1.DQN

在传统RL算法中,依靠的是Policy和Value的协同迭代优化agent。
而现代,
DQN等value-based类算法弱化了Policy的存在,Policy成了Value的附属;
ReinforcePG,DPG,DDPG等policy-based类算法弱化了Value的存在。agent依赖于PolicyNetwork,只做一个从State到Action的映射。
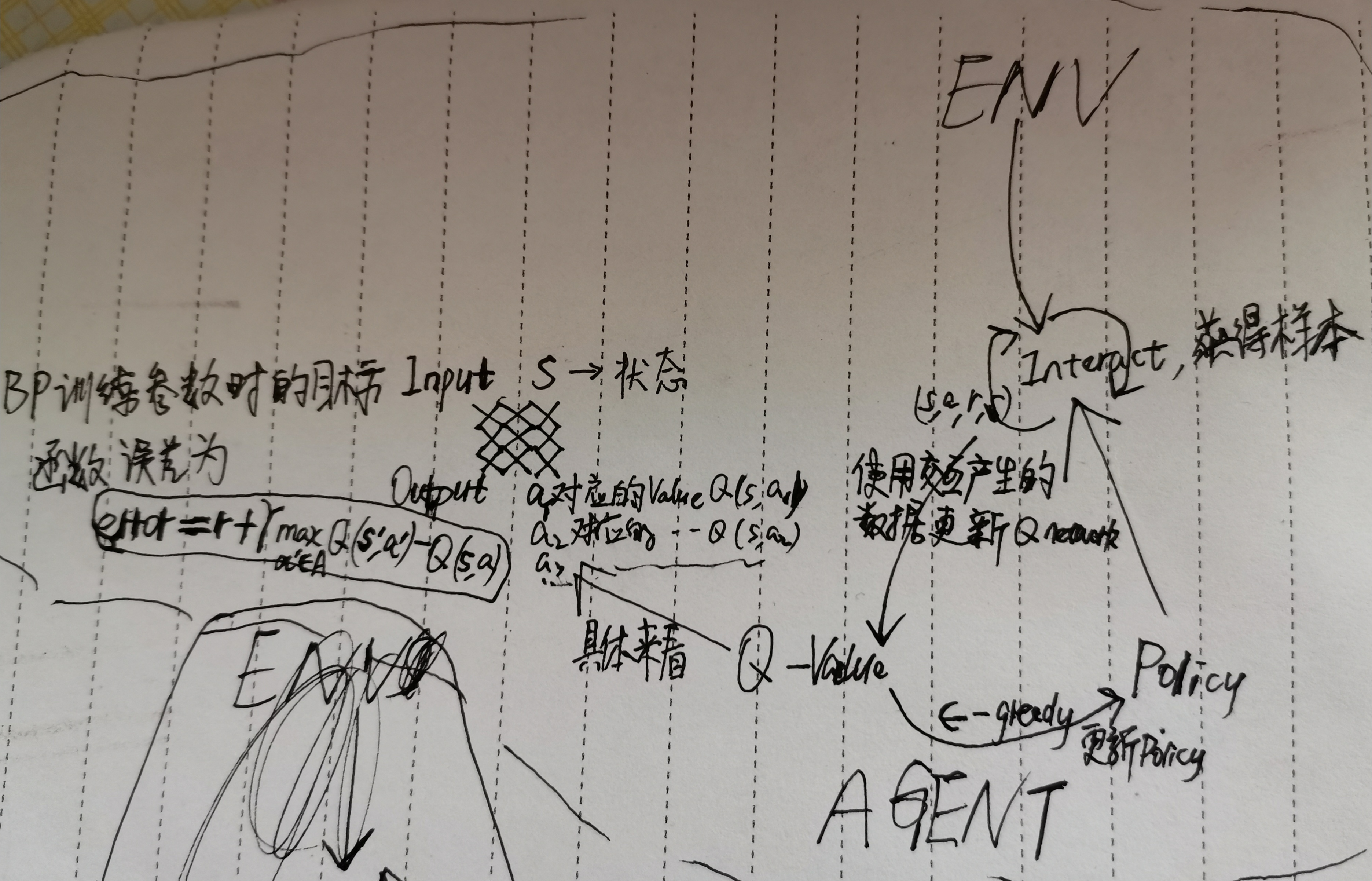
DQN在干嘛?从(s,a)到Q(s,a)的映射
训练DQN的时候在训练的什么?Q(s,a;serta)的参数serta
DQN如何训练?
首先agent与env交互,采样,训练样本为(s,a,r,s'),存储在experience_replay里。
然后采用反向传播方法优化神经网络的参数serta。
误差为

借助tensorflow实现DQN代码:
https://github.com/Dynmi/RL_study/blob/master/agent/agent_DQN.py
2. PG
这是OPENAI的人在DQN之后提出来的,它不聚焦于Value,而聚焦于Policy本身。建立一个从s到A的映射pai。此时跟DQN相同,还是面对的离散动作空间,用一个softmax来输出选择每个action的概率。监督学习的label使用state value。所以在PG这里还是需要Value的,MC_PG方法对待Value还是传统方法用一个表存state-value。算法优化过程在于优化神经网络pai的参数。

3. QAC
从PG往前一步,把Value也神经网络化,也就是说,算法训练的时候对两个神经网络进行参数优化,一个是Qvalue Network,一个是PolicyNetwork。
一直到这里应对的还是离散行为空间。

4. DDPG ( 2016ICLR )
Deterministic Policy Gradient
从DPG开始就研究连续行为空间了。