目录:
- 网站分析
- 爬取下载链接
- 爬取TIFF图片
1、网站分析
主页面:https://neo.sci.gsfc.nasa.gov/view.php?datasetId=MYDAL2_M_AER_OD
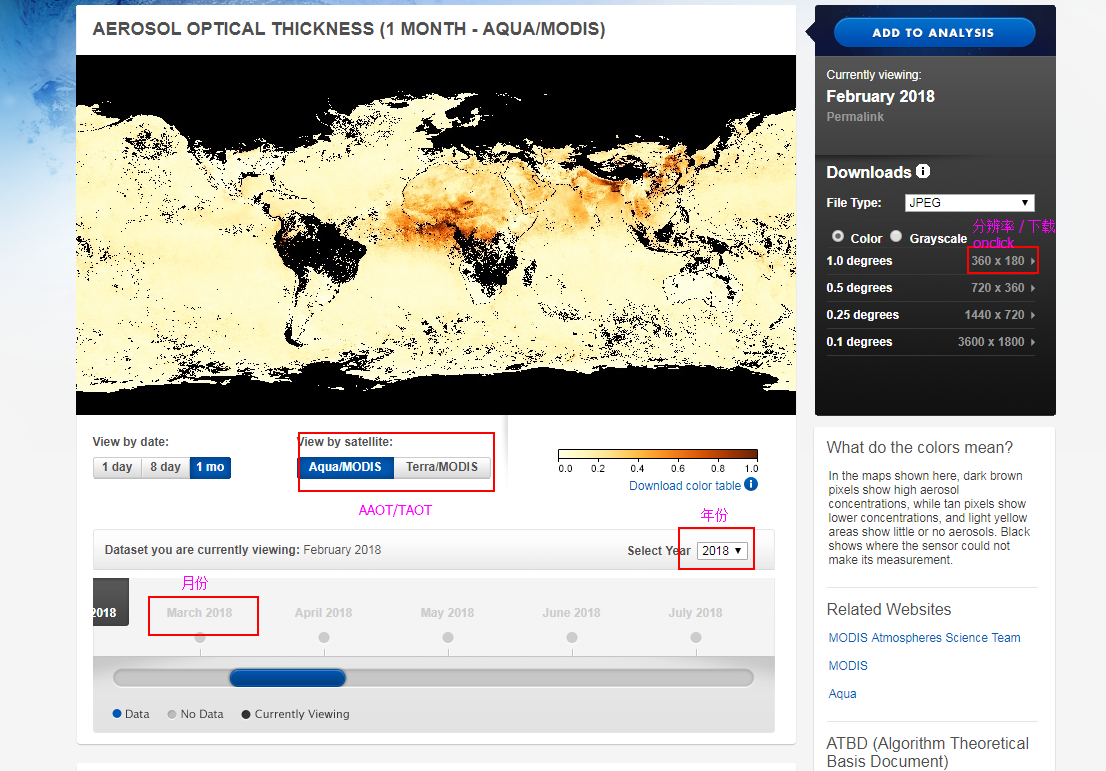
需求:下载不同年份、不同月份、AAOT和TAOT数据;
点击AAOT和TAOT和年份可知,链接:
AAOT:https://neo.sci.gsfc.nasa.gov/view.php?datasetId=MYDAL2_M_AER_OD&year=2018
TAOT:https://neo.sci.gsfc.nasa.gov/view.php?datasetId=MODAL2_M_AER_OD&year=2018
AAOT和TAOT的区分:改变MYD和MOD;
年份区分:改变“year=”后面的数字;
月份如何区分?
点击下载处,链接为:
https://neo.sci.gsfc.nasa.gov/servlet/RenderData?si=1744422&cs=rgb&format=FLOAT.TIFF&width=360&height=180
https://neo.sci.gsfc.nasa.gov/servlet/RenderData?si=1618332&cs=rgb&format=FLOAT.TIFF&width=360&height=180
可知在下载链接里面“si=”后面的数字是不知道的,查看源代码,检查上图中月份处,发现这个数字就在这里:这个就是月份区分

分析完毕,爬取思路:
- 根据月份检查元素获取图片下载链接中的“si”,构建所有的下载链接;
- 下载已爬取的下载链接中的TIFF图片
2、爬取下载链接
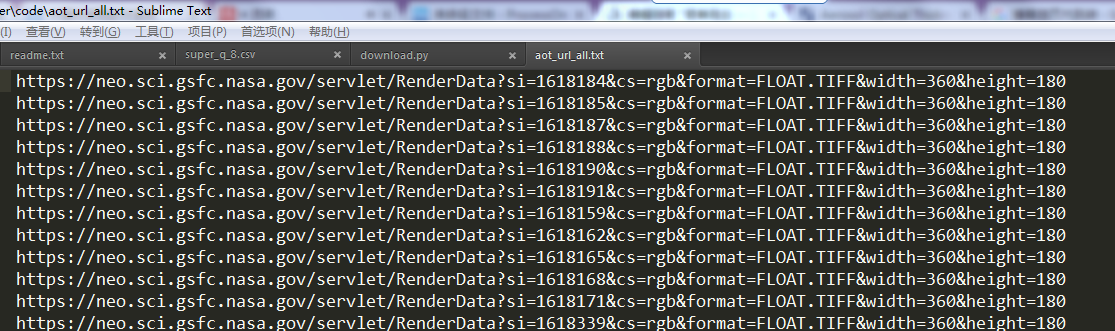
由以上的分析,代码如下,这里爬取的是2008-2011的AAOT和TAOT数据链接:
1 import requests 2 from bs4 import BeautifulSoup as bsp 3 4 def url_collect(): 5 // 两个主链接 6 taot_main_url = 'https://neo.sci.gsfc.nasa.gov/view.php?datasetId=MODAL2_M_AER_OD&year=' 7 aaot_main_url = 'https://neo.sci.gsfc.nasa.gov/view.php?datasetId=MYDAL2_M_AER_OD&year=' 8 9 // 需要下载的年份 10 years = ['2011', '2010', '2009', '2008'] 11 12 // 构造确定AOT类别和年份页面链接 13 aot_url_list = [] 14 for year in years: 15 aot_url_list.append(taot_main_url + year) 16 aot_url_list.append(aaot_main_url + year) 17 18 for aot_url in aot_url_list: 19 // 请求获取网页 20 try: 21 response = requests.get(aot_url) 22 response.raise_for_status() 23 print('aot_url connect succeed !') 24 except: 25 print('aot_url connect failed !') 26 27 // 分析网页,获取代表月份的“si=”后面的数字 28 response_text = response.text 29 soup = bsp(response_text, 'html.parser') 30 divs = soup.find_all('div',{"class":"slider-elem month"}) 31 32 // 创建保存链接和命名形式的文件 33 url_txt = open('D:/home/research/lung_cancer/code/aot_url_all.txt', 'a') 34 url_name_txt = open('D:/home/research/lung_cancer/code/url_name.txt', 'a') 35 36 // 构造下载链接和命名形式,并保存到文件中 37 for div in divs: 38 print(div) 39 aot_url_txt = 'https://neo.sci.gsfc.nasa.gov/servlet/RenderData?si=' + div.a['onclick'][13:20] + '&cs=rgb&format=FLOAT.TIFF&width=360&height=180' 40 name = aot_url.split('?')[1][10:] + div.a['onclick'][27:-3] + '.TIFF' 41 url_txt.write(aot_url_txt + ' ') 42 url_name_txt.write(name + ' ')
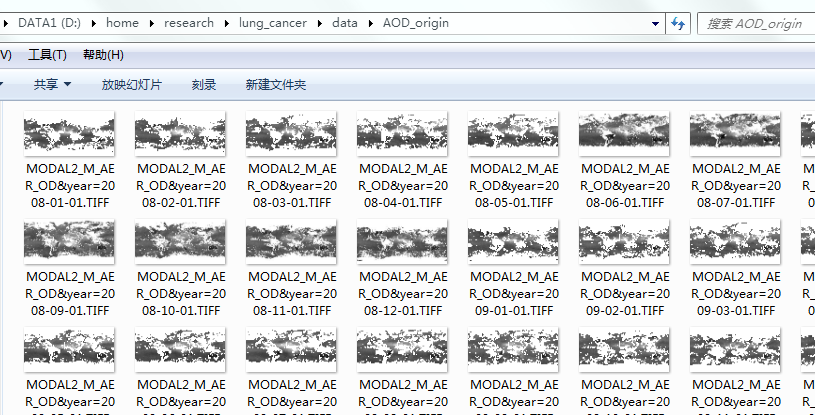
以下是爬取的结果:
Q:为什么要把命名形式也写入文件?
A:因为下载文件时,发现命名形式并不固定,有时候包含了年、月和AOT类别,有时候就是个简单的RenderData.TIFF,这样文件下载下来了也不知道是什么数据,所以命名很重要。
3、爬取TIFF图片
根据上一步爬取下来的链接,就可开始爬取图片了:
1 # code : utf-8 2 3 """ 4 下载指定链接(在文本文件中)下的tiff图像 5 """ 6 7 import requests 8 9 def download(): 10 local_path = 'D:/home/research/lung_cancer/code/' 11 12 // 读取文本文件中已经下载好的链接 13 url_list = [] 14 with open(local_path + 'aot_url_all.txt', 'r') as f: 15 for url in f.readlines(): 16 url_list.append(url.strip()) 17 18 // 读取命名形式 19 name_list = [] 20 with open(local_path + 'url_name.txt', 'r') as f: 21 for name in f.readlines(): 22 name_list.append(name.strip()) 23 24 // 获取以上链接中的TIFF文件 25 for i in range(len(url_list)): 26 url = url_list[i] 27 name = name_list[i] 28 29 try: 30 response = requests.get(url) 31 response.raise_for_status() 32 print('main_url connect succeed !') 33 except: 34 print('main_url connect failed !') 35 36 // 将文件写入本地硬盘 37 with open('D:/home/research/lung_cancer/data/AOD_process/' + name, 'wb') as f: 38 f.write(response.content) 39 print(name + "write succeed!")
爬取结果: