使用深度学习模型时当然希望可以保存下训练好的模型,需要的时候直接调用,不再重新训练
一、保存模型到本地
以mnist数据集下的AutoEncoder 去噪为例。添加:
file_path="MNIST_data/weights-improvement-{epoch:02d}-{val_loss:.2f}.hdf5"
tensorboard = TensorBoard(log_dir='/tmp/tb', histogram_freq=0, write_graph=False) checkpoint = ModelCheckpoint(filepath=file_path,verbose=1,monitor='val_loss', save_weights_only=False,mode='auto' ,save_best_only=True,period=1)
autoencoder.fit(x_train_noisy, x_train, epochs=100, batch_size=128, shuffle=True, validation_data=(x_test_noisy, x_test), callbacks=[checkpoint,tensorboard])
这里的tensorboard和checkpoint分别是
1、启用tensorboard可视化工具,新建终端使用tensorboard --logdir=/tmp/tb 命令
2、保存ModelCheckpoint到MNIST_data/文件夹下,这里的参数设置为观察val_loss ,当有提升时保存一次模型,如下


二、从本地读取模型
假设读取模型后使用三个图片做去噪实验:(测试的图片数量修改 pic_num )
import os import numpy as np from warnings import simplefilter simplefilter(action='ignore', category=FutureWarning) import matplotlib.pyplot as plt from keras.models import Model,Sequential,load_model from keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D from keras.preprocessing.image import ImageDataGenerator,img_to_array, load_img from keras.callbacks import TensorBoard , ModelCheckpoint print("_________________________keras start_____________________________") pic_num = 3 base_dir = 'MNIST_data' #基准目录 train_dir = os.path.join(base_dir,'my_test') #train目录 validation_dir="".join(train_dir) test_datagen = ImageDataGenerator(rescale= 1./255) validation_generator = test_datagen.flow_from_directory(validation_dir, target_size = (28,28), color_mode = "grayscale", batch_size = pic_num, class_mode = "categorical")#利用test_datagen.flow_from_directory(图像地址,目标size,批量数目,标签分类情况) for x_train,batch_labels in validation_generator: break x_train = np.reshape(x_train, (len(x_train), 28, 28, 1)) y_train = x_train # create model model = load_model('MNIST_data/my_model.hdf5') model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) print("Created model and loaded weights from file") # estimate accuracy on whole dataset using loaded weights y_train=model.predict(x_train) n = pic_num for i in range(n): ax = plt.subplot(2, n, i+1) plt.imshow(x_train[i].reshape(28, 28)) plt.gray() ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) ax = plt.subplot(2, n, i+1+n) plt.imshow(y_train[i].reshape(28, 28)) plt.gray() ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) plt.show()
迭代67次效果:
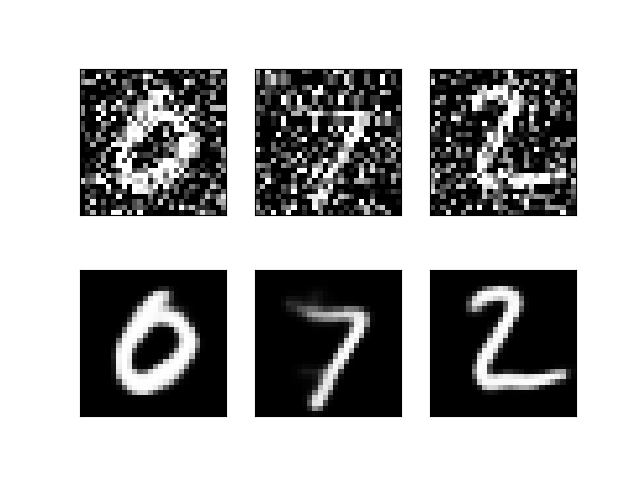
参考:
https://keras-zh.readthedocs.io/getting-started/faq/#_3