参考:
https://mp.weixin.qq.com/s/NvwB9H71JUivFyL_Or_ENA
http://yangminz.coding.me/blog/post/MinkolovRNNLM/MinkolovRNNLM_thesis.html
语言模型本质上是在回答一个问题:出现的语句是否合理。
在历史的发展中,语言模型经历了专家语法规则模型(至80年代),统计语言模型(至00年),神经网络语言模型(到目前)。
专家语法规则模型
在计算机初始阶段,随着计算机编程语言的发展,归纳出的针对自然语言的语法规则。但是自然语言本身的多样性、口语化,在时间、空间上的演化,及人本身强大的纠错能力,导致语法规则急剧膨胀,不可持续。
统计语言模型
统计语言模型就是计算一个句子的概率大小的这种模型。形式化讲,统计语言模型的作用是为一个长度为 m 的字符串确定一个概率分布 P(w1; w2; :::; wm),表示其存在的可能性,其中 w1 到 wm 依次表示这段文本中的各个词。
计算机借助于统计语言模型的概率参数,可以估计出自然语言中每个句子出现的可能性,而不是简单的判断该句子是否符合文法。常用统计语言模型,包括了N元文法模型(N-gram Model)统计语言模型把语言(词的序列)看作一个随机事件,并赋予相应的概率来描述其属于某种语言集合的可能性。给定一个词汇集合 V,对于一个由 V 中的词构成的序列 S = ⟨w1, · · · , wT ⟩ ∈ Vn,统计语言模型赋予这个序列一个概率 P(S),来衡量 S 符合自然语言的语法和语义规则的置信度。

统计语言模型用简单的方式,加上大量的语料,产生了比较好的效果。统计语言模型通过对句子的概率分布进行建模,统计来说,概率高的语句比概率低的语句更为合理。在实现中,通过给定的上文来预测句子的下一个词, 如果预测的词和下一个词是一致(该词在上文的前提下出现的概率比其它词概率要高),那么上文+该词出现的概率就会比上文+其他词词的概率要更大,上文+该词更为合理。
较为常用的,当n=1时,我们称之为unigram(一元语言模型);当n=2时,我们称之为bigram(二元语言模型);当n=3时,我们称之为trigram(三元语言模型)。
下面具体讲解下统计语言模型N-gram
具体N-gram的理解参考:
https://www.cnblogs.com/ljy2013/p/6425277.html
https://blog.csdn.net/songbinxu/article/details/80209197
N-gram模型是一种典型的统计语言模型(Language Model,LM),统计语言模型是一个基于概率的判别模型.统计语言模型把语言(词的序列)看作一个随机事件,并赋予相应的概率来描述其属于某种语言集合的可能性。给定一个词汇集合 V,对于一个由 V 中的词构成的序列S = ⟨w1, · · · , wT ⟩ ∈ Vn,统计语言模型赋予这个序列一个概率P(S),来衡量S 符合自然语言的语法和语义规则的置信度。用一句简单的话说,统计语言模型就是计算一个句子的概率大小的这种模型。

上面参数空间过大参考朴素贝叶斯。
为了解决第一个问题N-gram模型基于这样一种假设,当前词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram(N=2)和三元的Tri-Gram(N=3).Bi-Gram所满足的假设是马尔科夫假设。
一般常用的N-Gram模型是Bi-Gram和Tri-Gram。分别用公式表示如下:
Bi-Gram: P(T)=p(w1|begin)*p(w2|w1)*p(w3|w2)***p(wn|wn-1)
Tri-Gram: P(T)=p(w1|begin1,begin2)*p(w2|w1,begin1)*p(w3|w2w1)***p(wn|wn-1,wn-2)
注意上面概率的计算方法:P(w1|begin)=以w1为开头的所有句子/句子总数;p(w2|w1)=w1,w2同时出现的次数/w1出现的次数。以此类推。
对于其中每项的计算举个例子:

由上可见Bi-Gram计算公式中的begin一般都是加个<s>标签。
N-gram存在的问题:
举一个小数量的例子进行辅助说明:假设我们有一个语料库(注意语料库),如下:
老鼠真讨厌,老鼠真丑,你爱老婆,我讨厌老鼠。
想要预测“我爱老”这一句话的下一个字。我们分别通过 bigram 和 trigram 进行预测。
1)通过 bigram,便是要对 P(w|老)进行计算,经统计,“老鼠”出现了3次,“老婆”出现了1次,通过最大似然估计可以求得P(鼠|老)=0.75,P(婆|老)=0.25, 因此我们通过 bigram 预测出的整句话为: 我爱老鼠。
2)通过 trigram,便是要对便是要对 P(w|爱老)进行计算,经统计,仅“爱老婆”出现了1次,通过最大似然估计可以求得 P(婆|爱 老)=1,因此我们通过trigram 预测出的整句话为: 我爱老婆。显然这种方式预测出的结果更加合理。
问题一:随着 n 的提升,我们拥有了更多的前置信息量,可以更加准确地预测下一个词。但这也带来了一个问题,当N过大时很容易出现这样的状况:某些n-gram从未出现过,导致很多预测概率结果为0,这就是稀疏问题。实际使用中往往仅使用 bigram 或 trigram。(这个问题可以通过平滑来缓解参考:https://mp.weixin.qq.com/s/NvwB9H71JUivFyL_Or_ENA)
问题二:同时由于上个稀疏问题还导致N-gram无法获得上下文的长时依赖。
问题三:n-gram 基于频次进行统计,没有足够的泛化能力。

总结:统计语言模型就是计算一个句子的概率值大小,整句的概率就是各个词出现概率的乘积,概率值越大表明该句子越合理。N-gram是典型的统计语言模型,它做出了一种假设,当前词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。它其中存在很多问题,再求每一个词出现的概率时,随着N的提升,能够拥有更多的前置信息量,可以使得当前词的预测更加准确,但是当N过大时会出现稀疏问题,导致很多词的概率值为0,为解决这一问题,因此常用的为bigram 或 trigram,这就导致N-gram无法获得上文的长时依赖。另一方面N-gram 只是基于频次进行统计,没有足够的泛化能力。
神经网络语言模型
2003年 Bengio 提出,神经网络语言模型( neural network language model, NNLM)的思想是提出词向量的概念,代替 ngram 使用离散变量(高维),采用连续变量(具有一定维度的实数向量)来进行单词的分布式表示,解决了维度爆炸的问题,同时通过词向量可获取词之间的相似性。
结合下图可知它所建立的语言模型的任务是根据窗口大小内的上文来预测下一个词,因此从另一个角度看它就是一个使用神经网络编码的n-gram模型。
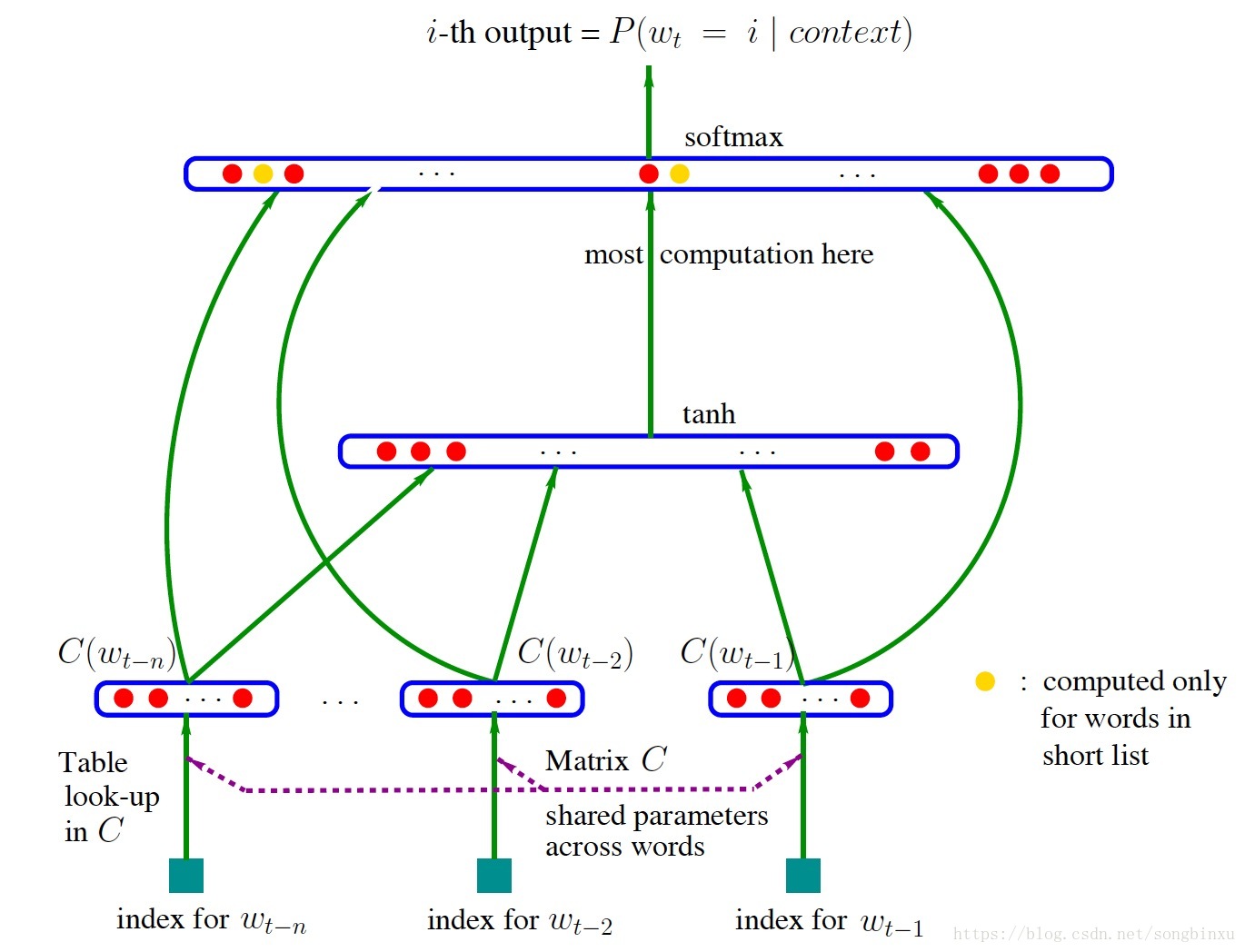
它是一个最简单的神经网络,仅由四层构成,输入层、嵌入层、隐藏层、输出层。(从另一个角度看它就是一个使用神经网络编码的n-gram模型)
输入是单词序列的index序列,例如单词‘这’在字典(大小为∣V∣)中的index是10,单词‘是’的 index 是23,‘测’的 index 是65,则句子“这是测试”通过‘这是测’预测‘试’,窗口大小内上文词的index序列就是 10, 23, 65。嵌入层(Embedding)是一个大小为∣V∣×K的矩阵(注意:K的大小是自己设定的,这个矩阵相当于随机初始化的词向量,会在bp中进行更新,神经网络训练完成之后这一部分就是词向量),从中取出第10、23、65行向量拼成3×K的矩阵就是Embedding层的输出了。隐层接受拼接后的Embedding层输出作为输入,以tanh为激活函数,最后送入带softmax的输出层,输出概率,优化的目标是使得待预测词其所对应的softmax值最大。
缺点:因为这是通过前馈神经网络来训练语言模型,缺点显而易见就是其中的参数过多计算量较大,同时softmax那部分计算量也过大。另一方面NNLM直观上看就是使用神经网络编码的 n-gram 模型,也无法解决长期依赖的问题。
RNNLM
它是通过RNN及其变种网络来训练语言模型,任务是通过上文来预测下一个词,它相比于NNLM的优势在于所使用的为RNN,RNN在处理序列数据方面具有天然优势,RNN 网络打破了上下文窗口的限制,使用隐藏层的状态概括历史全部语境信息,对比 NNLM 可以捕获更长的依赖,在实验中取得了更好的效果。RNNLM 超参数少,通用性更强;但由于 RNN 存在梯度弥散问题,使得其很难捕获更长距离的依赖信息。
Word2vec中的CBOW 以及skip-gram,其中CBOW是通过窗口大小内的上下文预测中心词,而skip-gram恰恰相反,是通过输入的中心词预测窗口大小内的上下文。
Glove 是属于统计语言模型,通过统计学知识来训练词向量
ELMO 通过使用多层双向的LSTM(一般都是使用两层)来训练语言模型,任务是利用上下文来预测当前词,上文信息通过正向的LSTM获得,下文信息通过反向的LSTM获得,这种双向是一种弱双向性,因此获得的不是真正的上下文信息。
GPT是通过Transformer来训练语言模型,它所训练的语言模型是单向的,通过上文来预测下一个单词
BERT通过Transformer来训练MLM这种真正意义上的双向的语言模型,它所训练的语言模型是根据上下文来预测当前词。
以上部分的详细介绍在NLP之预训练篇中有讲到
语言模型的评判指标
具体参考:https://blog.csdn.net/index20001/article/details/78884646
Perplexity可以认为是average branch factor(平均分支系数),即预测下一个词时可以有多少种选择。别人在作报告时说模型的PPL下降到90,可以直观地理解为,在模型生成一句话时下一个词有90个合理选择,可选词数越少,我们大致认为模型越准确。这样也能解释,为什么PPL越小,模型越好。
一般用困惑度Perplexity(PPL)衡量语言模型的好坏,困惑度越小则模型生成一句话时下一个词的可选择性越少,句子越确定则语言模型越好。