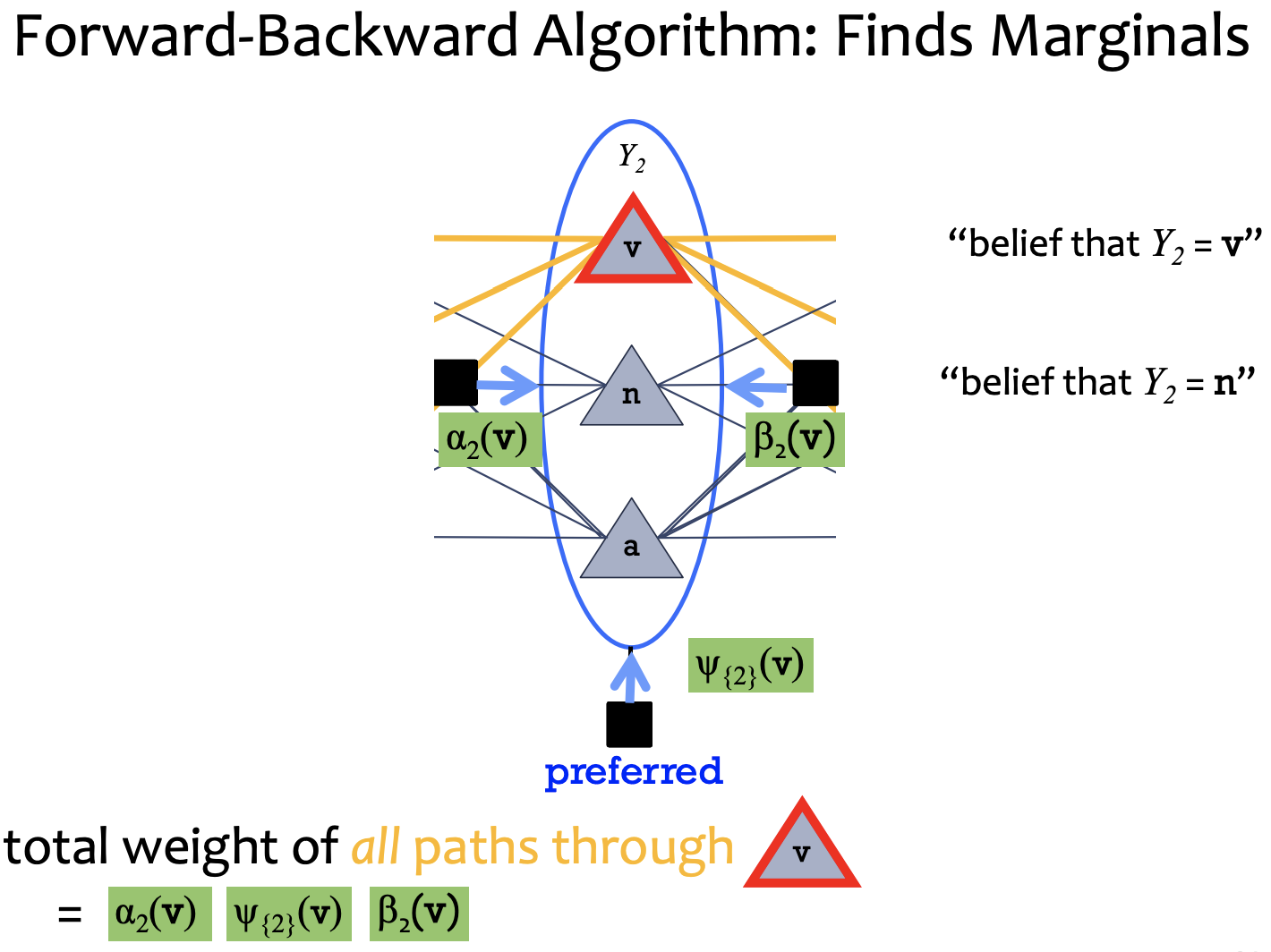
2) Belief:
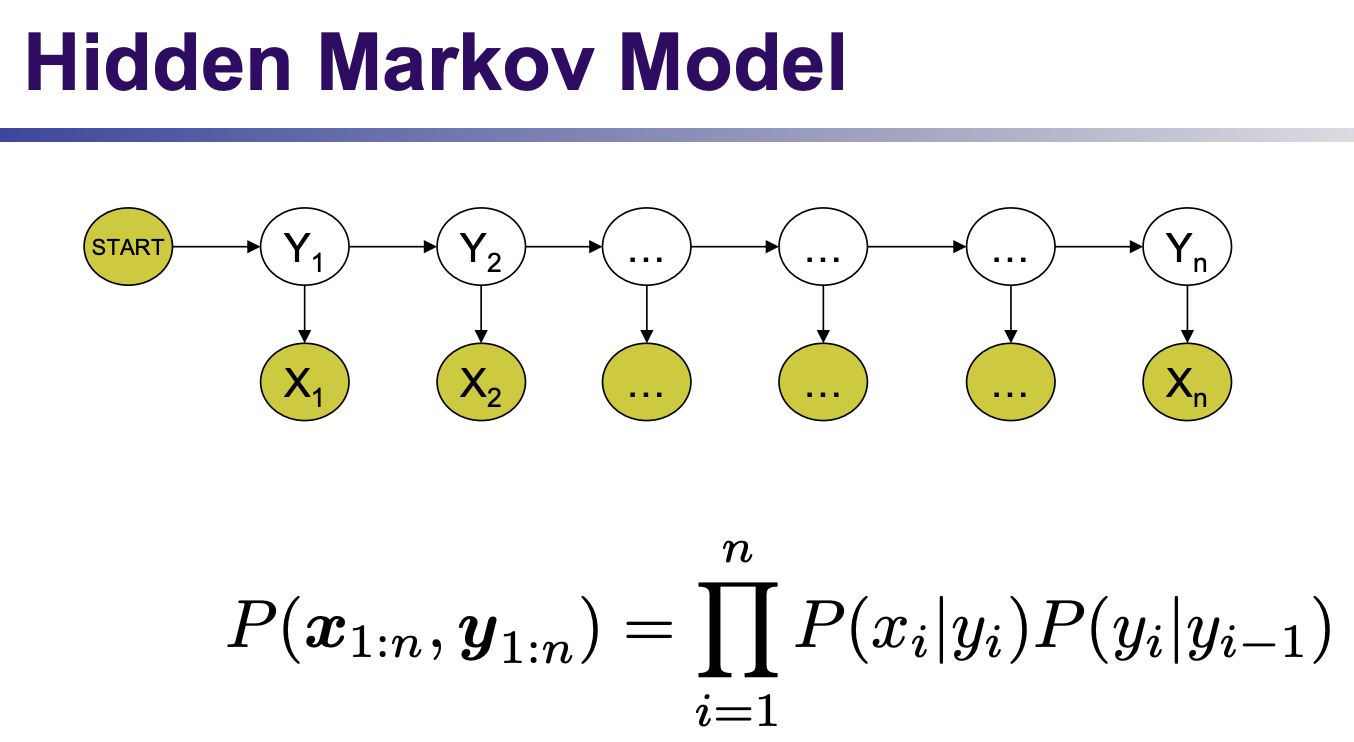
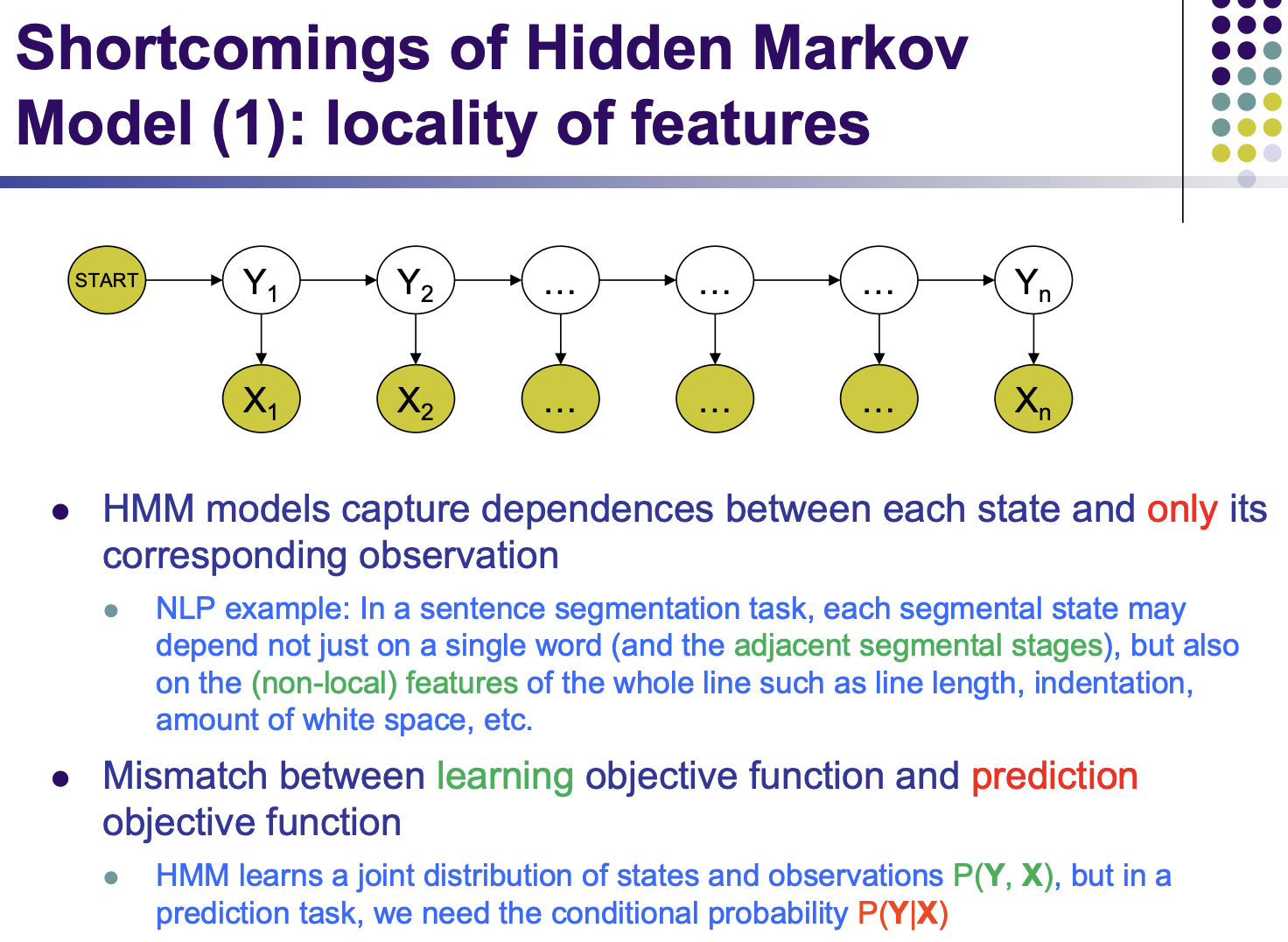
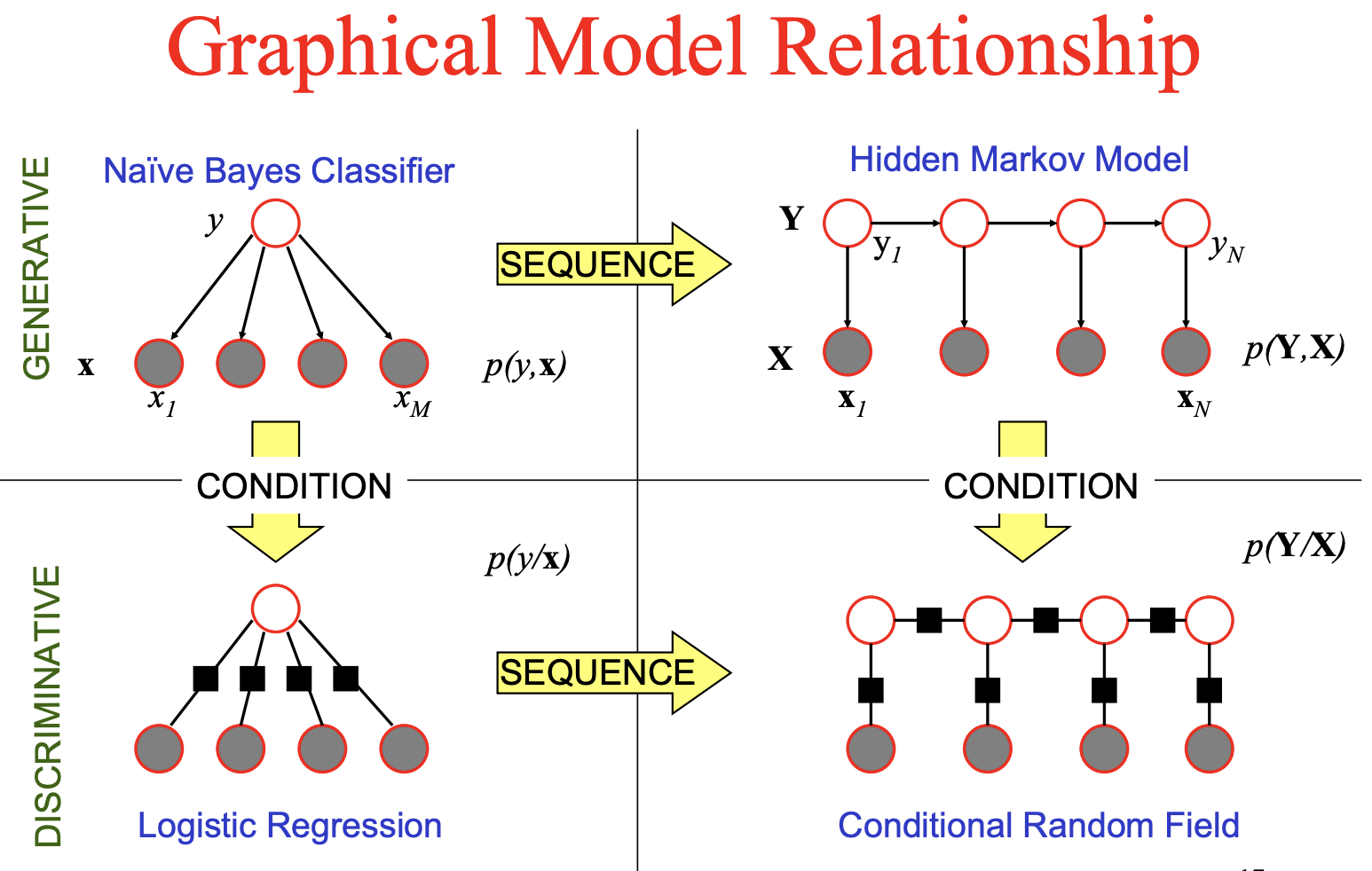
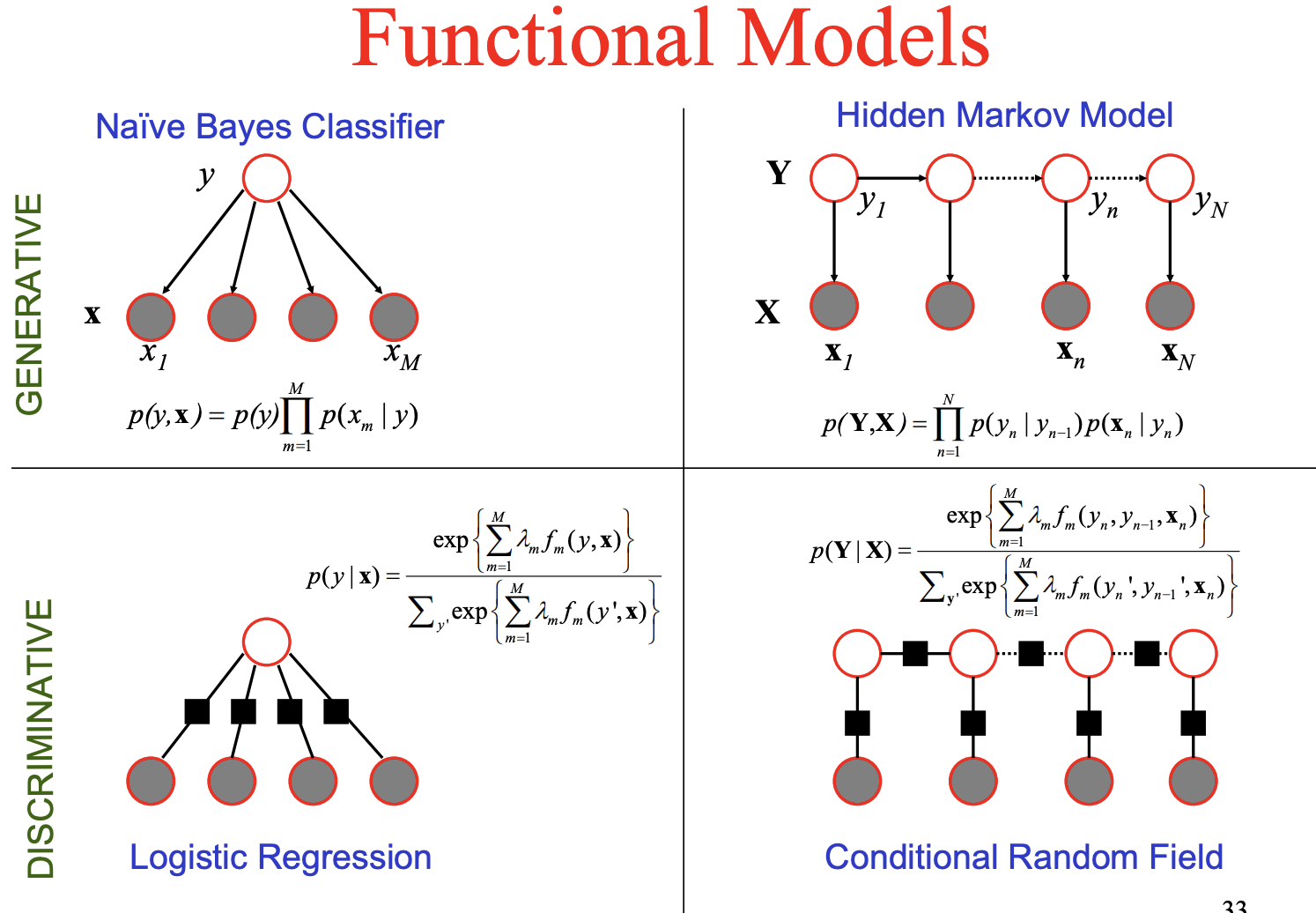
HMM is generative, modeling joint probability P(x,y)
but tagging just needs P(y|x)
https://cedar.buffalo.edu/~srihari/CSE574/Discriminative-Generative.pdf



Full obervation!
(like the offline SLAM?)


biased! because we only look at local observation.

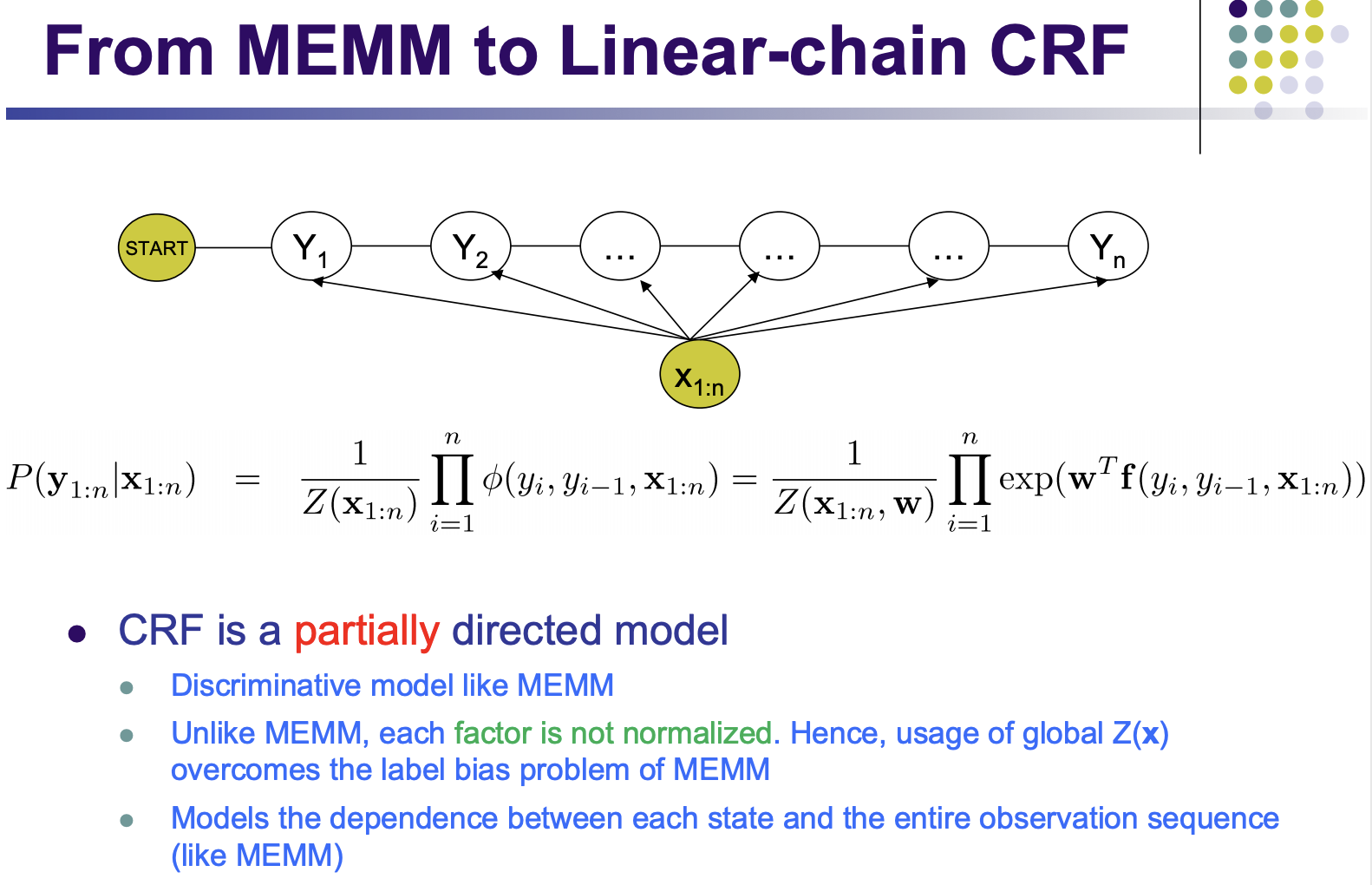





P(x_2|x_1) can be called Psi(x_1,x_2)
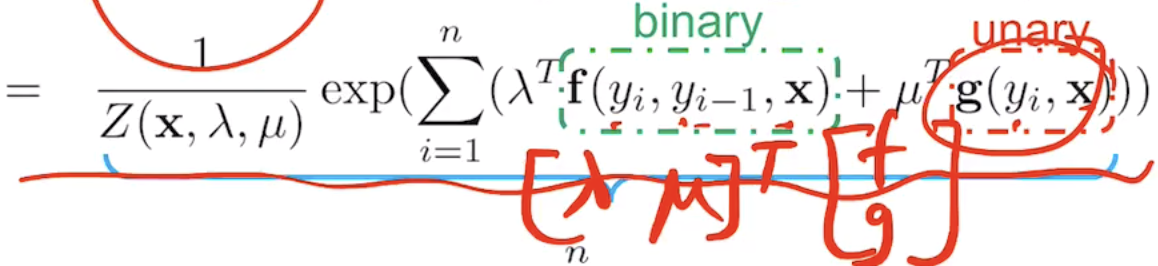
If Y_1 ~~~~ Y_{n-2} are connected somehow, what should be changed?




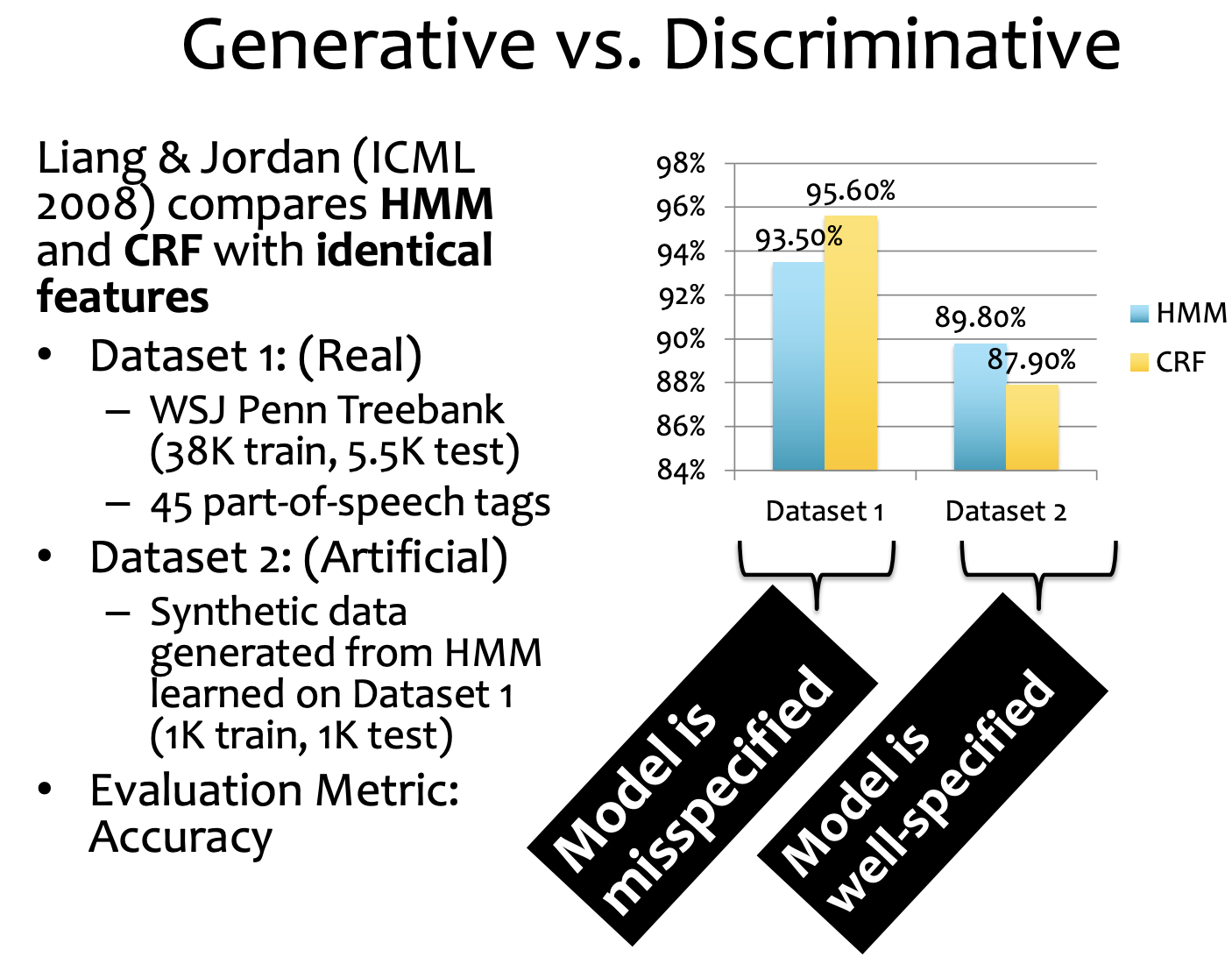
How close the model is closed to the truth.