这几天由于业务需要接触到了数据采集,用的是火车采集器,官网:http://www.locoy.com/baidu/index?baidu。
这里以8.0版本作演示,闲话就不多说了,首先,你看到的界面是这样的:
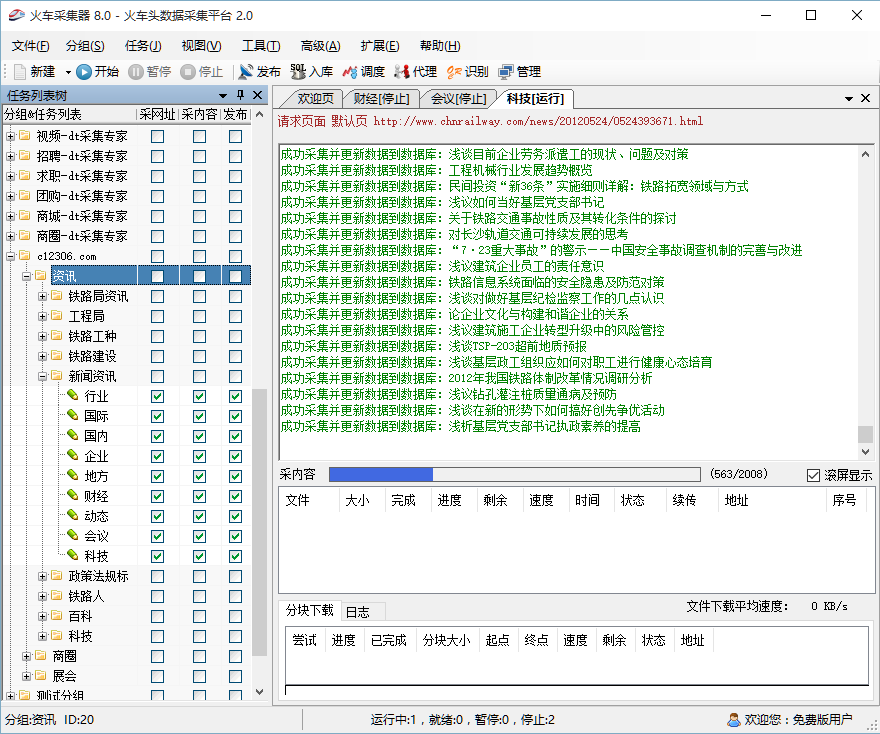
当然,第一次使用的话,左边这些列表是没有的,这是项目需要自建的任务列表。那么,现在从头开始介绍怎么操作吧。
1.新建任务
左边空白处右键--->新建分组
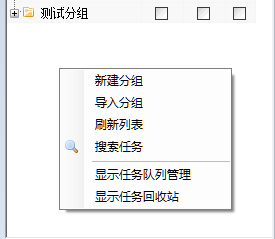
然后列表里多了一个任务组(这里以测试分组为例),接下来你可以继续在这个文件夹下继续建立分组或者直接新建任务(根据需要)
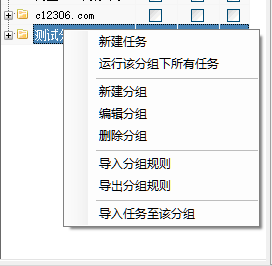
2.编辑任务
其实就是你新建任务之后的界面,任务名自定义:
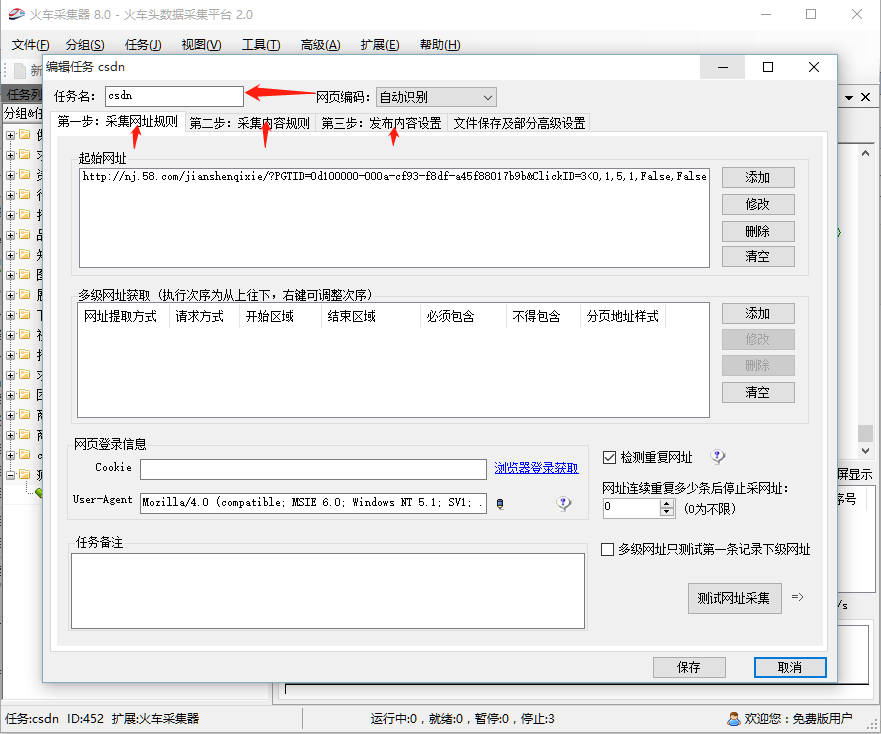
接下来就是该工具数据采集的重点了,拿个小本记一下!!!
2.1采集网址规则(列表页)
看到第一步右边的添加了没,点击添加:
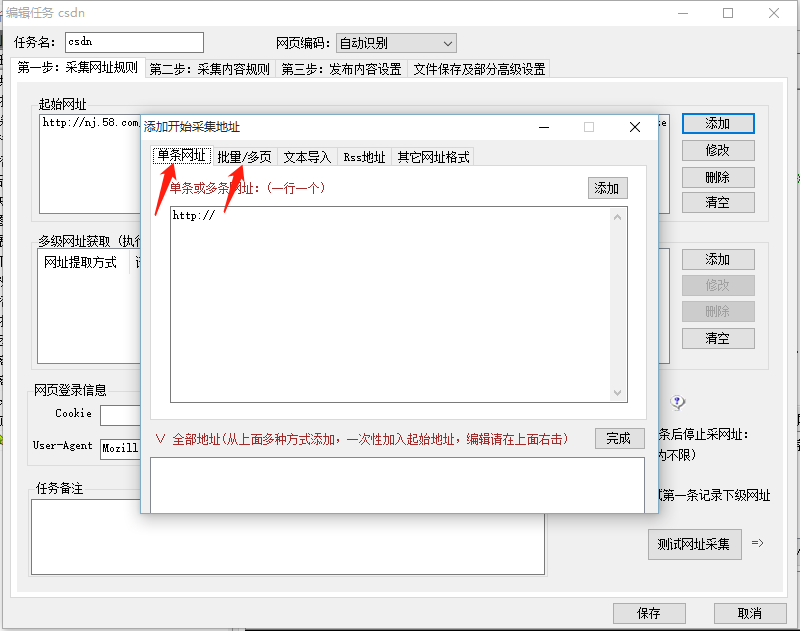
这里的网址规则分两种,一是单页网址,二是分页网址,举个栗子:
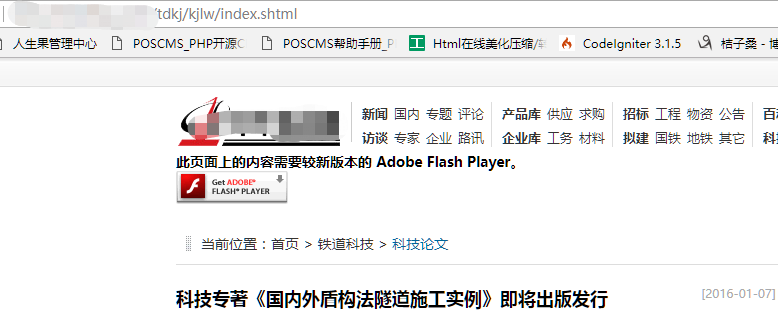
我要采集这个网站科技论文栏目下的所有文章,由于文章数目比较多,那么稳扎列表页也是有很多的,比如一个列表页有10篇文章:
http://www.XXXXX.com/tdkj/index.shtml; http://www.XXXXX.com/tdkj/index_2.shtml; http://www.XXXXX.com/tdkj/index_3.shtml; http://www.XXXXX.com/tdkj/index_4.shtml; http://www.XXXXX.com/tdkj/index_5.shtml; http://www.XXXXX.com/tdkj/index_6.shtml; http://www.XXXXX.com/tdkj/index_7.shtml; http://www.XXXXX.com/tdkj/index_8.shtml; http://www.XXXXX.com/tdkj/index_9.shtml;
这里有10个文章列表页,很显然,他们的地址规则是分两种风格的:第一页和其他九页;
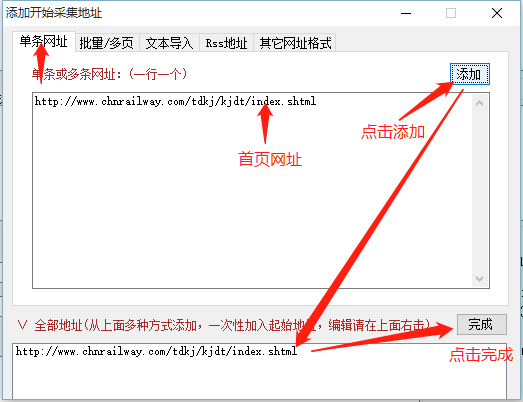
对于第一种风格,当然是选择"单条网址"(下面就不打码了):
对于第二种风格:
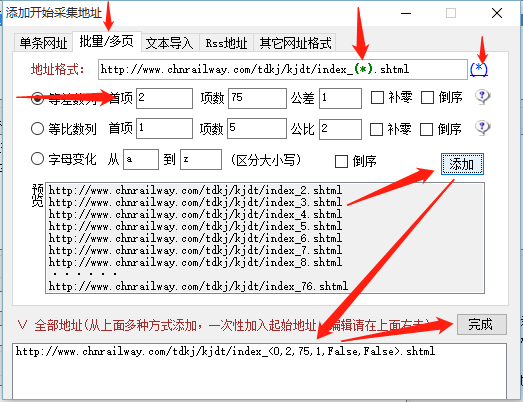
这样,文章列表页网址就全部拿到了,那么,怎么从这些文章列表页获取具体的文章页面链接呢?
2.2采集网址规则(内容页)
我们来看一下文章列表页的html结构(拿刚才的首页作栗子):

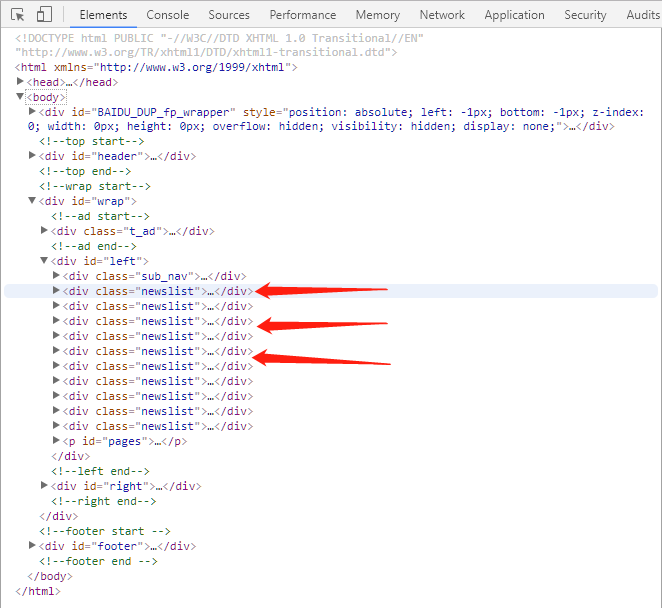
考虑到博客页面的整体宽度,以及两张图共一排对比的必要性,我将图缩小了,其实你也没必要看清图中的
具体文字,你只要根据上图体会一下,该html的结构即可;
毋庸置疑,每篇文章的具体内容页链接就在这个标题中了,不信你看:
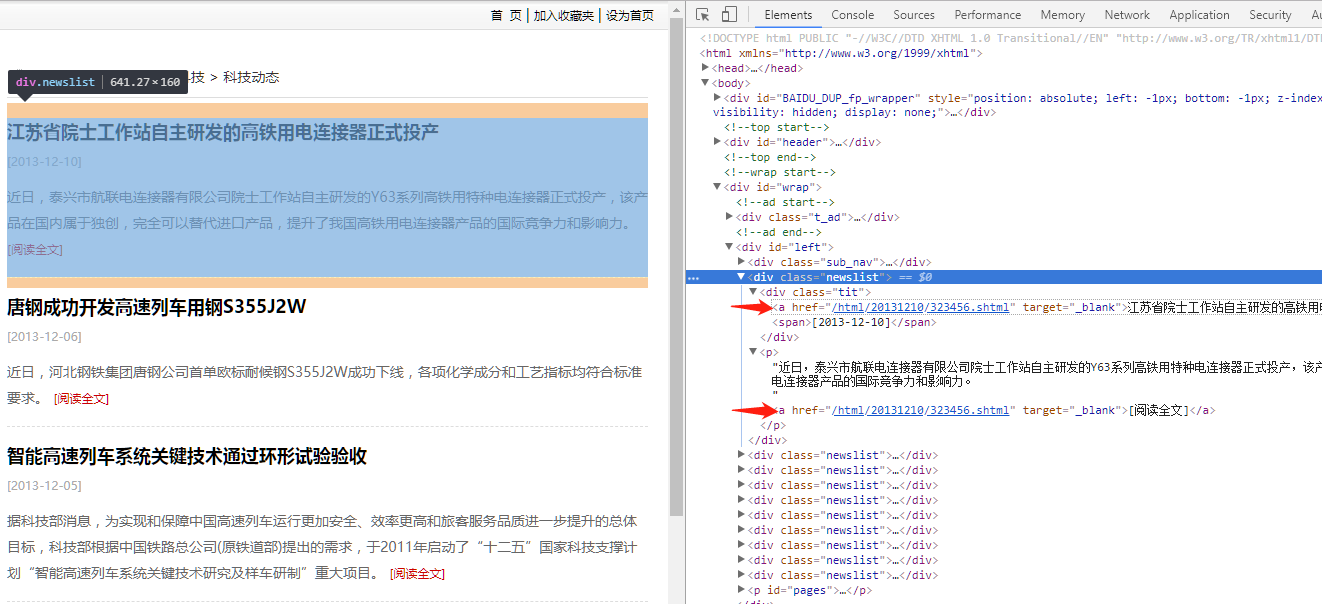
很显然我们要从DOM结构中获取这些内容页链接,那么就涉及到获取规则的写法了,请看:
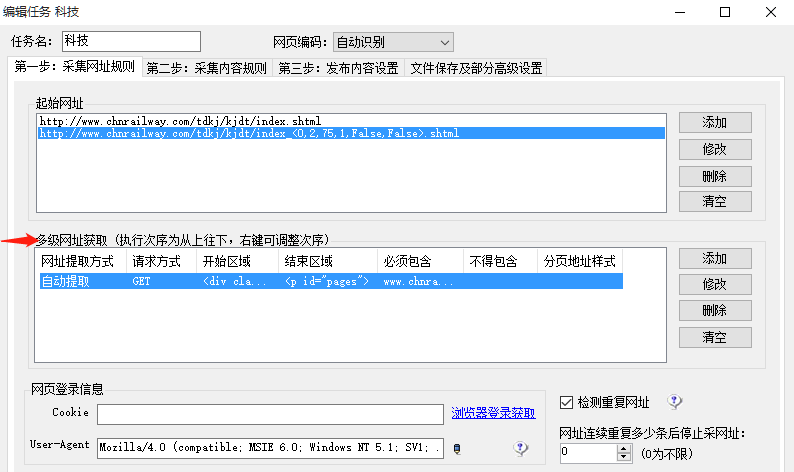
选择添加或者修改(如果你之前就有规则的话):
箭头从上到下,从左到右,需要注意的是,虽然工具给我们自动生成了规则,但工具毕竟是工具,他自动填充的规则通常都是不靠谱的!!!
那就需要我们自己分析规则了:
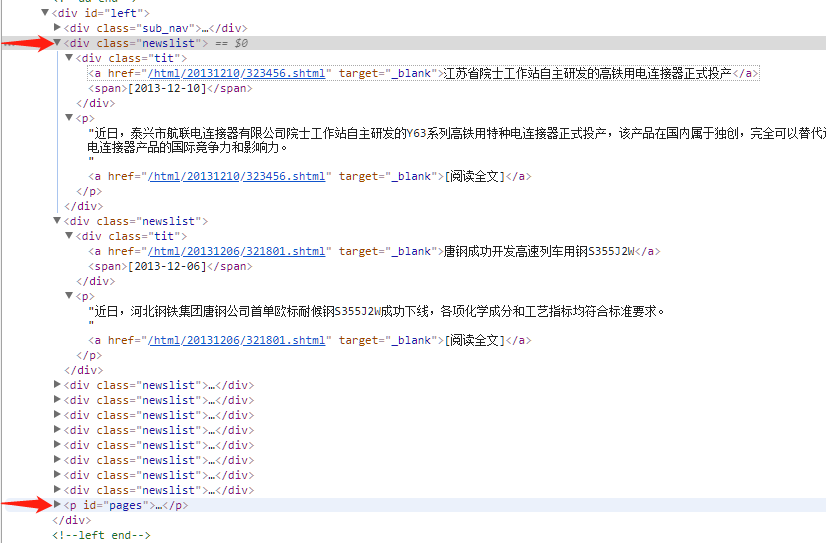
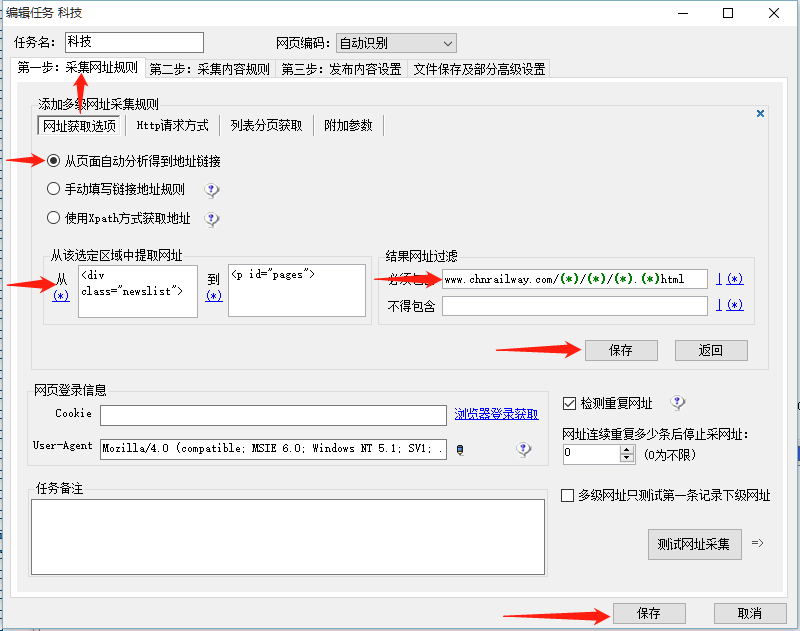
我们要获取所有<div class="newslist"> </div>里面的链接,这里就要注意了,工具是死的,所以你只能给他下死命令!!!
因此,这里的规则妍写成从<div class="newslist"> 到 <p id="pages">,只有这样,工具才会从上面的区域查找链接。
下面我们继续,已经知道从哪个区域找链接,接下来就是找哪种链接了,这时候你要瞄一下,所有详情页文章链接长什么样,比如:
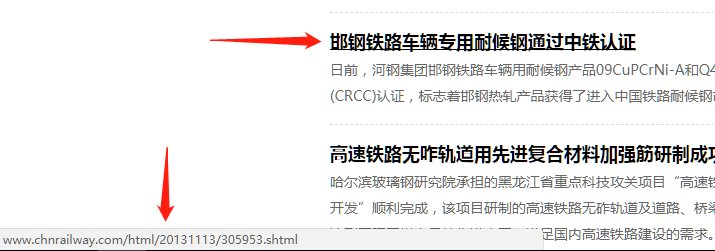
在列表页鼠标放到文章标题上你就可以看到了(恕我啰嗦),然后你大概扫了一下,发现所有列表页的文章详情页链接差不多像下
面这样:
http://www.chnrailway.com/news/20090606/0606326101.html http://www.chnrailway.com/html/18-03-12/23-45-78.shtml http://www.chnrailway.com/rail/show-9875756/78-78.html
那么你应该可以写出规则了:
http://www.chnrailway.com/(*)/(*)/(*).(*)html
这样一来,详情页的链接你也拿到了,接下来就是设置详情页内容的获取规则了。
2.3采集内容规则(详情页内容规则)
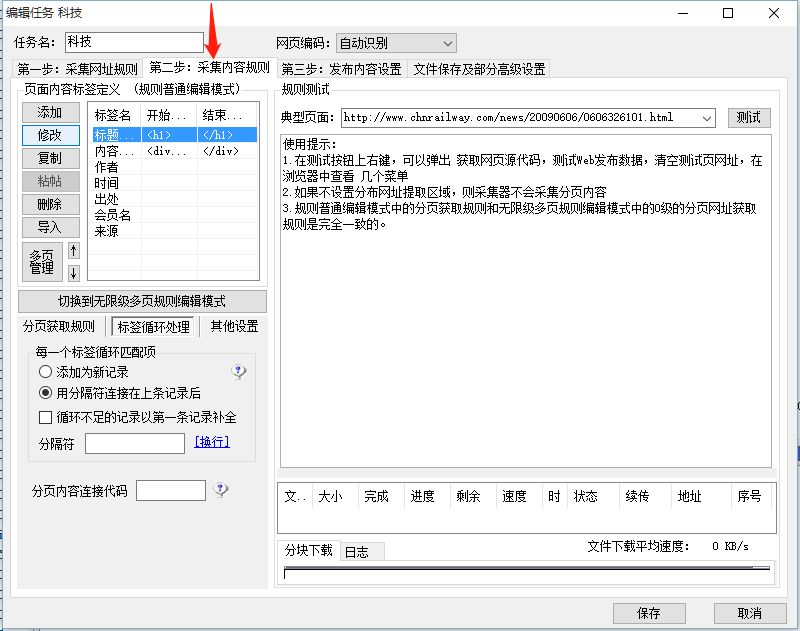
看到没有,在这里可以设置标题、内容以及其他的数据获取来源,我们先拿标题来看:
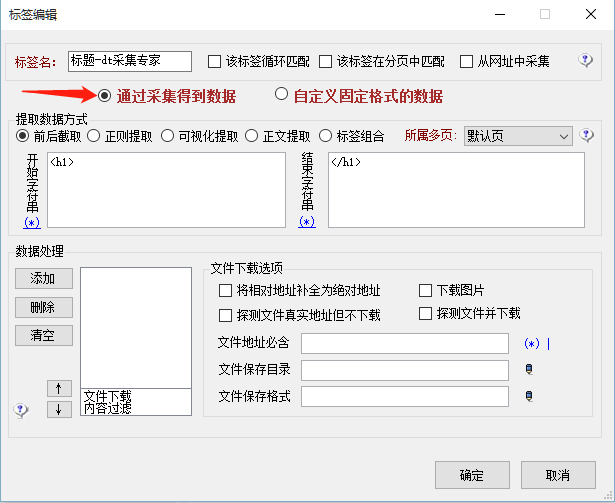
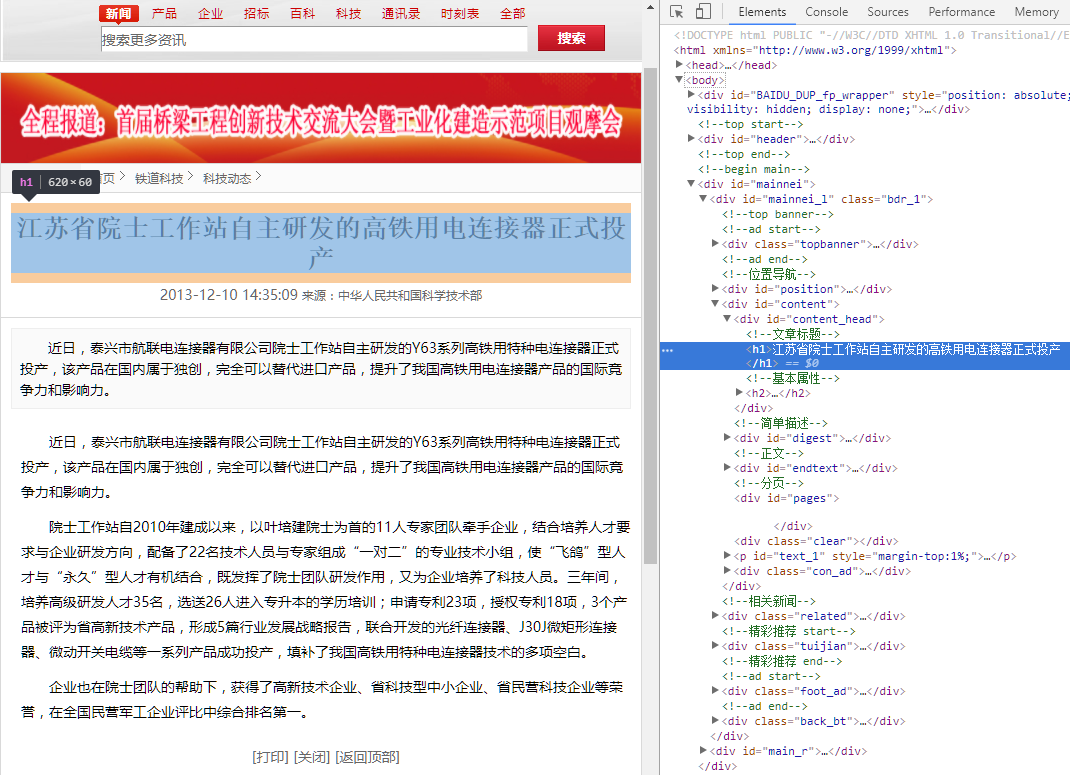
我把右边这块放大:
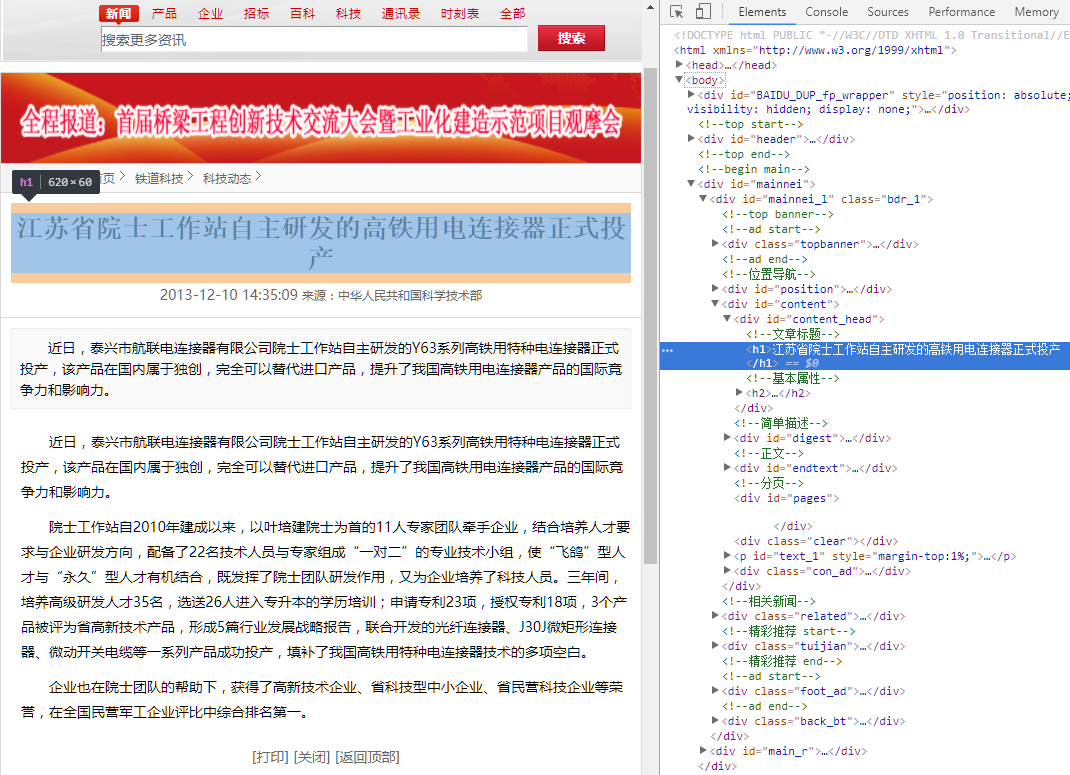
很显然,这个标题要从DOM结构的<h1> </h1>中拿,具体要根据html来判断,毕竟不同网站的html风格不同,于是就将这个规则填入标题
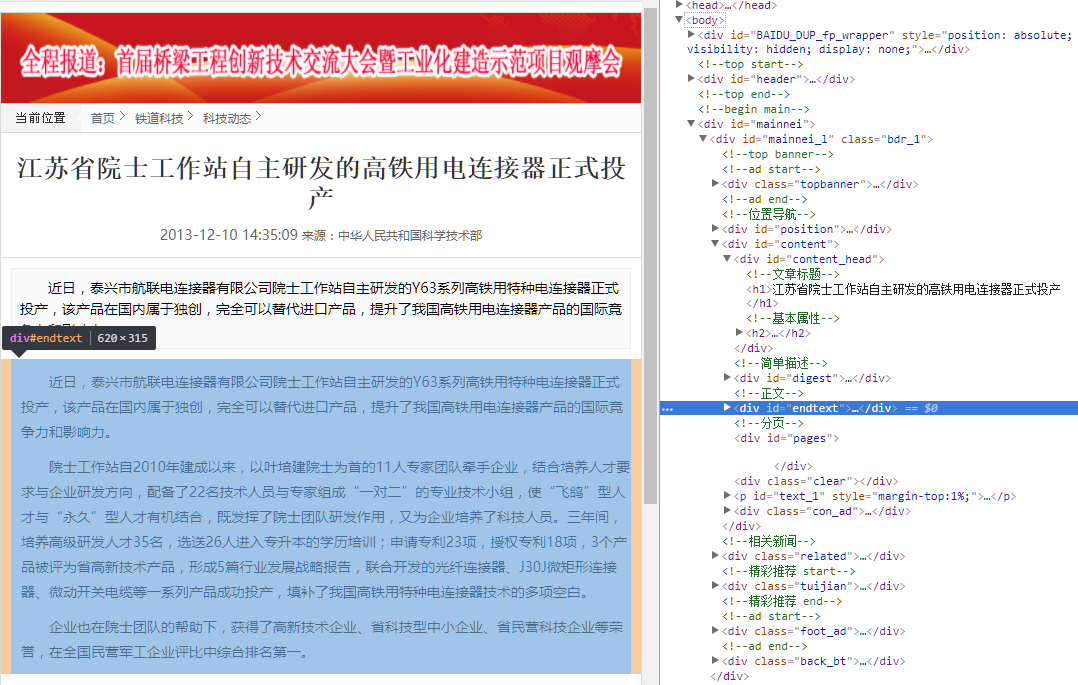
获取的规则里,同理,文章内容规则也是一样,给出一张图,自己琢磨吧。
2.4测试规则
测试就是说,看看自己之前写的规则能不能采集到源网站数据。
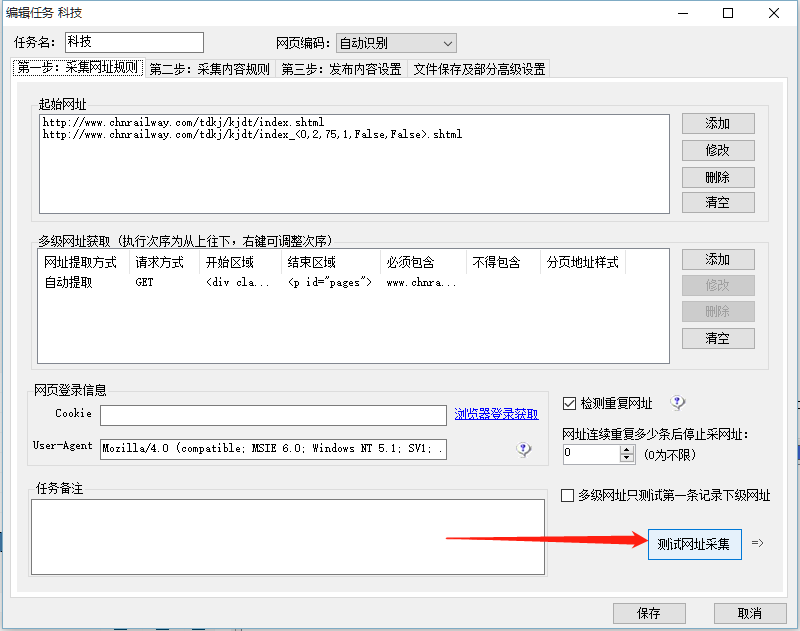
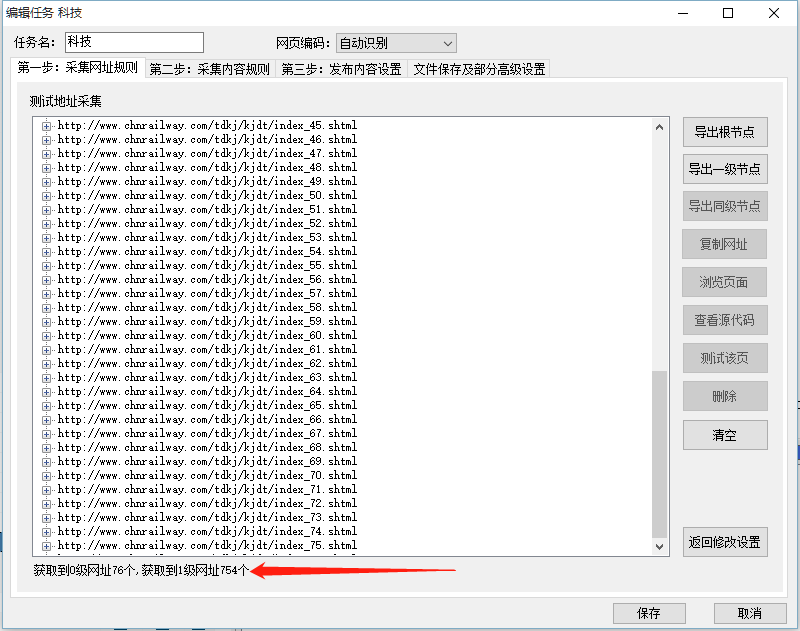
点击任意加号,找到一个详情页,然后右边"测试该页":
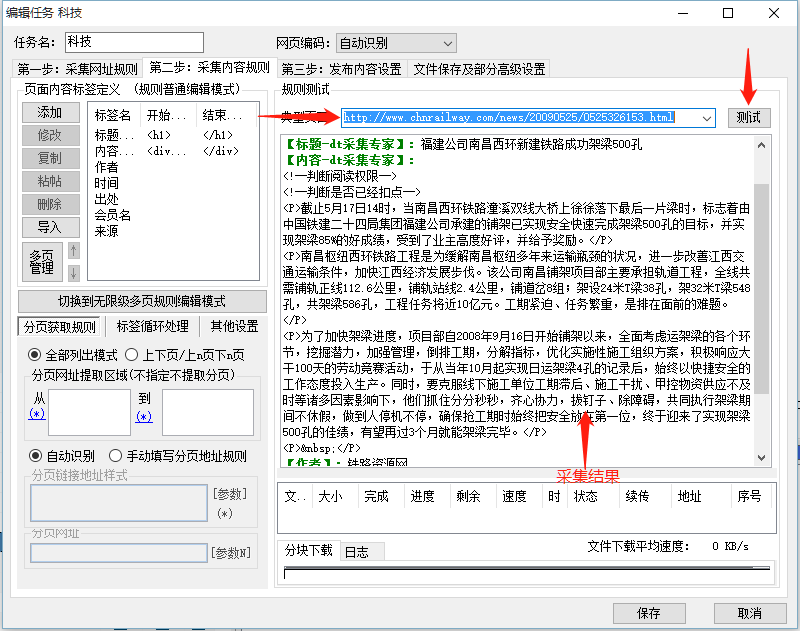
如果可以获取到你想要的数据,那么说明你之前写的规则是正确的!!!
2.5发布内容设置
数据采集好了,当然要发布到目标网站啊,那么:
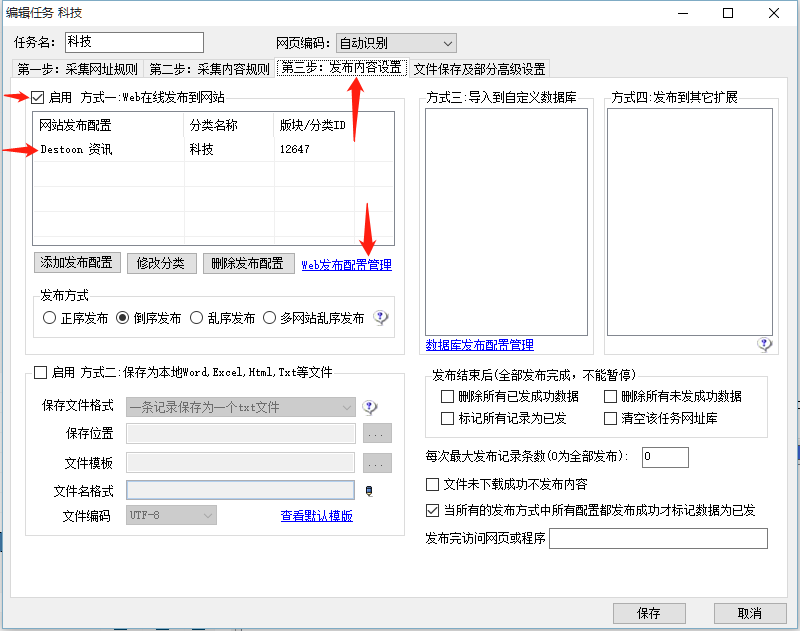
这个发布配置可以自定义配置的(我们点开WEB发布配置管理):
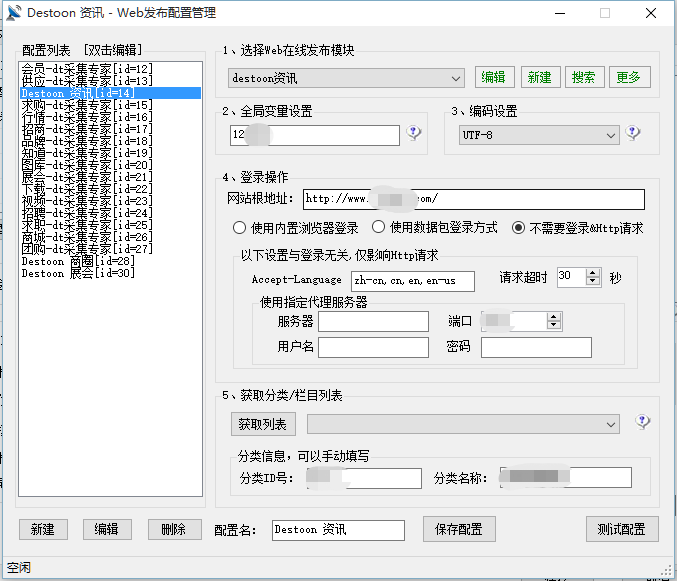
这些都是根据你要发布的网站而定的。
至于最后一项:文件保存以及部分高级设置,可以不作任何修改,如果你有兴趣,请自行研究。
所有的规则、配置都写好并测试无误之后,你的这项采集任务可以说是完成了,那么接下来就是,执行任务了:
这三个复选框分别表示:采网址、采内容、发布,如果你已经全选了,那么
右键这条任务,开始任务,他就开始采集数据并上传数据了,根据数据量的多少,任务执行的时间也会不同哦~~~