偶然发现这么一个网站:
http://www.pythonchallenge.com/
感觉很有意思,记录一下闯关过程
第0关
提示是 try to change the URL address.所以算出2^38直接访问www.pythonchallenge.com/pc/def/274877906944.html即可
第1关

给了一个图和一段话:
g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj.
很明显是类似于凯撒密码嘛,写个脚本:
s=" g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj. " f='' for i in s: if i.isalpha(): f+=chr(((ord(i)+2)-ord('a'))%26+ord('a')) else: f+=i print(f)
输出:
第2关
给了一个提示:
recognize the characters. maybe they are in the book,
but MAYBE they
are in the page source.
这个MAYBE已经很明显了,答案就是在源码里,f12一下:
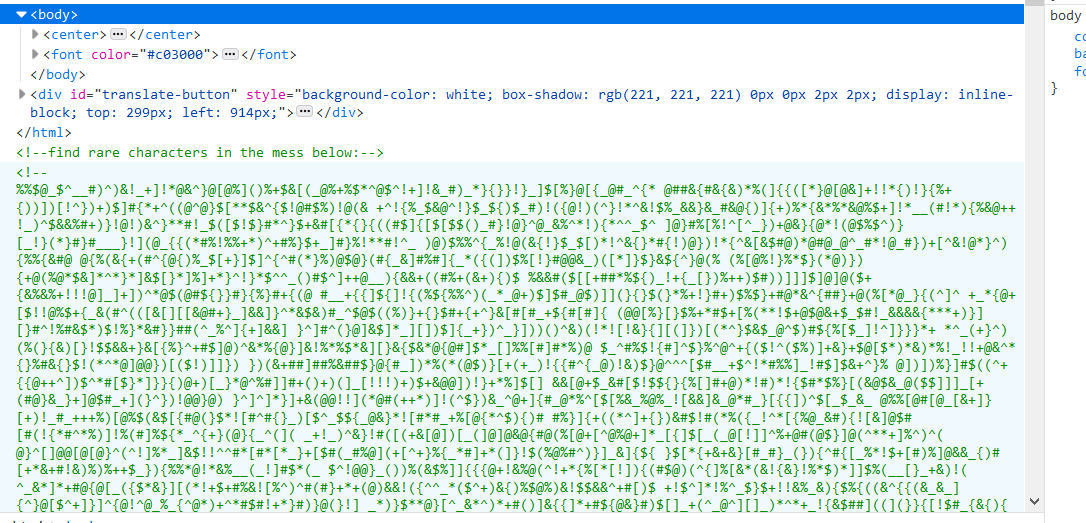
一开始还以为是什么加密方法,但是仔细看hint才明白要求:recognize the characters.需要把藏在里面的字母找出来!
所以也很简单了,可以直接复制来一下写脚本,也可以用request get一下:
import requests import re url='http://www.pythonchallenge.com/pc/def/ocr.html' r=requests.get(url) zz="find.+?<!--(.+?)-->" text=re.findall(zz,r.text,re.DOTALL) f='' #print(text) for i in text[0]: if i.isalpha(): f+=i print(f)
得到
第3关
提示是:
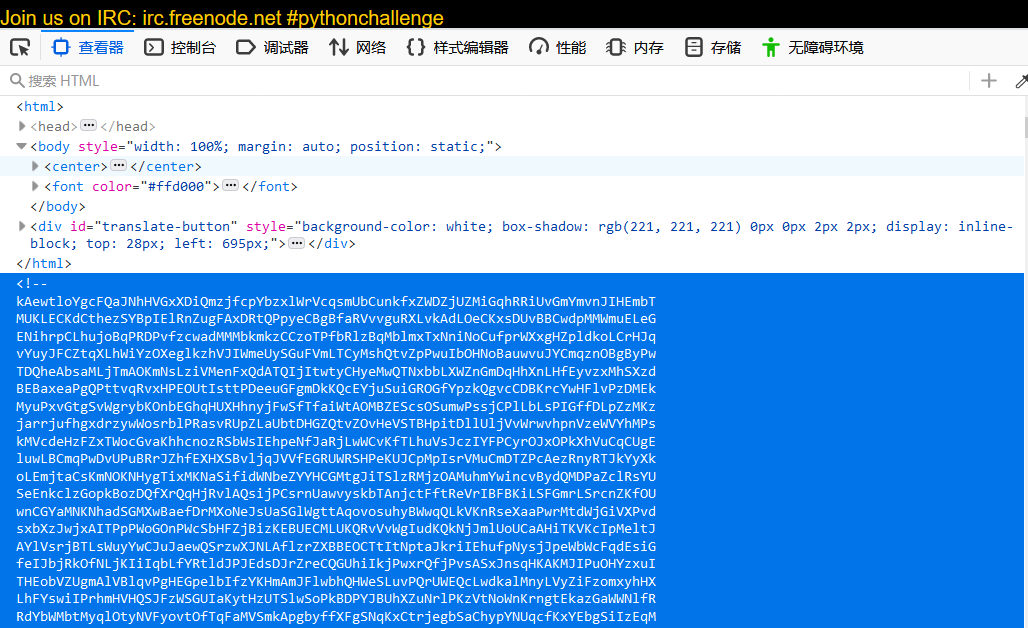
所以和上一关差不多,直接get一下,用正则就好了,需要注意的是,正则的写法:
[a-z]+[A-Z]{3}([a-z])[A-Z]{3}[a-z]+
需要在左右再包上小写字母,这样才能保证是正好被三个大写字母包围
import requests import re url='http://www.pythonchallenge.com/pc/def/equality.html' r=requests.get(url) zz="<!--(.+?)-->" text=re.findall(zz,r.text,re.DOTALL) zz=r'[a-z]+[A-Z]{3}([a-z])[A-Z]{3}[a-z]+' f=re.findall(zz,text[0]) s='' for i in f: s+=i print(s)
输出:

给了个提示,看来是要把url改成http://www.pythonchallenge.com/pc/def/linkedlist.php
第4关

说下一个nothing是44827,这里观察url:
http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=12345
发现nothing是一个参数,改成44827之后发现还是一样的结构,所以写个爬虫,也不知道要循环多少次,先看看能运行到哪吧:
import requests import re baseurl="http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=" url='http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=12345' while 1: r=requests.get(url) print(r.text) zz='nothing is (.+)' #贪婪模式 匹配最长 number=re.findall(zz,r.text) url=baseurl+number[0] print(number[0])
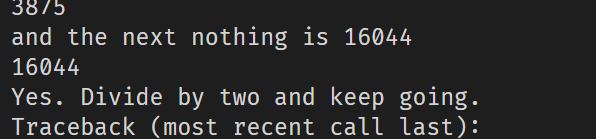
可以看到16044这里出现了问题,去看一下:

好吧,需要除以2再继续,那就需要加上一个判断:
import requests import re baseurl="http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=" url='http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=16044' while 1: r=requests.get(url) print(r.text) zz='nothing is (.+)' #贪婪模式 匹配最长 number=re.findall(zz,r.text) if(len(number)==0): number=url.split('=')[1] number=str(int(number)/2) url=baseurl+number print(number) else: url=baseurl+number[0] print(number[0])
继续运行,不久可以看到出现了一个不一样的,说是有干扰项:

不过根据我写的正则,并不会进入这个干扰项hhh~没有影响
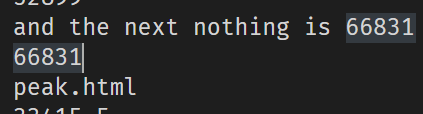
最后就是这个了,下一关的url:
http://www.pythonchallenge.com/pc/def/peak.html