经常有人问我有关“大数据”的问题,而且多半情况下我们似乎是在各种不同的抽象和理解级别进行交谈。实时 和高级分析 之类的词语频频现身,并且我们总是立即开始谈论产品,这通常并不是一个好主意。
|
因此我们来回顾一下,从一个用例的角度出发来看看大数据的含义,然后我们可以将该用例与一个可用的高级基础架构图对应起来。这些全部完成之后,(我希望)您将开始看到一种模式并开始了解实时 和分析 之类的词的适用场合。
业务方面的用例
我不打算从头开始发明什么,而是观察了描述 Smartmall 的主题演讲用例(在该视频中您可以看到一个智能商城的漂亮动画和说明)。
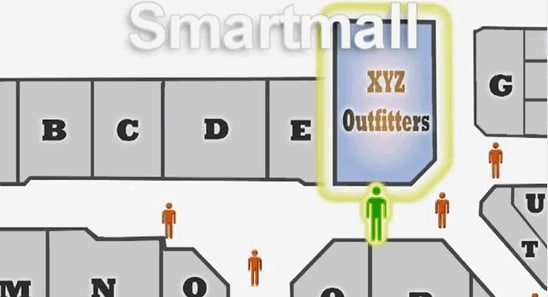
图 1. Smartmall
Smartmall 背后的思想通常称为多渠道客户交互,意即“我如何通过其智能手机与我的实体店中的客户交互”?相比要求客户掏出智能手机在互联网上浏览价格,我们宁愿主动推动其行为。
Smartmall 的目标相当直接:
- 提高商城内店铺的流量。
- 增加每次访问和每笔交易的收益。
- 降低只看不买的百分比。
您需要什么?
在技术方面,您可能需要:
- 提供个人相关位置信息的智能设备
- 用于实时交互和分析的数据收集点和决策点
- 用于面向批处理的分析的存储和处理工具
在数据集方面,您可能至少需要:
- 与个人和个人识别设备(电话、会员卡等)相关联的客户个人信息
- 与详细的购买行为相关联并与优惠券使用、首选产品及其他产品推荐等要素相关联的非常细粒度的客户细分
高级组件
一图胜千言,图 2 同时显示了实时决策基础架构以及批量数据处理和模型生成(分析)基础架构。
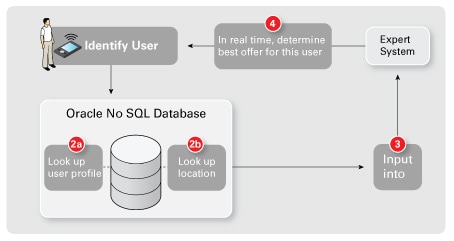
图 2. 示例基础架构
第一步,这个理论上最重要的一步,以及最重要的数据块关乎客户身份识别。在本例中,第 1 步是携带智能电话的用户走进商城这一实际情况。通过识别这一情况,我们触发第 2a 步和第 2b 步中在用户个人信息数据库中的查询。
我们稍后将略微详细地讨论这一点,一般来说,这是一个利用索引结构来快速、高效执行查询的数据库。一旦查找到实际客户,就将此客户的个人信息提供给我们的实时专家系统(第 3 步)。
该专家系统(定制的软件或 COTS 软件)中的模型评估提供的数据和个人信息并决定要采取的行动(如发送优惠券)。所有这些都是实时发生的,记住,网站只需数毫秒即可完成这项工作,而我们的智能商城在 1 秒左右完成这项工作就可以了。
为了构建精确的模型(许多典型的大数据热门词汇正是来源于此),我们在图中添加一个面向批处理的大规模处理场。图 3 下半部分显示如何利用包括 Apache Hadoop 和 Apache Hadoop 分布式文件系统 (HDFS) 在内的一组组件来创建购买行为模型。传统上,我们利用数据库(或数据仓库 [DW])来实现这一目的。现在我们还是这样,但现在我们在数据库/数据仓库之前利用一个基础架构来跟踪更多数据并不断地重新评估所有数据。
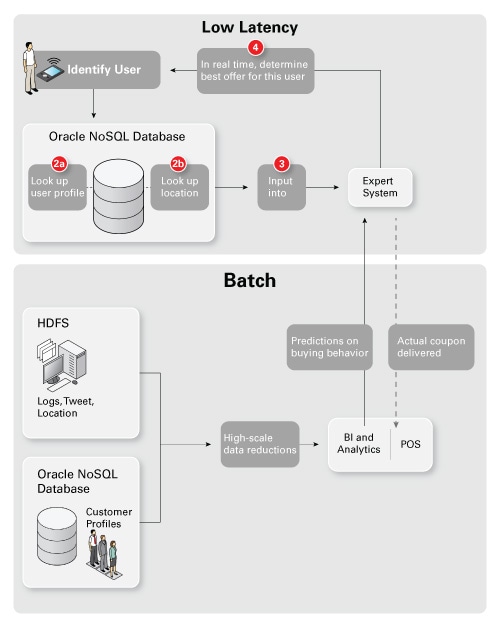
图 3. 创建购买行为模型
说一下数据源。一个重要元素是销售点 (POS) 数据(在关系数据库中),您需要将其与客户信息(来自网店、手机或会员卡)相关联。图 2 和图 3 中包含客户个人信息的 NoSQL 数据库显示网店元素。非常重要的是,要确保此多渠道数据与 Web 浏览、购买、搜索和社交媒体数据相集成(并且执行重复数据删除,但这是题外话)。
一旦完成数据关联和数据集成,就可以描绘出个人的行为。本质上,大数据使我们能够在个人一级进行极细微的细分 — 实际上是对数百万客户中的每一位!
这一切的最终目标是构建实时决策引擎中使用的高度精确的模型。此模型的目标与上述业务目标直接相关。换句话说,如何在客户来到商城时向客户发送优惠券,让客户前往您的店铺进行消费?
详细的数据流和产品思路
现在,如何通过实际产品实现这一目标,并且数据在此生态系统中如何流动?下面几节为您指出答案。
第 1 步:收集数据
要查找数据、收集数据以及根据数据作出决策,您需要实现一个分布式系统。因为设备基本上在不停地发送数据,您需要能够以较小的延迟加载数据(收集或获取数据)。这项工作在收集点完成,如图 4 所示。这里也是为实时决策而评估数据的位置。稍后我们再回到收集点。
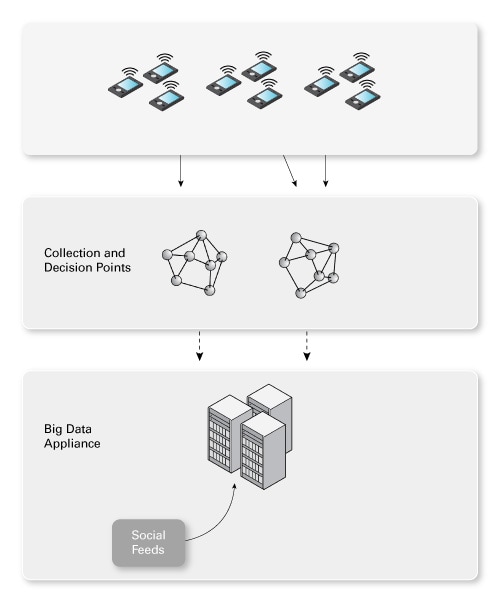
图 4. 收集点
来自收集点的数据流入 Hadoop 集群(在本例中,即大数据机)。您可能还会将其他数据提供给此设备。例如,图 4 所示的社交信源将来自分择相关哈希标记的数据聚合者(通常是一家公司)。然后使用 Flume 或 Scribe 将数据加载到 Hadoop。
第 2 步:整理和移动数据
下一步是添加数据(社交信源、用户个人信息和使结果与分析相关所需的任何其他数据)和开始整理、解释和理解数据。
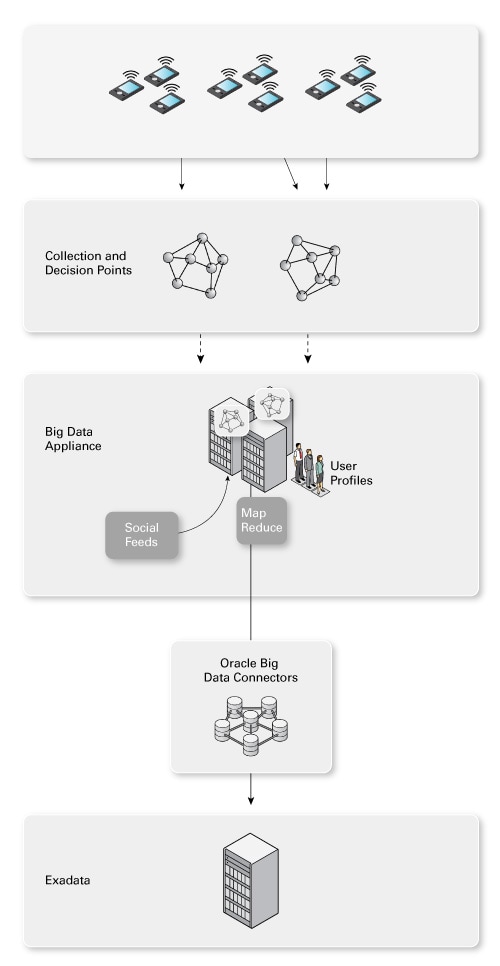
图 5. 整理和解释数据
例如,将用户个人信息添加到社交信源和添加位置数据以建立对各用户以及用户相关模式的全面了解。通常,这使用 Apache Hadoop MapReduce 来完成。用户个人信息通过 Hadoop InputFormat 接口从 Oracle NoSQL 数据库批量加载,因此被添加到 MapReduce 数据集。
为了将所有这些与 POS 数据、客户关系管理 (CRM) 数据以及各种其他交易数据结合,您可能会使用 Oracle Big Data Connectors 将精简的数据高效地移动到 Oracle 数据库。然后您可以使用 Oracle 商务智能云服务器 (Exalytics) 或业务智能 (BI) 工具或者(这是比较有趣的地方)通过数据挖掘之类的工具,对您所跟踪的数据有一个全面的了解。
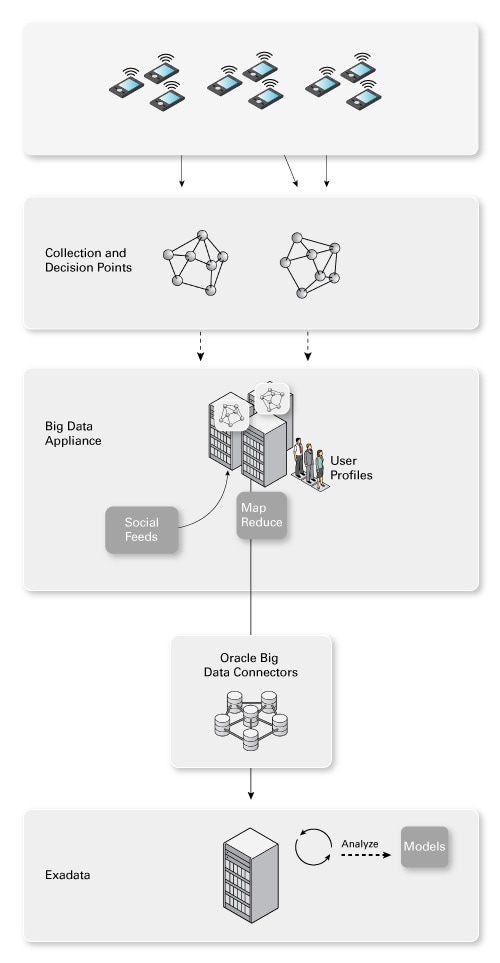
图 6. 移动精简数据
第 3 步:分析数据
最后一个阶段(这里称为“分析”)是创建数据挖掘模型和统计模型以便用于产生合适的优惠券。这些模型真正是皇冠上的明珠,因为它们让您能够基于非常精确的模型实时进行决策。模型进入收集点和决策点以作用于实时数据,如图 7 所示。
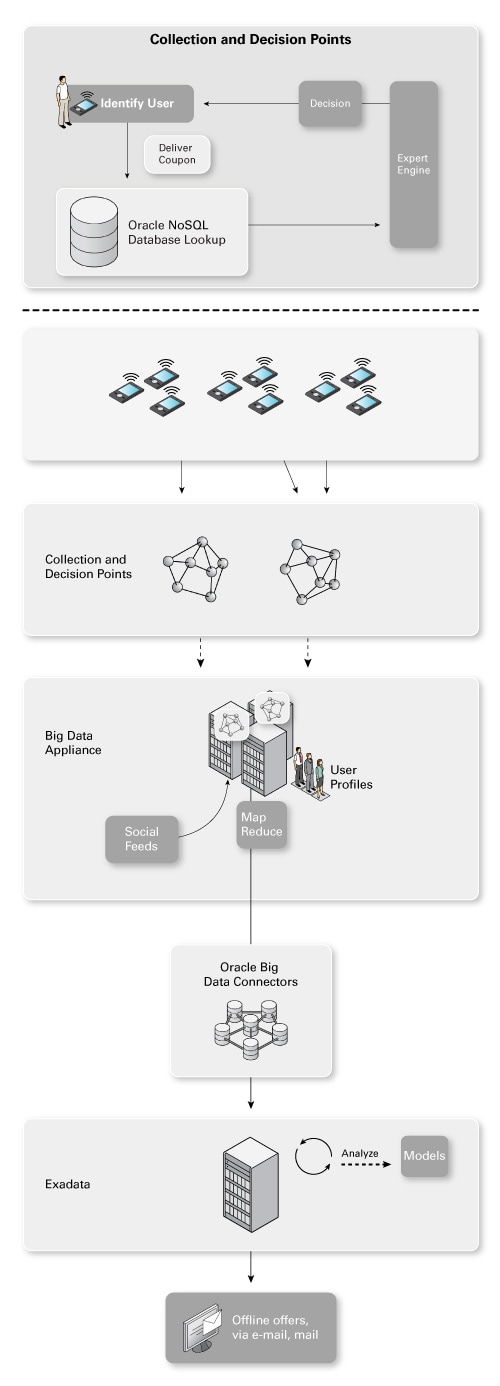
图 7. 分析数据
在图 7 中,您可以看到专家引擎中使用了一个灰色的模型。该模型描述和预测客户个人的行为并基于这些预测确定要采取的行动。
总结
以上所述是对“大数据”和实时决策的端到端观察。大数据让我们能够利用海量的数据和处理资源得出精确的模型。它还让我们能够确定以前无法预期的种种事情,从而产生更精确的模型以及新思想、新业务等等。
您可以使用基于 Oracle 技术的 Oracle 大数据机实现在此所展示的整个解决方案。然后就只需找几个了解编程模型的人即可创建这些皇冠上的明珠。