1.论文来源:
EMNLP 2018
2.论文贡献
使用 genetic algorithm 生成对抗样本
3.论文内容
3.1方法由来
图像可以通过改变某些像素产生人眼不易发现的差别从而生成对抗样本,自然语言不能通过这种方式,因为修改句子中的某个词语很可能整句意思都变了,图像的像素值是连续的,语言的每个词是离散的,即使对单词embeddings进行扰动,也不能保证句子的连贯性和原来的意思不改变。
3.2 之前贡献
-
Papernot, P. McDaniel, A. Swami, and R. Harang. 2016. Crafting adversarial input sequences for recurrent neural networks. arXiv preprint arXiv:1604.08275.
已经研究了导致误分类所必需的单词替换次数,但是没有考虑语义或句法,产生不连贯的例子
3.3 threat model
本文采用genetic algorithm来生成语言的adversarial examples. 作者假设威胁模型为用户可以无限的获取输入对应的模型输出,但是不知道模型架构、参数、训练数据等。
3.4 Algorithm

本质上就是一个遗传算法。首先是初代:Perturb对原始句子计算S次,产生S个结果就是初代。接着定义适应度:让模型f预测一下当前代每个个体,目标标签上的概率就是适应度。然后,如果预测label与目标label一致,停止算法,返回当前结果。如果不一致,继续一下步骤,对当前代,以适应度为正比的概率在父代中抽样。抽两个父代出来做交叉(论文里没有提到交叉如何做),交叉产生的后代作为新一代,输入给Perturb进行迭代。
对x_orig进行Perturb产生size=S的initial Population:
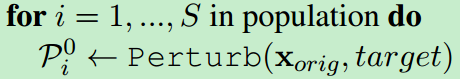
G是迭代次数,迭代次数内没有找到adversarial example 就算是攻击失败
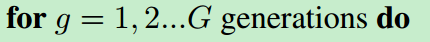
如果模型认为x_adv最大的概率标签为target t,则成功地找到了adversarial example.
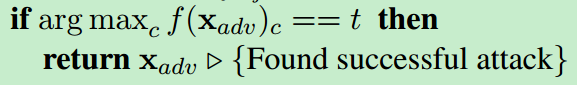
否则就从Generation中随机选择parent1, parent2 进行杂交Crossover, 变异(Mutation, 在这里就是Perturb),产生更好的下一代Generation去攻击。

4.实验结果
这是在IMDB上生成的adversarial example:

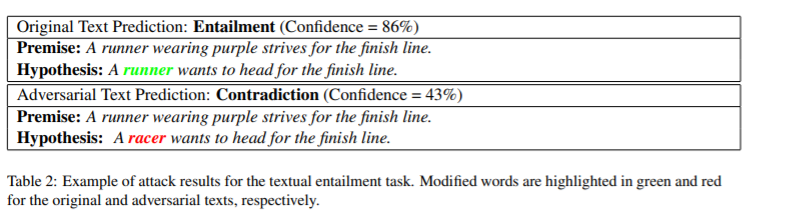
这是SNLI上生成的adversarial example:

5.结论
由表三可以看出,使用genetic attack 在修改原文14.7%的情况下,成功生成对抗样本的概率为97%,远高于perturb baseline
6.补充
扰动算法(Perturb):
在介绍算法之前,先来看下算法的一个子过程:扰动算法。该算法接受一个输入句子 [公式] ,从 [公式] 中随机选择一个单词 [公式] ,然后挑选一个与w语义相近且与上下文保持连贯的单词对w进行替换,并增加traget label的预测分数。为了挑选最合适的替换单词,采取以下步骤。
首先,在Glove的Embedding空间上,计算出N个与 [公式] 最相近的单词。距离采用欧式距离,并用阈值fai来过滤后选单词。另外,文章用了counter-fitting来对glove的embedding进行调整以确保最近邻的向量是语义相似的。另外,这里用到的embedding与待攻击模型的embedding是独立的。
PS. 介绍下counter-fitting算法。这个算法本质是让word embeding能够更好的表达语义信息。首先,随机选取一个单词w,然后,用另外一个词去替换W,要求1:确保语义空间相近的词去替换(GloVe),且替换的词是同义词(conter-fitting),2:语句通顺(语言模型),3:使预测概率上升。所谓conter-fitting就是做到:反义排斥,同义吸引,向量空间存留(保留优化后词向量集合与原始词向量集合之间的相似性)
其次,采用谷歌1 bilion量级的语言模型过滤掉不符合 [公式] 上下文的单词 [公式] 。我们根据语言模型的得分排序后选单词,并保留top k个后选单词。
对于句子 [公式] 的候选k个替换单词,我们从中挑选一个以使预测label的得分最高。
最终,我们找到了最合适的替换单词,扰动算法返回修改过后的句子作为结果。