网上已有人实现sqlserver的split函数可将字符串分割成行,但是我们习惯了split返回数组或者列表,因此这里对其做一些改动,最终实现也许不尽如意,但是也能解决一些问题。
先贴上某大牛写的split函数(来自:Split function in SQL Server to break Comma separated strings,注意我这里将其命名为splitl):
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
ALTER FUNCTION dbo.splitl ( @String VARCHAR(MAX), @Delimiter VARCHAR(MAX)) RETURNS @temptable TABLE (items VARCHAR(MAX)) ASBEGIN DECLARE @idx INT=1 DECLARE @slice VARCHAR(MAX) IF LEN(@String) < 1 OR LEN(ISNULL(@String,'')) = 0 RETURN WHILE @idx != 0 BEGIN SET @idx = CHARINDEX(@Delimiter,@String) IF @idx != 0 SET @slice = LEFT(@String,@idx - 1) ELSE SET @slice = @String IF LEN(@slice) > 0 INSERT INTO @temptable(items) VALUES(@slice) SET @String = RIGHT (@String, LEN(@String) - @idx) IF LEN(@String) = 0 BREAK END RETURNEND |
其原理还是比较简单的,一看便知。调用该函数返回的结果是:
|
1
|
SELECT * FROM dbo.splitl('a#b#c#d','#') |

然而我希望得到的结果是:
|
1
|
SELECT 'a' a,'b' b,'c' c,'d' d |
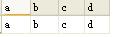
这就要用到sqlserver行转列的技巧,网上有很多方法可以参照。下面真正的split“过程”来了:
|
1
2
3
4
5
6
7
|
ALTER PROC [dbo].[split] @strs VARCHAR(MAX),@delimiter VARCHAR(MAX) ASSELECT items,id=IDENTITY(INT,1,1) INTO #ccc FROM dbo.splitl(@strs,@delimiter)DECLARE @str VARCHAR(MAX)='',@SQL VARCHAR(MAX)='' SELECT @str = @str + ',' + '[' + CONVERT(VARCHAR(MAX),id) + ']' FROM #cccSET @SQL = 'SELECT * FROM #ccc PIVOT(MAX(items) FOR id IN(' + SUBSTRING(@str,2,LEN(@str)) + ')) b'EXEC (@SQL)DROP TABLE #ccc |
该过程中使用了pivot语法,参见:使用 PIVOT 和 UNPIVOT
注意这个过程调用了splitl函数,是在其基础上开发的。我们再来看看执行结果:
|
1
|
EXEC dbo.split 'a#b#c#d','#' |
发现与上面期望的效果完全一致了!
但是这只是针对一行数据做split,如果是查询结果有多行都要分割怎么办呢?
我没有找到办法,因为sqlserver查询语句中不能嵌套过程,只能调用函数,而函数返回的结果集不能是多行。
but..世上无难事,只要写过程:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
-- 删除结果表IF EXISTS (SELECT * FROM dbo.sysobjects WHERE id=object_id(N'test_result') AND OBJECTPROPERTY(id, N'IsUserTable')=1) DROP TABLE test_result-- 建立数据表CREATE TABLE #tmp ( id INT NOT NULL IDENTITY(0,1), str VARCHAR(MAX))INSERT INTO #tmp SELECT 'a#b#c#d' UNION SELECT 'f#g#h'-- 生成结果表DECLARE @maxc INT=(SELECT MAX(LEN(str)-LEN(REPLACE(str,'#','')))+1 FROM #tmp)DECLARE @sql0 VARCHAR(MAX)='CREATE TABLE test_result ('DECLARE @x INT=0WHILE @x<@maxc BEGIN SET @sql0 = @sql0 + 'a' + CONVERT(VARCHAR(MAX),@x) + ' VARCHAR(MAX),' SET @x=@x+1ENDSET @sql0 = SUBSTRING(@sql0,0,LEN(@sql0)) + ')'EXEC (@sql0)-- 遍历数据表DECLARE @i INT=0WHILE @i<(SELECT COUNT(1) FROM #tmp) BEGIN DECLARE @strs VARCHAR(MAX)=(SELECT str FROM #tmp WHERE id=@i) DECLARE @cols INT=(SELECT LEN(@strs)-LEN(REPLACE(@strs,'#','')))+1 DECLARE @y INT=0 DECLARE @sql1 VARCHAR(MAX)='INSERT INTO test_result(' WHILE @y<@cols BEGIN SET @sql1 = @sql1 + 'a' + CONVERT(VARCHAR(MAX),@y) + ',' SET @y=@y+1 END-- -- 分割字符串 SET @sql1 = SUBSTRING(@sql1,0,LEN(@sql1)) + ') EXEC split "' + @strs + '","#"' EXEC (@sql1) SET @i=@i+1ENDSELECT * FROM test_result |
暂时就到此为止八~sqlserver毕竟不够完美,这样的函数系统提供能够最好,自己实现的话遇到太多瓶颈,比如函数不支持动态语句,不能将查询结果传入过程等等。
至于实际应用,将上面这个栗子建立临时数据表的部分替换成要查询的真实表列即可,最后结果如下所示:
