一、快速排序:
快速排序和其他排序方法一样,都是为了将数据进行简洁又快速的排序。
其基本的实现方法其实就是经过一次排序算法之后,先简单地将数据分成两部分:取一个中间数(一般为第一个元素),以这个中间数为中心,左边的数为比这个中间数小的数,右边的数为比这个中间数大的数。之后再进行递归算法,分别处理已经分好的以中间数为分界的左右两堆数据。直到最后得到我们想要的排好序的数组。
基本步骤:
1.先确定一个对比数(中间数),一般为第一个元素。
2.取两个变量i、j,i为下标的数字为这个数组的第一个元素,j为下标的数字为这个数组的最后一个元素。
3.首先从后向前开始进行比较,即最后一个元素与中间数比较,如果最后一个元素的值大于第一个元素,j--,继续进行比较,如果j为下标的元素的值小于第一个元素,将j为下标的元素的值赋给i为下标的元素。结束这一次比较。
4.开始从前往后进行比较,如果第一个数的值小于中间数,i++,接着进行比较,如果i为下标的元素的值大于中间数,将这个数字的值赋给j为下标的元素。结束这一次比较。
5.重复3和4步骤,直至i>=j。
文字的表述可能不是很形象,很多人还是不能理解,我们用图来进行说明。
(1)
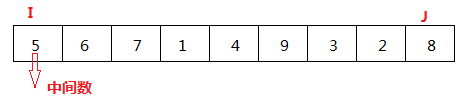
这是给定的最初始的数组,我们先确定一个中间数,把第一个元素设成中间数,I标识数组的第一个元素的下标,J标识数组最后一个元素的下标。
(2)
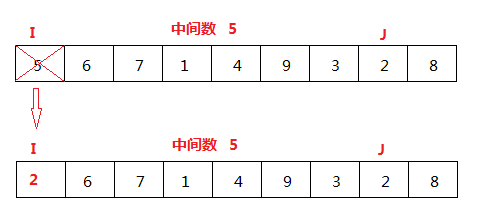
I<J,从J为下标的数字开始比较,8比中间数大,J--,2比中间数小,将J为下标的元素的值赋给I为下标的元素,如图,此时完成一次比较。
(3)
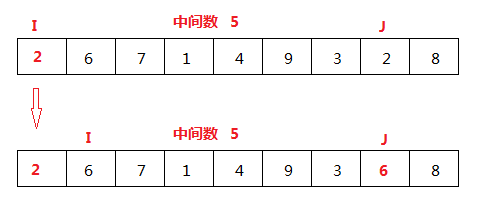
I<J, 完成一次J开始的比较之后,从I为下标的元素进行比较,2小于中间数,I++,6大于中间数,将I为下标的元素的值赋给J为下标的元素,如上图,完成一次比较。
I<J, 完成一次J开始的比较之后,从I为下标的元素进行比较,2小于中间数,I++,6大于中间数,将I为下标的元素的值赋给J为下标的元素,如上图,完成一次比较。
(4)
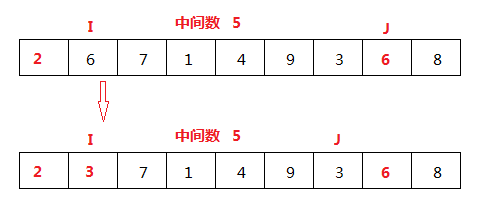
I<J, 继续从J开始进行比较,3比中间数小,赋值给I为下标的元素,结束一次比较。
(5)
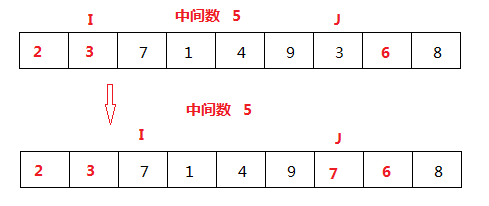
I<J, 继续从I开始比较,7比中间数大,赋值给J为下标的元素,结束一次比较。
(6)
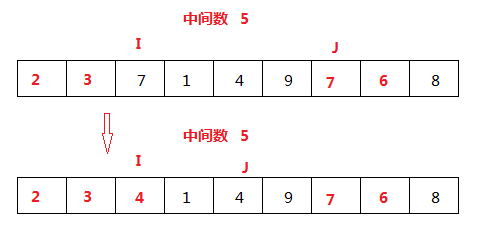
I<J,继续从J开始比较,4比中间数小,赋值给I为下标的元素,结束一次比较。
(7)
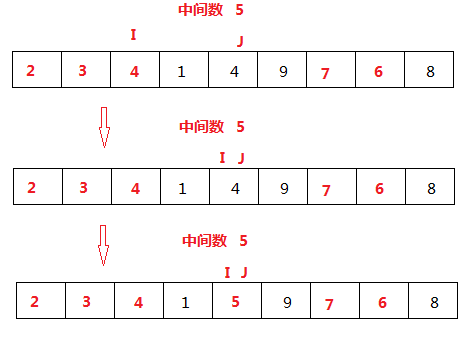
再次从I开始进行比较,当I=J的时候,停止比较。
将中间数赋值给I为下标的元素,结束一轮的比较。
从上图可以看到:当完成一次快速排序之后,在中间数左边的数都比中间数小,而在中间数右边的数都比中间数大。之后依次对左边和右边的数据进行快速排序,递归运算,最后得到我们所要的结果。
二、冒泡排序
冒泡排序原理:冒泡排序其实就是从头开始对整个数列里面的元素进行两两对比,比较大的元素放到后面,接着进行对比,直到最大的一个元素被提取出来放到整个数列的最后。接着再对剩下的元素进行相同的操作,直到整个数列被排序完成。其实冒泡排序的原理很简单,之所以被称为金典的排序算法,其实是因为它对for循环的利用,这个我们之后可以从代码里面看到。
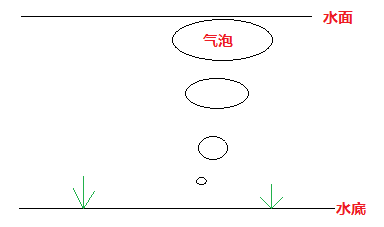
简单地用一幅图来解释:最大的元素就和气泡一样,从底往上冒出来。
同样,我们用图来进行说明,以下为进行比较的步骤和操作。
(1)

1和6进行比较,6大于1,不进行交换,进入到下一对比较。
(2)

6和9进行比较,9大于6,不进行交换,进入到下一对比较。
(3)
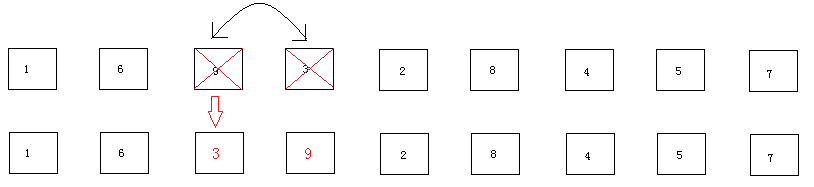
3和9进行比较,3小于9,进行交换,交换完毕进入到下一轮比较。
(4)

之后分别依次两两进行比较,9与2、8、4、5、7比较后来到最后的位置,这时候9就是最大的一个元素。到此,完成一次冒泡,之后再一一进行冒泡,直到整个数列排序完成。