目录
查看文件内容cat,rev,more,less
文件截取head,tail
按列截取cut
文本排序sort
去除重复uniq
文件合并paste
文本数据统计wc
diff与patch
查看文件内容cat,rev,more,less
我们介绍几个实用的文本查看工具,有针对于大文件的,也有针对于小文件的,我们在查看文件的同时,还可以对文件进行一些设置,比如设置行号,设置压缩空行等,接下来我们来看看这几个工具是如何使用的吧。
短文件查看工具
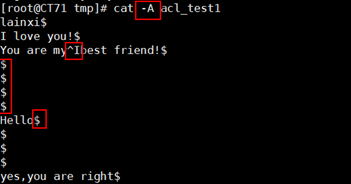
1 命令:cat(tac) 2 格式:cat [option] filename 3 参数: 4 -n:显示行号 5 -b:显示非空行的行号 6 -E:显示结束符$ 7 -A:显示所有控制字符 8 -s:压缩连续的空行为一行
cat命令是主要针对于短文件查看的,从上至下的查看,但是tac正好相反,是从文件的下方到上方的查看。cat也可以查看长文件,但是,我们只能看到长文件的最后铺满屏幕的几行,没有办法向上翻页。
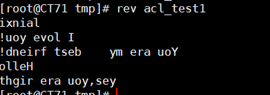
镜像翻转rev
1 命令:rev 2 格式:rev [option] filename 3 选项: 4 无
长文件阅读more
1 命令:more 2 格式:more [option] filename 3 参数: 4 空格键 (space):代表向下翻一页; 5 Enter :代表向下翻『一行』; 6 /字符串 :代表在这个显示的内容当中,向下搜寻『字符串』这个关键词; 7 :f :立刻显示出文件名以及目前显示的行数; 8 q :代表立刻离开 more ,不再显示该文件内容。 9 b 或 [ctrl]-b :代表往回翻页,不过这动作只对文件有用,对管线无用。
more命令虽然可以查看长文件,但是在翻页和查找的时候友好度并没有less好,所以我们一般都可以使用less对长文件的查看。
长文件阅读less
1 命令:less 2 格式:less [option] filename 3 选项: 4 空格键 :向下翻动一页; 5 [pagedown]:向下翻动一页; 6 [pageup] :向上翻动一页; 7 /字符串 :向下搜寻『字符串』的功能; 8 ?字符串 :向上搜寻『字符串』的功能; 9 n :重复前一个搜寻 (与 / 或 ? 有关! ) 10 N :反向的重复前一个搜寻 (与 / 或 ? 有关! ) 11 g :前进到这个资料的第一行去; 12 G :前进到这个数据的最后一行去 (注意大小写); 13 q :离开 less 这个程序;
我们从选项上就可以看出来,less这个工具来查看长文本的时候是很方便的,我们可以结合cat工具,显示行号,显示一些字符等,可以对文件查看,使用很方便,我们做一个演示:
文件截取head,tail
我们在查看文件的时候,有时只需要文件的前几行后者后几行,这时候用上边的文本查看工具都不太好用,这时候咋办呢,我们这里有两个工具,专门用来查看文本的首尾行的。
查看前几行head
1 命令:head 2 格式:head [option] filename 3 选项: 4 -c num:查看前num个字符 5 -n num:查看前num行
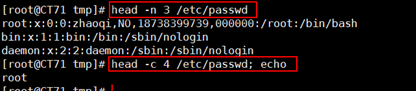
查看后几行tail
1 命令:tail 2 格式:tail [option] filename 3 选项: 4 -c num: 指定获取后num字节 5 -n num: 指定获取后num行 6 -f: 跟踪显示文件新追加的内容,常用日志监控
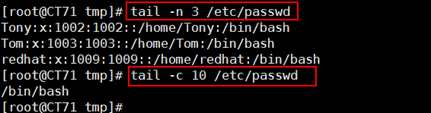
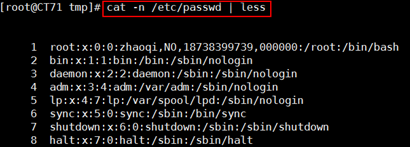
tail 的-f 选项用来实时查看日志动态是十分有用的选项,可以自己动手试一下。出了head和tail的单独使用外,还可以放在一起使用,比如:我想截取一个文本的11-15行并且按照行号输出,该咋办,我们可以使用cat -n /etc/passwd | head -n 15 | tail -n 5,这种操作用起来还是很爽的。
按列截取cut
有些时候我们不需要文本的全部内容,只是需要其中的一部分对我们来说最重要的东西,比如我们查看一个分区的使用量,我们只需要得到它的使用大小就可以了,比如我们想获取分区磁盘的最大使用量是多少:
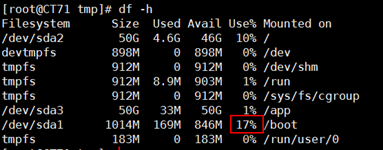
我们想到得到的只是一个数字而已,这该如何操作呢?我们先介绍一个我们我们需要用到的命令cut:
1 格式:cut [option] filename 2 选项: 3 -d DELIMITER: 指明分隔符,默认tab 4 -c 按字符切割 5 --output-delimiter=STRING指定输出分隔符 6 -f FILEDS:切除我们需要的字段 7 #: 第#个字段 8 #,#[,#]:离散的多个字段,例如1,3,6 9 #-#:连续的多个字段, 例如1-6 10 混合使用: 1-3,7
一般情况下,cut命令和tr命令配合使用可以得到很好的效果,我们以上面的问题为例,看看如何切出我们的数据,在这我先使用一下一个文本排序工具sort,接下来我们用tr,sort,配合cut来截取我们想要的内容;
1 [root@CT71 tmp]# df -h | tr -s " " % |sort -t "%" -k 5 -nr | cut -d "%" -f 5 | head -1 2 17
17就是我们最后想要的结果啦!
文本排序sort
1 命令:sort 2 格式:sort [option] filename 3 选项: 4 -r 执行反方向(由上至下)整理 5 -n 执行按数字大小整理 6 -f 选项忽略(fold)字符串中的字符大小写 7 -u 选项(独特, unique)删除输出中的重复行 8 -t c 选项使用c做为字段界定符 9 -k X 选项按照使用c字符分隔的X列来整理能够使用多次
文本排序功能用起来也是相当的顺手,我们需要带有一定格式的文本进行按一定规则进行排序,用起来相当的方便,在上面我们已经使用过一个sort工具了,接下来我们使用其他的参数做一个演示:
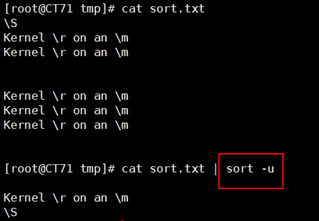
在我们的很多文本中会有很多重复的行,并且这些重复的行信息都是一样的,这时候我们想要把它们合并成一行,有时候我们甚至想要看看这些重复的行到底有多少,这时候我们就可以用到一个工具uniq将重复行删掉并统计重复的信息。
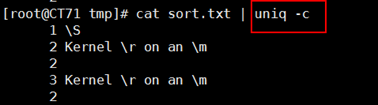
uniq命令:从输入中删除前后相接的重复的行
1 uniq [OPTION]... [FILE]... 2 -c: 显示每行重复出现的次数 3 -d: 仅显示重复过的行 4 -u: 仅显示不曾重复的行 5 连续且完全相同方为重复 6 常和sort 命令一起配合使用: 7 sort userlist.txt | uniq –c
文件合并paste
paste 合并两个文件同行号的列到一行
1 paste [OPTION]... [FILE]... 2 -d 分隔符:指定分隔符,默认用TAB 3 -s : 所有行合成一行显示
我们以一个例子说明这个工具的用法
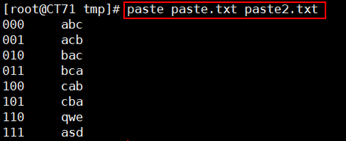
[root@CT71 tmp]# paste -d "$" paste.txt paste2.txt 000$abc 001$acb 010$bac 011$bca 100$cab 101$cba 110$qwe 111$asd [root@CT71 tmp]# paste -s paste.txt 000 001 010 011 100 101 110 111
文本数据统计wc
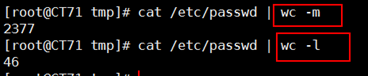
有些时候我们需要对文本的数据进行统计,看看有多少个单词没有多少行等等,wc工具就还可以帮助我们得到我们想要的信息,wc的意思是word count的意思,不能理解成我们日常要去的地方。
1 命令:wc 2 格式:wc [option] filename 3 选项: 4 -l:来只计数行数 5 -w:来只计数单词总数 6 -c:来只计数字节总数 7 -m:来只计数字符总数
在默认情况下wc统计的是行数,字符数和字节数,我们也可以通过参数来获取我们想要的信息,比如:
diff与patch
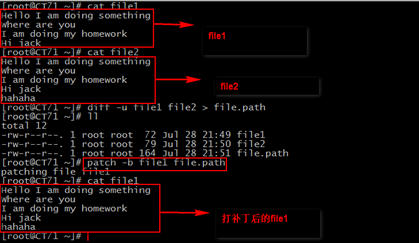
我们可以利用diff用于比较两个文件内容的不同之处,有一定的可读性,但是我们一般是将diff工具用于比较两个文件不同并打补丁,用于给旧文件打补丁,将旧文件更新到与当前新文件内容一致。就好像我们安装过QQ后,更新QQ并不是重新下载安装,因为他只是将我们的旧版QQ打上补丁更新到现在的新版本。
比较文件输出补丁
diff -u file1 file2 > file.patch
打补丁
patch -b file1 file.patch
打完补丁,file1文件就和file2文件内容一致了