最近在项目中的soket通信时,遇到了大小字节序问题和网络传输时的字节序问题,现在给大家整理一下,希望大家对字节序有个比较深入的了解,其实理解了就很简单的。
开始遇到的问题:
1、本地的数据通过网络传输然后在目的地解析网络上的数据,字节序是如何统一的
2、字节序不同,数据(如0xFF00)存入内存地址中位置不同(大字节序:FF--低地址位 00--高地址位 ;小字节序: 00--低地址位 FF--高地址位),为什么读出的值都是0xFF00
下面让我们带着问题来理解:
大字节序:大端有效 ,高位数据先放入低地址内存 , 低位数据再放入高地址内存
小字节序:小端有效,低位数据先放入低地址内存 , 高位数据再放入高地址内存
注意:描述的是将数据(肉眼看到的)放入内存中的地址(计算机的硬盘内存中)
然后看一下图示吧:
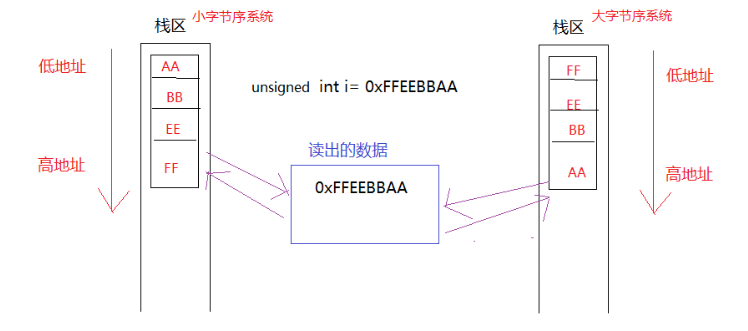
相信大家对遇到的第二个问题已经知道答案了吧,现在再来看看第一个问题。
网络字节序:是大字节序,在把数据进行网络传输时,要保证自己传输到网络上的数据时大字节序。
再来看看图示吧:
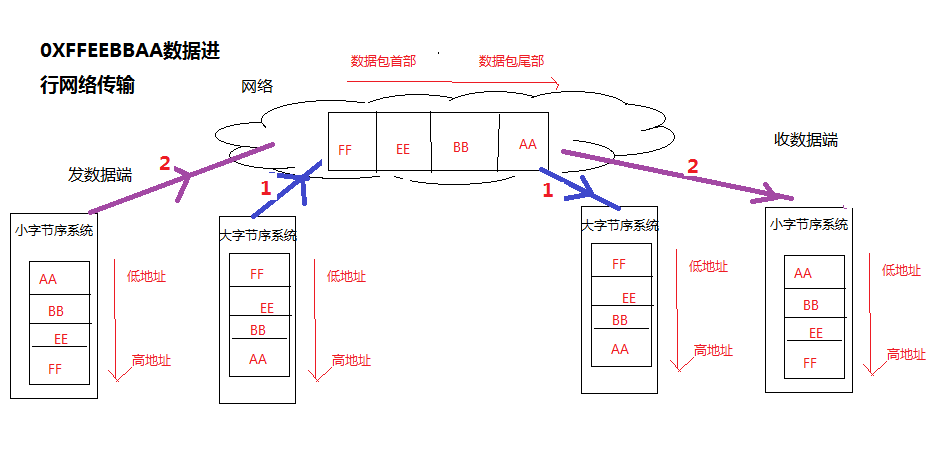
1号线路:发数据和接收数据都不需要转序,因为自己是和网络都是大字节序
2号线路:发数据和接收数据都需要转序,因为自己是小字节序,网络都是大字节序,才能保证自己本系统的数据永远都是小字节序。可能高级语言(java、C#屏蔽了字节序,大家感受不到,那是因为高级语言内存进行封装和处理了)
好了,现在大家对第一个问题也清楚了吧。
最后让我们来看看鉴定大小字节序的C语言程序吧
#include <stdlib.h> #include <string.h> int main() { /*将结合体的整型值赋值为1,如果是小字节序,小端有效,低地址写入的就是1,读出字符ch就是1 如果是大字节序,大端有效,低地址写入的就是0,读出字符ch就是0*/ data.i = 1; if(data.ch) { printf("this system is small-endian "); } else { printf("this system is big-endian "); } return 0; }
原因:将结合体的整型值赋值为1,如果是小字节序,小端有效,低地址写入的就是1,读出字符ch就是1
如果是大字节序,大端有效,低地址写入的就是0,读出字符ch就是0
检验大小字节序的方法很多,本人认为这个方法比较简单,容易理解。
最后希望能对大家有帮助,有什么问题请留言,谢谢。