一、 安装
- 安装ElasticSearch(版本:7.6.2)
- 安装Kibana(版本:7.6.2)
- 安装LogStash(版本:7.6.2)
- 安装RabbitMQ
二、 部署
- 配置并启动ES
ES安装目录
JDK配置
ElasticSearch官方文档指出ES7.6.2需要JDK11的环境支持,因此ES7.6.2自带了JDK11(经过测试发现在JDK1.8的环境下运行会报warning但也可以正常运行)。
因为本地常用的JDK是1.8版本的,所以建议使用自带的JDK11,这样可以不用修改本地的%JAVA_HOME%环境变量。配置如下:
找到/bin/elasticsearch-env.bat,大概在39行的位置。将其关于JAVA环境的判断语句注释掉,只保留else中的语句,如下

找到/config/jvm.options,大概在22行位置可以配置虚拟机内存分配大小,在35行位置配置GC参数(这里根据你的JDK版本进行配置),如下:
![]()

ElsticSearch配置
在/config/elsticsearch.yml文件中进行配置,如下:

以上配置为单节点ES部署配置,若要部署集群,则还需配置节点名称等属性,如下:


IK分词器
下载elasticsearch-analysis-ik-7.6.2(版本必须与ES保持一致)。将ik分词器文件夹放入ES安装目录下的plugins即可,如下:
注:
ik分词器中可以使用配置文件在按中文基本逻辑自动分词的基础上,配置特定的分词。elasticsearch-analysis-ik-7.6.1/config/IKAnalyzer.cfg.xml文件中配置如下:

启动ElasticSearch
打开cmd命令行运行/bin/elasticsearch.bat批处理文件(也可双击运行)。

出现如下插件表示ik分词器安装成功。

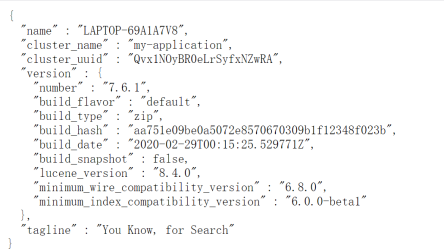
启动完成后打开浏览器访问http://localhost:9200,得到如下响应表示ES成功启动。
- 配置并启动Kibana
打开Kibana安装目录下 config/kibana.yml,配置如下:

配置完成后,打开cmd或直接双击运行bin/kibana.bat

运行成功后,使用浏览器访问http://localhost:5601 显示kibana操作界面即启动成功。
点击如图按钮进入开发工具。左边界面编辑请求,右边界面展示结果。
- 下载logstash7.6.2并解压
Logstash导入数据需要先在ES创建索引库,因此暂时不用启动。Logstash安装目录如下:

三、 操作
- 使用Kibana操作ES
1) 索引库相关操作
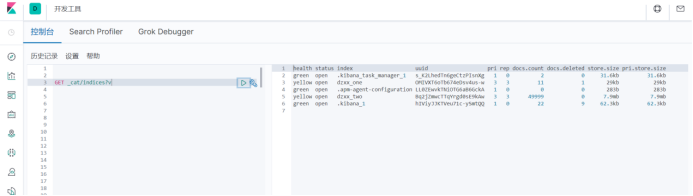
① 查询索引详细信息:GET _cat/indices?v

查询结果:

health:索引健康状态(green、yellow、red)
status:索引状态
index:索引名称
uuid:唯一表示id
pri:分片数
rep:备份数
docs.count:可查询文档数量
docs.deleted:标记为已删除文档数量
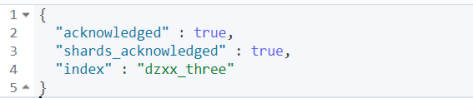
② 创建索引库:

ES主要有text(分词字符串)、keyword(不分词字符串)、integer、long、date等数据类型。运行结果如下即创建索引库成功:
③ 查询索引库
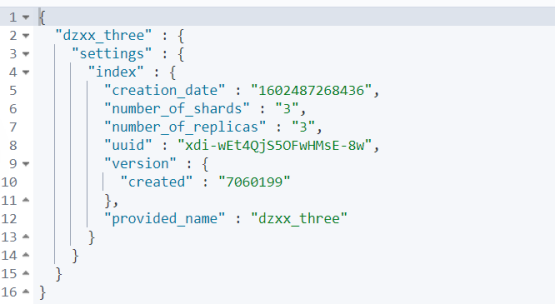
查询索引库配置:GET 索引库名称/_settings

查询结果
查询索引库映射:GET 索引库名称/_mapping

查询结果:

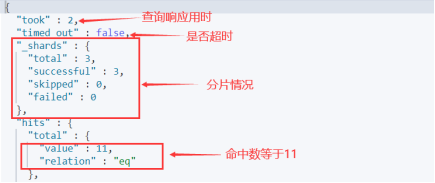
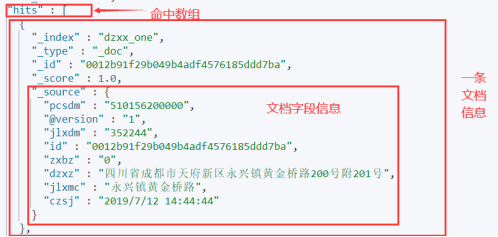
查询所有文档:GET 索引库名称/_search

查询结果:
④ 删除索引:DELETE 索引名称

如下结果表示删除成功:

2) 文档相关操作
①创建文档
使用自己的ID创建:
PUT {index}/{type}/{id}
{
"field": "value",
...
}
ES内置ID创建:
POST {index}/{type}/
{
"field": "value",
...
}
②获取文档:GET {index}/{type}/{id}

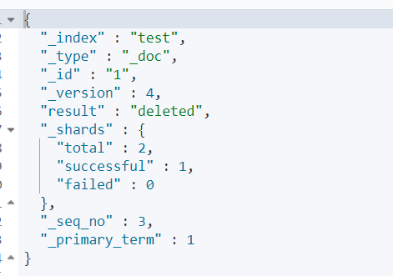
③删除文档:DELETE{index}/{type}/{id}
3) DSL查询与过滤
①全匹配(match_all)
普通搜索(匹配所有文档):
{
"query" : {
"match_all" : { }
}
}
一个较为完整的查询语句:
GET _search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": {
"term": {
"name": "zs1"
}
}
}
}
}
② 标准查询(match和multi_match)
match查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。
如果你使用match查询一个全文本字段,它会在真正查询之前用分析器先分析查询字符:
{
"query": {
"match": {
"fullName": "Steven King"
}
}
}
上面的搜索会对Steven King分词,并找到包含Steven或King的文档,然后给出排序分值。
如果用 match下指定了一个确切值,在遇到数字,日期,布尔值或者 not_analyzed的字符串时,它将为你搜索你给定的值,如:
{ "match": { "age": 26 }}
{ "match": { "date": "2014-09-01" }}
{ "match": { "public": true }}
{ "match": { "tag": "full_text" }}
multi_match 查询允许你做 match查询的基础上同时搜索多个字段:
{
"query":{
"multi_match": {
"query": "Steven King",
"fields": [ "fullName", "title" ]
}
}
}
上面的搜索同时在fullName和title字段中匹配。
提示:match一般只用于全文字段的匹配与查询,一般不用于过滤。
③单词搜索与过滤(Term和Terms)
{
"query": {
"bool": {
"must": {
"match_all": {}
},
}
"filter": {
"term": {
"tags": "elasticsearch"
}
}
}
}
Terms搜索与过滤
{
"query": {
"terms": {
"tags": ["jvm", "hadoop", "lucene"],
"minimum_match": 2
}
}
}
minimum_match:至少匹配个数,默认为1
④ 组合条件搜索与过滤(Bool)
组合搜索bool可以组合多个查询条件为一个查询对象,查询条件包括must、should和must_not。
例如:查询爱好有美女,同时也有喜欢游戏或运动,且出生于1990-06-30及之后的人。
{
"query": {
"bool": {
"must": [{"term": {"hobby": "美女"}}],
"should": [
{"term": {"hobby": "游戏"}},
{"term": {"hobby": "运动"}}
],
"must_not": [
{"range" :{"birth_date":{"lt": "1990-06-30"}}}
],
"filter": [...],
"minimum_should_match": 1
}
}
}
Hobby=美女 and (hobby=游戏 or hobby=运动) and birth_date >= 1990-06-30
提示: 如果 bool 查询下没有must子句,那至少应该有一个should子句。但是 如果有 must子句,那么没有 should子句也可以进行查询。
⑤ 范围查询与过滤(range)
range过滤允许我们按照指定范围查找一批数据:
{
"query":{
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}
}
上例中查询年龄大于等于20并且小于30。
gt:> gte:>= lt:< lte:<=
⑥ 存在和缺失过滤器(exists和missing)
{
"query": {
"bool": {
"must": [{
"match_all": {}
}],
"filter": {
"exists": { "field": "gps" }
}
}
}
}
提示:exists和missing只能用于过滤结果。
⑦ 前匹配搜索与过滤(prefix)
和term查询相似,前匹配搜索不是精确匹配,而是类似于SQL中的like ‘key%’
{
"query": {
"prefix": {
"fullName": "倪"
}
}
}
上例即查询姓倪的所有人。
⑧ 通配符搜索(wildcard)
使用*代表0~N个,使用?代表1个。
{
"query": {
"wildcard": {
"fullName": "倪*华"
}
}
}
- 使用Logstash连接ElasticSearch
1)初始化导入csv文件数据
①windows环境下:
准备好.csv格式的数据文件,文件必须从第一行开始即为数据,且不能有空行。然后在logstash安装目录/bin目录下创建logstash.conf配置文件,内容如下:
input {
file {
path => "D:/two.csv"
start_position => "beginning"
}
}
filter {
csv {
separator => ","
columns => ["dzxz","id","jlxdm","jlxmc","pcsdm","zxbz","czsj"]
}
mutate {
remove_field => ["path", "host","@timestamp","message","content"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "dzxx_one"
document_id => "%{id}"
}
stdout {}
}

在/bin目录下打开cmd命令行,输入命令:logstash -f logstash.conf
运行
注:windows环境下运行时,可能会卡顿,将导入的.csv文件打开,在末尾添加一行空行,保存,再删除空行,保存,即可开始导入数据。
②linux环境下:
1. 搞定Logstash7.6.2镜像:

2.守护式启动容器 :docker run -di --name=mylogstash7.6.2 logstash:7.6.2
进入容器: docker exec -it mylogstash7.6.2 /bin/bash
进入容器后在 /usr/share/logstash/config 目录下找到logstash.yml 和pipelines.yml配置文件,在/usr/share/logstash/pipeline目录下找到logstash.conf配置文件
3.将上述文件配置好后 拷贝至容器内,并覆盖:docker pc 本机目录 容器id:容器目录
4.修改完毕后生成新的镜像:
docker commit -a=’a_info’ -m=’m_info’ 容器id mylogstash7.6.2
5.启动logstash,并将csv文件挂载至容器目录中:
docker run --restart=always --name=logstash7.6.2 -v /root/dzxt-data/1100.csv:/usr/share/logstash/data.csv mylogstash
logstash.yml:
http.host: "0.0.0.0"
xpack.monitoring.enabled: true
xpack.monitoring.elasticsearch.hosts: ["https://localhost:9200"]
pipelines.yml:
- pipeline.id: logstash_test
path.config: "/usr/share/logstash/pipeline/logstash.conf"

logstash.conf:
input {
file {
path => "/usr/share/logstash/1001.csv"
start_position => "beginning"
}
}
filter {
csv {
separator => ","
columns => ["dzxz","id","jlxdm","jlxmc","pcsdm","zxbz","czsj"]
}
mutate {
remove_field => ["path", "host","@timestamp","message","content"]
}
}
output {
elasticsearch {
hosts => "http://10.64.39.146:9200"
index => "dzxx_test"
document_id => "%{id}"
}
stdout {}
}

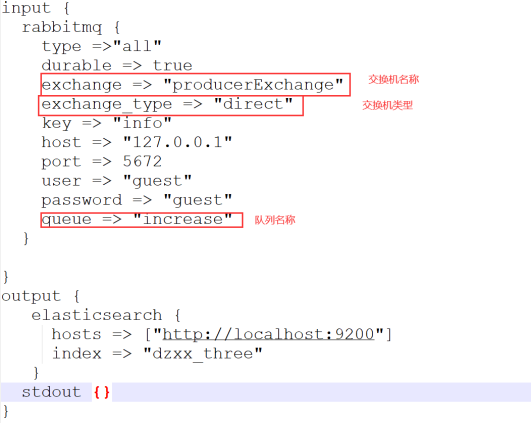
2)使用RabbitMQ进行增量导入
同上,修改logstash.conf文件:
input {
rabbitmq {
type =>"all"
durable => true
exchange => "producerExchange"
exchange_type => "direct"
key => "info"
host => "127.0.0.1"
port => 5672
user => "guest"
password => "guest"
queue => "increase"
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "dzxx_three"
}
stdout {}
}