本章为读者提供了Linux虚拟化中流行技术的深刻见解,以及相较于其他同类技术的优势特点。本书共有14章,囊括了KVM虚拟化中的各个方面,从KVM的内部构造开始,并包括了诸如软件定义网络(SDN),性能调节和优化以及P2V(physical to virtual migration)等高级内容。
在本章中,我们将学习以下内容:
- Linux虚拟化和它的基本概念
- 为什么我们要使用Linux虚拟化
- Hypervisor/VMM
- 在云计算中,Linux虚拟化可以为你提供什么
- 公有云和私有云
TIP:在开始学习之前,你可以前往本书的主页,查看相关的更新,技巧和更新情况 http://bit.ly/mkvmvirt
什么是虚拟化
在哲学概念中,虚拟意味着“某些并非真实存在的东西(something that is not real)”。在计算机科学中,虚拟的意思“一个并非物理存在的硬件环境(a hardware environment that is not real)”。在这里,我们复用物理硬件的功能,并用来运行操作系统。用来创建此类环境的相关技术,我们称之为“虚拟化技术”,简称“虚拟化”。运行虚拟化软件(Hypervisor或者叫VMM,虚拟机监视器)的物理设施我们称之为Host,安装在Hypervisor之上的虚拟机称为Guest。
为什么我需要使用Linux虚拟化
User-mode Linux (UML) 是首个出现在Linux上的虚拟化技术。现在Linux上已经有许多种虚拟化技术可供选择,可以将一台主机虚拟成多台使用。比较流行的虚拟化技术包括KVM,XEN,QEMU以及VirtualBox。本书主要聚焦的是KVM虚拟化。
开放性,灵活性和性能是Linux虚拟化吸引用户的几个主要因素。和其他的开源一样,Linux虚拟化技术是在一种合作的模式下得到发展的,这间接地使用户享受了开源软件便利和优势。举例来说,相较于闭源模式,开源可以从社区获得广泛输入,间接帮助降低研究和开发支出,提升了效率,性能和生产力。开源模式鼓励创新。下面是一些开源带来的其他好处和优势:
- 来自实际问题的用户驱动的解决方案
- 从社区和用户获取支持,帮助用户解决问题
- 提供技术设施的选择
- 数据和安全的掌控,可以根据需要自由阅读,研究和修改代码
- 避免了厂商锁定,可以灵活地在同类技术产品之间进行迁移
虚拟化的分类
简而言之,虚拟化是虚拟 硬件、网络、存储、程序、访问等资源的过程。因此,虚拟化技术可以应用在以上提到的多个内容当中。
例如:
- 软件定义网络
- 软件定义存储
- application stream、远程桌面服务、桌面虚拟化等应用程序虚拟化技术
尽管如此,在本书的内容中,我们主要讨论基于Hypervisor的软件虚拟化方面的内容。从这个视角来看,虚拟化隐藏了底层物理硬件,使其可以被多个操作系统共享和使用。这也被称为平台虚拟化。简而言之,这表明了在底层硬件和运行在它上面的操作系统间,有一个称为hypervisor/VMM的中间层。运行在Hypervisor之上的操作系统被称为Guest或者VM。
虚拟化的好处
让我们来讨论一下虚拟化的一些好处:
- 服务器整合:虚拟化可以帮助节省电力和拥有更小的能源足迹,这是众所周知的。利用虚拟化技术实现服务整合可以减少整个数据中心的总使用量。虚拟化减少了裸金属服务器数量,减少了网络设备以及其他相关的物理设施,例如机架。最终地,它减少了楼层空间和电力资源等消耗。这些可以为你节省金钱,帮助你提高能源利用率。它是否确实地增加了硬件的利用率?是的。我们可以以确切的CPU、内存、存储资源数量来置备我们所需的虚拟机,反过来,这使得我们可以确信硬件使用率确实得到了增加。
- 服务隔离:假如没有虚拟化,在这种情况下,如何实现服务隔离。是否需要将每个应用程序跑在单独的物理服务器中?没错,这也可以保证服务的隔离。但是,这是否会导致物理服务器无序增长,服务器利用率低和成本增长吗?答案是显而易见的。服务器虚拟化可以帮助应用程序相互隔离,并通过在更少的物理服务器上整合许多虚拟机,从而消除应用程序兼容性问题。简而言之,服务隔离技术带来了简化的服务管理的优势。
- 更快的服务器配置:置备一台裸金属服务器需要消耗大量时间,即使我们在自动化的道路上已经取得了很多进步。但在虚拟化的情况下,您可以从预先构建的镜像(模板)或快照中生成虚拟机。就像你想象的那样,速度很快。另外,你不必担心物理资源配置,例如会带来很大物理或者裸金属服务器置备负担的“网络堆栈”等内容。
- 灾难恢复:当你拥有一个虚拟化数据中心时,灾难恢复会变得很容易。虚拟化允许你为虚机生成最新的快照。这些快照可以快速地重新部署,这样您就可以到达一个一切都运行良好的状态。另外,虚拟化提供了一些特性,比如在线和离线VM迁移技术,这样您就可以移动这些虚拟机到数据中心的任意其他地方。这种灵活性有助于制定更容易实施,成功率更高灾难恢复计划。
- 动态负载均衡:这取决于你制定的策略。当服务器工作负载改变,虚拟化技术可以基于你制定的策略,将虚拟机从高负载的服务器,迁移至低负载的服务器。大多数的虚拟化解决方案都为用户准备此类策略。这种动态负载平衡可以有效地利用服务器资源。
- 更快的开发和测试环境:试想一下,你想以临时的方式测试环境。在物理服务器上面部署非常困难,不是吗?另外,如果你以一种临时的方式来搭建这个环境,也不太有价值。但是,以虚拟化的方式搭建一个生产或者测试环境却非常简单。通过使用一个虚拟机操作系统用来隔离出一个已知和受控的环境,使得快速开发成为了可能。它还消除了许多未知因素,比如多次安装导致的多个库文件版本并存。特别是,如果它是一个开发或测试环境,我们可以预料到由于安装实验性版本而导致的严重崩溃。如果这发生在物理或裸金属服务器上,我们需要数小时的事件来重新安装配置环境。然而,在VM的情况下,这只需要简单地复制一个虚拟映像并再次尝试。
- 改善系统的可靠性和安全性:虚拟化解决方案增加了虚拟机和底层物理硬件之间的抽象层。在物理机磁盘上的数据由于某些原因导致损坏进而影响整个服务器是很常见的。然而,如果存储在虚拟机硬盘中,主机系统中的物理硬盘将完好无损,不需要担心替换虚拟硬盘。在任何其他实例中,虚拟化都可以防止由于设备驱动程序等软件造成的内存崩溃而导致系统崩溃。系统管理员可以在独立和隔离的环境中配置虚拟机。这种虚拟机的沙箱部署可以为基础设施提供更多的安全性,因为管理员可以灵活地选择最适合这种设置的配置。如果管理员决定某个特定的VM不需要访问Internet或其他的生产网络,那么虚拟机就可以轻松地被设置在一个完全隔离的网络配置中,并限制其对其他部分网络的访问。这有助于减少由单个系统感染进而影响大量生产计算机或虚拟机的风险。
- OS独立或硬件厂商锁定:虚拟化就是在底层硬件之间创建一个抽象层,并向运行在堆栈顶部的Guest OS提供虚拟硬件。虚拟化消除了硬件厂商锁定,不是吗?也就是说,虚拟化的设置必须绑定到一个特定的供应商/平台/服务器,特别是当虚拟机并不真正关心它们运行的硬件的时候。因此,当选择服务器设备时,数据中心管理员就有了更多的灵活性。简而言之,虚拟化技术的优势在于它的硬件独立性和封装性。这些特性增强了可用性和业务连续性。虚拟化的优点之一是软件和硬件之间的抽象。

正如我们在前一节所讨论的,尽管虚拟化可以在不同的领域实现,但我想更多地讨论操作系统虚拟化和软件虚拟化。
操作系统虚拟化/分区
OS虚拟化技术允许同一物理主机服务不同的工作负载,并隔离每个工作负载。请注意,这些工作负载在相同的操作系统上独立运行。这允许物理服务器运行多个独立的操作系统实例,称为容器。这被称为基于容器的虚拟化技术也没有什么不对。此类虚拟化技术的优势是,Host的操作系统不需要模拟和自身OS不同的的系统调用接口。由于上述接口不存在,因此在这种虚拟化中,其他操作系统无法被虚拟化或支持。这是此类虚拟化的常见且易于理解的限制。Solaris containers、FreeBSD jails和Parallel的OpenVZ都属于这一类虚拟化。在使用这种方法时,所有的工作负载都运行在单个系统上。进程隔离和资源管理由内核提供。虽然所有的虚拟机/容器在同一个内核中运行,它们也有自己独立的文件系统、进程、内存、设备等等。从另一个角度来看,同一物理主机上的Windows、Unix和Linux工作负载的混合,并不是这种虚拟化的一部分。但是性能和效率上带来的好处远超过该技术的局限性,因为一个操作系统就可以支持所有的虚拟环境。此外,从一个分区切换到另一个分区的速度非常快。
在我们进一步讨论虚拟化和深入到下一种虚拟化类型之前(hypervisor-based /软件虚拟化),了解计算机科学中的一些术语是很有用的。话虽如此,我们还是从“protection rings”开始吧。在计算机科学中,存在着各种分级保护域(hierarchical protection domains)/特权环(privileged rings)。在访问计算机系统中的资源时,这种安全机制用于保护数据或错误(These are the mechanisms that protect data or faults based on the security enforced when accessing the resources in a computer system.)。这些保护域有助于计算机系统的安全性。
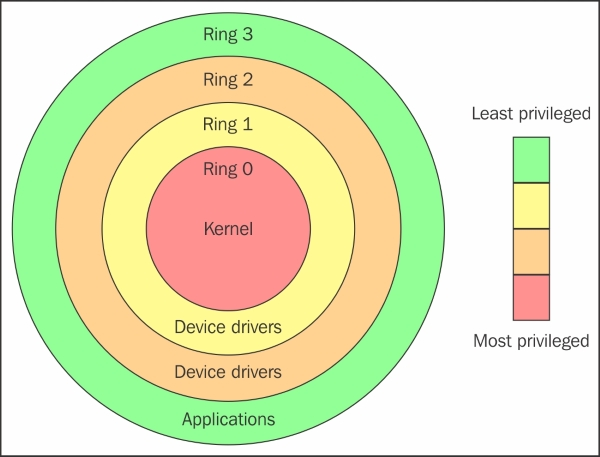
如之前的图片显示,protection rings从最高特权到最低特权进行编号。ring 0是最高特权等级,它直接与物理硬件交互,例如CPU和内存等。诸如内存,IO端口和CPU指令的资源通过特权ring受到保护。ring 1和ring 2通常不被使用。大多数通用操作系统只使用两个ring,即使它们运行的硬件提供了更多的CPU模式。这两个主要的CPU模式被称为内核模式(kernel mode)和用户模式(user mode)。从操作系统的角度来看,Ring 0被称为kernel mode/supervisor mode,而Ring 3是user mode。正如你所想的一样,应用程序运行在Ring 3。
诸如Linux和Windows这样的操作系统使用supervisor/kernel 和 user mode。用户模式在没有调用内核情况下,几乎不能做任何事,因为它被限制了对内存、CPU和I/O端口的访问。内核可以在特权模式下运行,这意味着它们可以在ring 0上运行。为执行特定的函数,用户模式代码(所有应用程序运行在ring 3)必须执行supervisor mode或内核空间的系统调用,操作系统的可信代码将执行所需的任务并将执行结果返回给用户空间。简而言之,正常环境下OS运行在ring 0下。它需要最高特权级别来进行资源管理并提供对硬件的访问。以下图片解释了这一点:
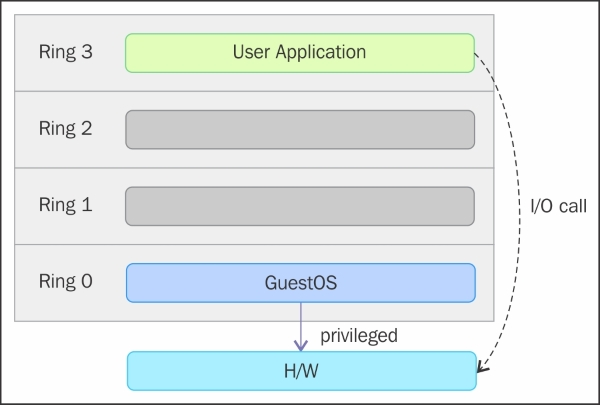
ring大于0时在称为unprotected的处理器模式下运行指令。hypervisor/VMM需要访问主机的内存、CPU和I/O设备。因为,只有在ring 0中运行的代码才能执行这些操作,它需要运行在最高特权的ring 0,并且放置在靠近内核的地方。如果没有特定的硬件虚拟化支持,hypervisor/VMM运行在ring 0中,这基本上阻止了虚拟机操作系统运行在ring 0。所以VM的操作系统必须运行在ring1。在VM中安装的操作系统也需要访问所有资源,因为它并不能感知虚拟化层。为了实现这一点,它必须和VMM一样运行在ring 0中。由于同一时间只有一个内核可以运行在ring 0,所以Guest OS必须在另一个具有更少特权的ring中,或者必须修改以在用户模式下运行。
这导致需要引入称为全虚拟化和半虚拟化的虚拟化方法,我们将在下面的部分中进行讨论。
全虚拟化
在全虚拟化中,通过模拟特权指令来克服由Guest OS运行在ring1和VMM运行在ring 0中所产生的限制。全虚拟化在第一代x86 VMM中广泛采用。它依靠例如二进制转译(binary translation)来捕获和虚拟化某些敏感和无法虚拟化的指令。也就是说,在二进制转换中,一些系统调用被解释执行和动态重写。下图描述了“Guest OS如何在ring 1下访问主机硬件,执行特权指令”以及“非特权指令是如何在无ring 1参与的情况下获得执行”。

通过这种方法,关键指令就会在运行时(静态或动态地)发现,取而代之的是陷入VMM中以软件仿真的方式执行。与运行在原生虚拟化架构上的虚拟机相比,二进制转换可能会带来巨大的性能开销。
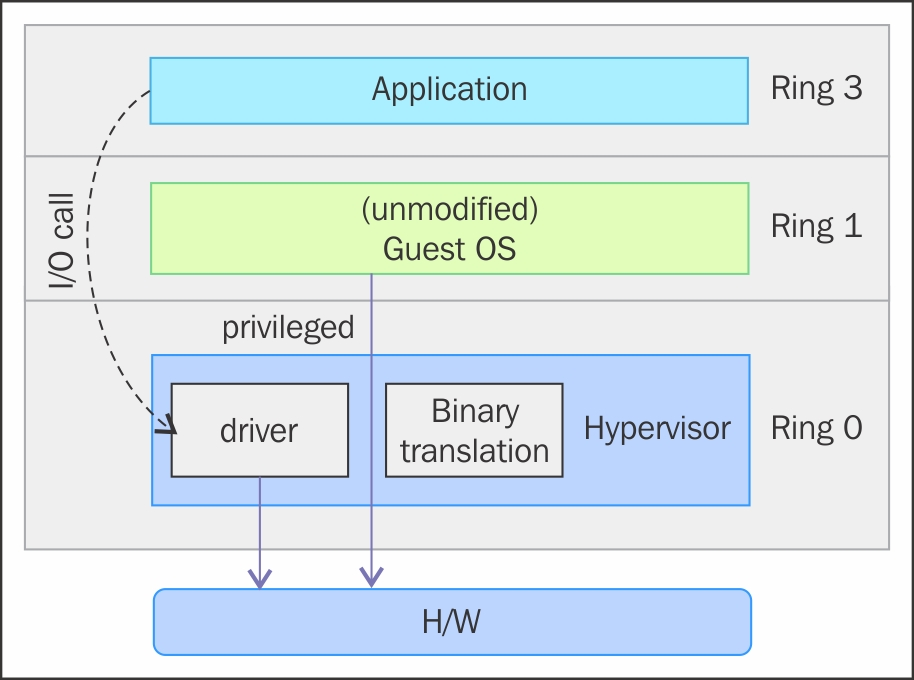
然而,如前面的图像所示,当我们使用全虚拟化时,我们可以使用未修改的客户操作系统。这意味着我们不必改变运行在VMM上的Guest OS 内核。当Guest OS内核执行特权操作时,VMM提供CPU仿真来处理和修改受保护的CPU操作,但是正如前面提到的,与其他虚拟化模式(称为半虚拟化)相比,这会将导致较大的性能开销。
半虚拟化
在半虚拟化中,需要对Guest OS进行修改,以允许这些指令访问ring 0。换句话说,OS需要通过修改,以“hypercalls”的方式实现VMM/hypervisor和Guest OS的通信。
NOTE:请注意,我们也可以称VMM为hypervisor。
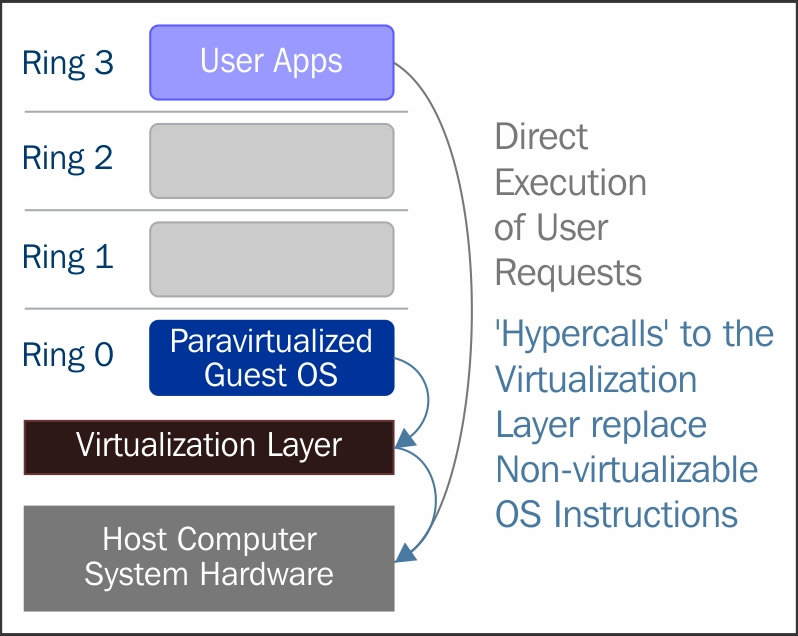
半虚拟化技术中hypervisor提供API接口,经过修改的Guest OS可以调用该接口。特权指令调用与VMM提供的API接口完成信息交换。在这种情况下,修改后的Guest OS可以在ring 0中运行。
正如你所见,在这种技术下Guest 内核需要经过修改而运行在VMM上。换句话说,虚拟化对Guest kernel是可感知的。本应在ring 0中运行的特权指令/操作已经被VMM提供的hypercalls所替代。hypercalls调用VMM执行原本由Guest OS完成的工作。由于Guest kernel有能力通过hypercalls直接与VMM进行通信,因此与全虚拟化相比,这种技术的有更大的性能优势。然而这需要Guest kernel进行定制化以感知半虚拟化技术,需要软件支持。
硬件辅助虚拟化
Intel和AMD意识到x86架构(这本书的范围仅限于x86体系结构中,我们将主要讨论这个架构的演变)全虚拟化和半虚拟化的主要挑战是性能开销问题和虚拟化解决方案在设计与维护上的复杂性。Intel和AMD各自独立地创建了新的x86架构的处理器扩展,分别称为Intel VT-x和AMD-v。在Itanium架构上,硬件辅助虚拟化称为VT-i。硬件辅助虚拟化是一种平台虚拟化技术,旨在有效地利用硬件功能执行全虚拟化。不同的厂商对此技术有不同的命名,包括虚拟化加速、硬件虚拟机和原生虚拟化。
为了更好地支持虚拟化,Intel和AMD分别引入了虚拟化技术(VT)和安全虚拟机(SVM),作为IA-32指令集的扩展。这些扩展允许VMM/hypervisor可以在较低的ring中,运行原本需要运行在内核模式下的Guest OS。硬件辅助虚拟化不仅提出了新的指令,还引入了一个新的特权访问级别ring -1,用以运行hypervisor/VMM,因此Guest OS可以在运行在ring 0。此外,在硬件辅助虚拟化下,VMM/hypervisor与前面提到的其他技术相比可以执行更少的工作,从而降低了性能开销。

简单来说,这种虚拟化感知的硬件提供了构建VMM的支持,并确保了客户操作系统的隔离。这有助于实现更好的性能,并避免了虚拟化解决方案设计上的复杂性。现代虚拟化技术利用这个特性提供虚拟化。一个例子是KVM,我们将在本书的范围内详细讨论它。
介绍VMM/hypervisor
顾名思义,VMM或hypervisor是负责监视和控制VM或Guest OS的软件。hypervisor/VMM负责确保不同的虚拟化管理任务,例如提供虚拟硬件、VM生命周期管理、VM迁移、实时分配资源、定义虚拟机管理策略等。VMM/hypervisor还负责有效地控制物理平台资源,例如内存转换和I / O映射。虚拟化软件的主要优点之一是它能够在同一物理系统或硬件上的运行多个客户机。多个客户机系统可以在相同的操作系统或不同的操作系统上。例如,可以有多个Linux Guest OS作为客户机运行在同一物理系统上。VMM负责分配这些Guest OS请求的资源。系统硬件(如处理器、内存等)必须根据它们的配置分配给这些客户操作系统,VMM负责处理这个任务。因此,VMM是虚拟化环境中的一个关键组件。
根据VMM/hypervisor的位置,可以被归类为type 1或type 2型。
Type 1型和Type 2型hypervisor
hypervisor主要被归类为Type 1和Type 2型(基于它们驻留在系统中的位置)。但是对于Type 1和Type 2型hypervisor并没有明确或标准的定义。如果VMM/hypervisor直接运行在硬件之上,它通常被认为是一个Type 1的hypervisor。如果有一个操作系统存在,VMM/hypervisor作为一个单独的层运行,它将被认为是一个Type 2 hypervisor。再一次申明,这个概念是开放的,没有标准的定义。
Type 1型的hypervisor直接与系统硬件交互;它不需要任何主机操作系统。您可以直接将其安装在裸金属系统上,用以运行虚拟机。类型1的管理程序也称为裸金属、嵌入式或原生hypervisor。
oVirt-node是Type 1型的Linux hypervisor的例子。下图提供对Type 1型hypervisor设计概念图:
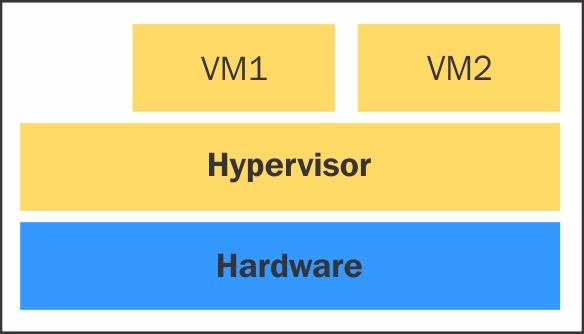
以下是Type 1型hypervisor的优点:
- 易于安装配置
- 体积小,优化以将大部分物理资源提供给托管客户机(虚拟机)
- 开销小,因为它只涉及了运行虚拟机所需的应用程序
- 更安全,因为某个Guest OS的问题不会影响运行在Hypervisor上的其他Guest OS
然而,Type 1 hypervisor不支持自定义。一般情况下,您不能安装任何第三方应用程序或驱动程序。
另一方面,Type 2 hypervisor驻留在操作系统之上,允许您进行大量的自定义。Type 2 hypervisor也被称为hosted hypervisor。Type 2 hypervisor依赖于主机操作系统的操作。Type 2 hypervisor的主要优点是广泛的硬件支持,因为它由底层主机操作系统控制硬件访问。下面的图提供了Type 2 hypervisor设计概念的说明:
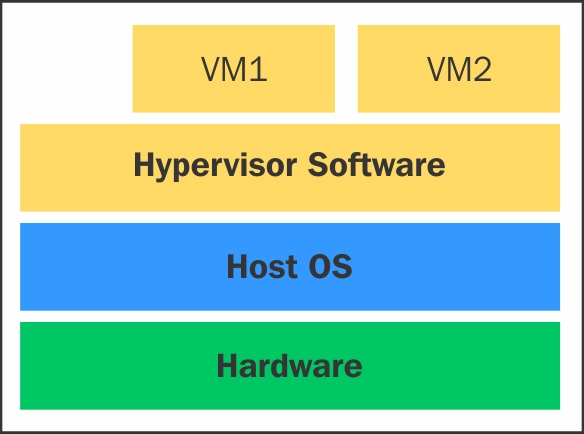
决定使用哪一类hypervisor主要取决于您在何处部署虚拟化的基础设施。
还有一点是,与Type 2 hypervisor相比,Type 1 hypervisor执行性能更好,因为它们直接运行在硬件之上。没有对Type 1和Type 2 hypervisor的正式定义,评估性能没有多大意义。
开源虚拟化项目
下表列出了Linux中的开源虚拟化项目:
| Project | Virtualization Type | Project URL |
| KVM (Kernel-based Virtual Machine) | Full virtualizatio | http://www.linux-kvm.org/ |
| VirtualBox | Full virtualizatio | https://www.virtualbox.org/ |
| Xen | Full and paravirtualization | http://www.xenproject.org/ |
| Lguest | Paravirtualization | http://lguest.ozlabs.org/ |
| UML (User Mode Linux) | http://user-mode-linux.sourceforge.net/ | |
| Linux-VServer | http://www.linux-vserver.org/Welcome_to_Linux-VServer.org |
在接下来的部分中,我们将讨论Xen和KVM,这是Linux中领先的开源虚拟化解决方案。
XEN
Xen起源于剑桥大学的一个研究项目,第一版在2003年正式对外发布。之后,剑桥大学负责这个项目的主管,Lan Pratt,与另外一位来自剑桥大学的Simon Crosby合作创办了公司XenSource。这家公司开始以开源的方式开发这个项目。在2013年4月15日,Xen作为一个协作项目被移入Linux基金会。Linux基金会为Xen项目推出了一个新商标,以区分该项目与旧Xen商标的任何商业用途。更多细节可以在xenproject.org网站找到。
Xen hypervisor已经移植到一些处理器家族中,例如,Intel IA-32/64,x86_64,PowerPC,ARM,MIPS等等。
Xen可以在半虚拟化和硬件辅助或全虚拟化(HVM)上运行,HVM允许运行未经修改的Guest。Xen hypervisor运行Guest OS的组件称为Domains。在XEN中主要有两种类型的Domains:
- Dom 0
- Dom U
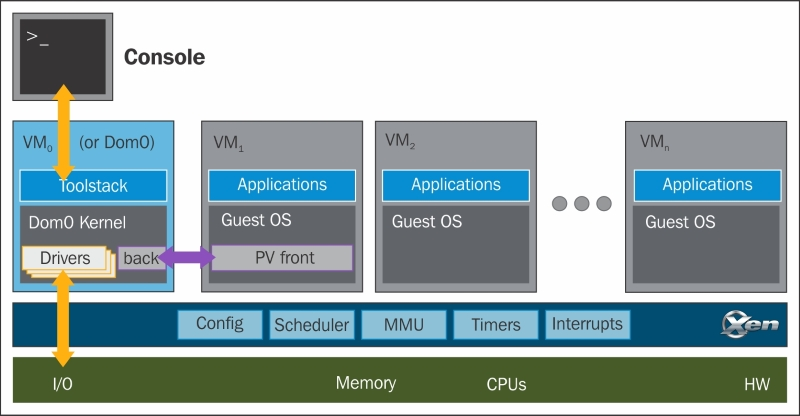
Dom U是无特权域或客户系统(guest system)。Dom 0也被称为特权域或特殊客户(special guest),具有扩展功能。Dom U由Dom 0管理。Dom 0包含系统中所有设备的驱动程序。Dom 0还包含一个控制堆栈来管理虚拟机的创建、销毁和配置。Dom 0还具有直接访问硬件的特权;它可以处理对系统I/O功能的所有访问,并可以与其他虚拟机进行交互。Dom 0设置Dom Us,使用虚拟驱动与硬件设备通信。Dom 0对外提供控制接口,可以通过该接口控制整个系统。Dom 0是系统启动的第一个VM,是Xen hypervisor的必备域。
KVM简介
基于内核的虚拟机(KVM)代表了最新的开源虚拟化技术。这个项目的目标是创建一个现代化的hypervisor,它建立在前几代技术的经验之上,并利用当今可用的现代硬件技术(VT-x,AMD-v)。
当您安装了KVM内核模块,KVM轻松的将Linux内核转换为一个hypervisor。尽管如此,由于hypervisor是一个标准的Linux内核,使得它可以从标准内核的更新中受益(内存支持,调度等)。对这些Linux组件的优化(如3.1内核中的新调度器)不仅让hypervisor从中受益,也有利于Linux Guest OS。在I/O仿真方面,KVM使用了一个用户态软件QEMU;Qemu是一个负责硬件仿真的用户程序。
它负责模拟处理器和一长串外围设备:磁盘、网络、VGA、PCI、USB、串口/并行端口等,从而构建一个完整的虚拟硬件,可以安装Guest OS,并通过KVM的支持变得更加强大。
KVM的高级概述
下图给出了KVM的用户模式和内核模式组件的高级概述:
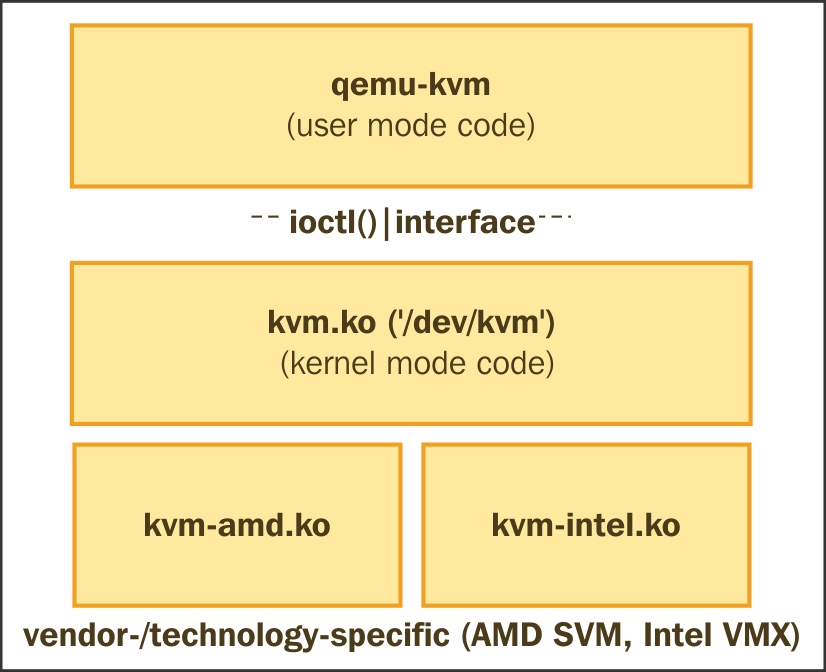
在系统管理实用程序(如virsh和virt-manager)的请求下,libvirtd为每个虚拟机启动了一个单独的qemu-kvm进程。虚拟机的属性(cpu数量、内存大小、I/O设备配置)是在单独的XML文件中定义的,这些文件位于/etc/libvirt/qemu目录中,libvirtd使用这些XML文件的详细信息来传递给qemu-kvm进程的参数列表。举例:
qemu 14644 9.8 6.8 6138068 1078400 ? Sl 03:14 97:29 /usr/bin/qemu-system-x86_64 -machine accel=kvm -name guest1 -S -machine pc--m 5000 -realtime mlock=off -smp 4,sockets=4,cores=1,threads=1 -uuid 7a615914-ea0d-7dab-e709-0533c00b921f -no-user-config -nodefaults -chardev socket,id=charmonitor-drive file=/dev/vms/hypervisor2,if=none,id=drive-virtio-disk0,format=raw,cache=none,aio=native -device id=net0,mac=52:54:00:5d:be:06
在此处,类似于-m 5000的一个参数为虚拟机指定了5GB的内存,--smp=4指定了4个vCPU,它的拓扑结构为四个vSocket,每个Socket有一个核心。
关于libvirt和qemu是什么以及它们是如何相互通信的详细内容,将在第2章中进行了解释。
在云计算中Linux虚拟化可以提供什么
多年来,Linux已经成为开发云计算方案的首选。许多成功的公共云提供商使用Linux虚拟化来为底层基础设施提供助力。例如,亚马逊(Amazon)是最大的IaaS云提供商,它使用Xen虚拟化来为其EC2提供动力,同样KVM为Digital Ocean的发展提供了助力。Digital Ocean是世界上第三大云供应商。Linux虚拟化同样也在私有云领域占据主导地位。
以下是使用Linux虚拟化构建IaaS软件的开源云软件的列表:
- Openstack:一个完全开源的云操作系统,它由几个开放源码子项目组成,这些子项目提供了所有的组件来创建IaaS云。KVM(Linux虚拟化)是OpenStack部署中使用最多的(也是支持最好的)hypervisor。它是由供应商无关的OpenStack基金会管理的。在第六章,虚拟机生命周期管理和第7章,模板和快照中,详细解释了如何使用KVM构建OpenStack云。
- Cloudstack:这是另一个开放源码的Apache Software Foundation(Apache软件基金会,ASF)控制的云项目,以构建和管理高度可伸缩的多租户IaaS云,它完全兼容EC2/S3 API。尽管它支持所有顶级Linux hypervisor。大多数Cloudstack用户选择Xen,因为它与Cloudstack紧密地集成在一起。
- Eucalyptus:这是一个兼容aws的私有云软件,用于降低公共云成本,并获得对安全性和性能的控制。它支持Xen和KVM作为计算资源提供者。
概要
在本章中,您了解了Linux虚拟化、它的优点以及不同类型的虚拟化方法。我们还讨论了hypervisor的类型,然后介绍了Xen和KVM的高级架构,以及流行的开源Linux虚拟化技术。
在下一章中,我们将讨论libvirt、qemu和KVM的内部工作机理,并了解这些组件如何相互通信以实现虚拟化。