springCloud Sleuth分布式请求链路跟踪
Zipkin 是一个开放源代码分布式的跟踪系统,每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图。
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。为了方便在开发环境我直接采用了In-Memory方式进行存储,生产数据量大的情况则推荐使用Elasticsearch。
默认启动方式会将日志数据存在内存中,一旦服务重启会清空数据
1:zipKin监控平台下载:
SpringCloud从F版起已经不需要自己构建ZipKin Server了,只需要调用jar包即可。
Zipkin下载地址:https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/
运行jar :
浏览器访问:localhost:9411
一条链路通过Trace Id唯一标识,Span标识发起的请求信息,各个span通过parent ID关联起来。
maven依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
参数配置:
spring:
zipkin:
base-url: http://127.0.0.1:9411
sleuth:
sampler:
percentage: 1.0
这里的
base-url是zipkin服务端的地址,percentage是采样比例,设置为1.0时代表全部强求都需要采样。Sleuth默认采样算法的实现是Reservoir sampling,具体的实现类是PercentageBasedSampler,默认的采样比例为: 0.1(即10%)。默认启动方式会将日志数据存在内存中,一旦服务重启会清空数据,如果使用mysql存储,配置如下:
新建:名为zipkin的数据库
然后参照官方的建表语句建表:https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
这里贴一张zipkin github上的一张配置截图
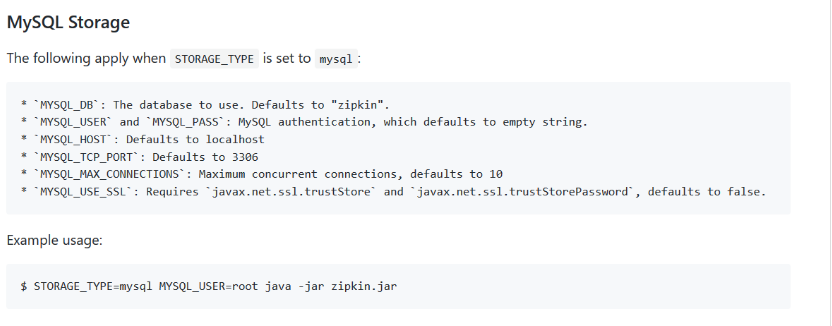
如上图,执行
STORAGE_TYPE=mysql MYSQL_USER=root MYSQL_PASS=root MYSQL_HOST=100.73.12.53 MYSQL_TCP_PORT=3306 nohup java -jar zipkin-server-2.3.1-exec.jar &