马尔可夫决策过程MDP,是强化学习的基础。
MDP --- <S,A,P,R,γ>
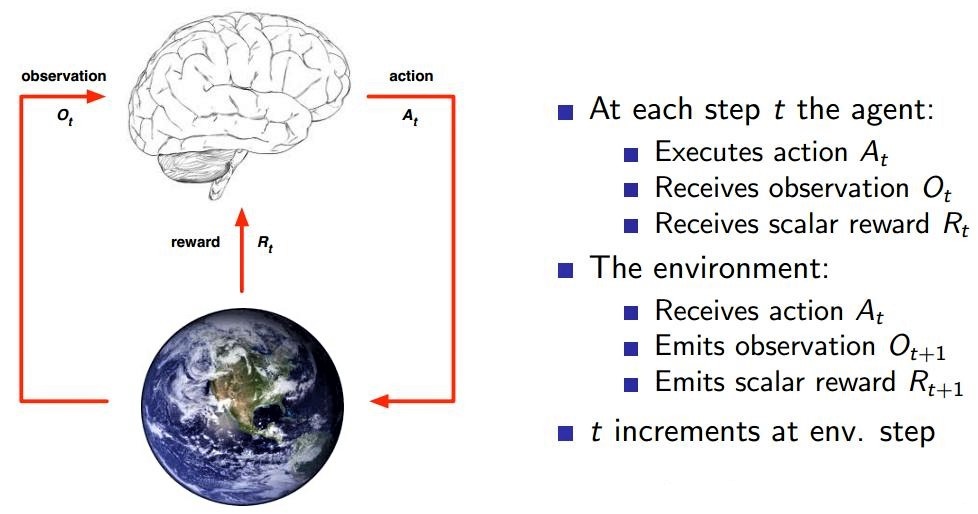
AGENT
STATE
ENV
REWARD ,由ENV给出。agent处于状态s下,采取action之后离开状态获得一个reward。即f:S x A --->R
所有强化学习问题解决的目标都可以描述成最大化累积奖励。All goals can be described by the maximisation of expected cumulative reward。即我们的目标是最大化Gt 。

ACTION ,离散分布,或者连续分布。
POLICY ,策略。 π :S x A --->[0,1]
|——Deterministic policy: a = π(s)
|——Stochastic policy: π(a|s) = P[At = a|St = s] //一个典型的随机策略 e-greedy policy derived from Q
VALUE ,a prediction of future reward; 形象地说AGENT.VALUE是agent对env的感觉,这样好,那样不好,对这个感到舒服,对那个感到upside
|——state value V(s),表示State好坏的量。V(s)的值代表了State s的好坏。好坏是对于未来reward累积而言的。
| ![]()
|——state-action value Q(s,a),
| 
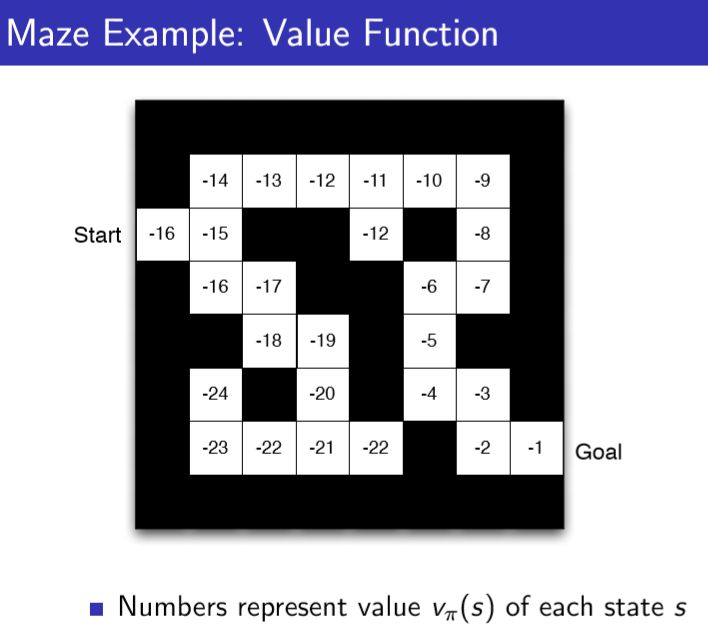
下面是一个”迷宫游戏“的例子:


以及算法中基本上用不到的概念Model,我们也给画出来:

History & Observation & State三个概念辩解:
![]()
如下图中,红框为History,黑圈为Observation。
至于State,要看f()是如何定义的,St = f(Ht),f()是我们人为定义的。
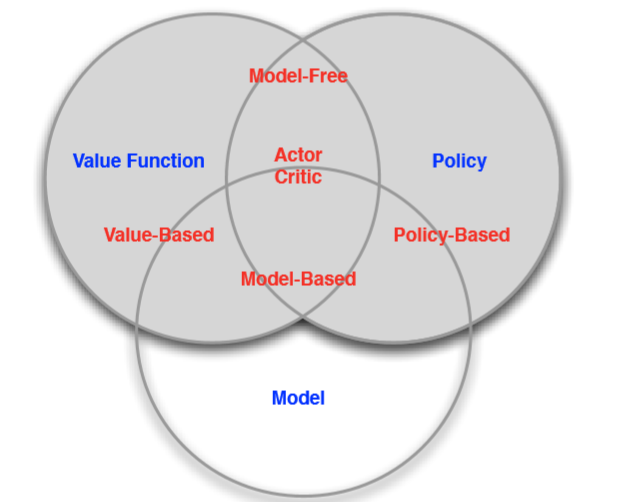
AGENT分为以下三类:

Model free和Model based辩解:
我们进一步把RL算法分为Model free和Model based两类。
Model based算法需要全知env,或者说已知Reward(s,a) for any (s,a)
Model free算法不需要全知env。