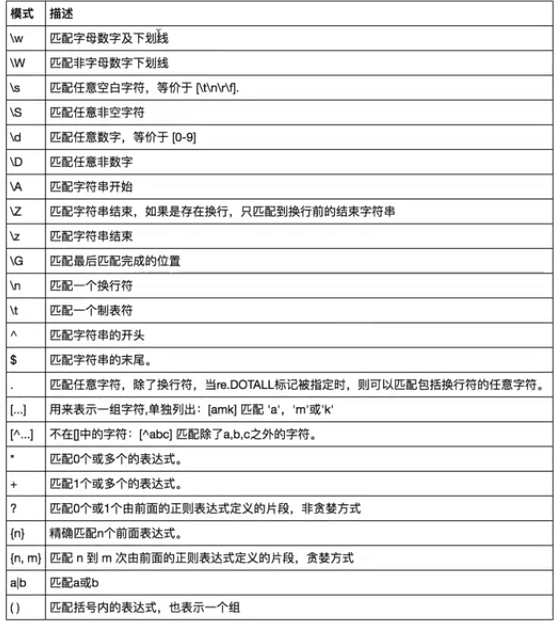
1 # 最常规的匹配 2 import re 3 content = 'Hello 123 4567 World_This is a Regex Demo' 4 print(len(content)) 5 result = re.match('^Hellosdddsd{4}sw{10}.*Demo$', content) 6 print(result) 7 print(result.group()) 8 print(result.span()) 9 10 # 泛匹配 11 import re 12 content = 'Hello 123 4567 World_This is a Regex Demo' 13 print(len(content)) 14 result = re.match('^Hello.*Demo$', content) 15 print(result) 16 print(result.group()) 17 print(result.span()) 18 19 # 匹配目标 20 import re 21 content = 'Hello 1234567 World_This is a Regex Demo' 22 print(len(content)) 23 # # 注意匹配字符串里面带小括号的用法 24 result = re.match('^Hellos(d+)sWorld.*Demo$', content) 25 print(result) 26 print(result.group(1)) 27 print(result.span()) 28 29 # 贪婪匹配 30 import re 31 content = 'Hello 1234567 World_This is a Regex Demo' 32 result = re.match('^He.*(d+).*Demo$', content) 33 print(result) 34 print(result.group(1)) 35 36 # 非贪婪匹配 37 import re 38 content = 'Hello 1234567 World_This is a Regex Demo' 39 # 多了一个问号变成了非贪婪匹配 40 result = re.match('^He.*?(d+).*Demo$', content) 41 print(result) 42 print(result.group(1)) 43 44 # 匹配模式 45 import re 46 content = '''Hello 1234567 World_This 47 is a Regex Demo 48 ''' 49 # .可以匹配处了换行符以外的所有字符, 后面加上re.S就可以匹配任意字符了 50 result = re.match('^He.*?(d+).*?Demo$', content, re.S) 51 print(result) 52 print(result.group(1)) 53 54 # 特殊符号用转义 55 import re 56 content = 'price is $5.00' 57 result = re.match('price is $5.00', content) 58 print(result) 59 60 # 尽量使用泛匹配、使用括号得到匹配目标、尽量使用非贪婪模式、有换行符就用re.S 61 62 # re.search 63 # re.search 扫描整个字符串并返回第一个成功的匹配 64 # re.match 是从字符串首字母开始匹配 65 import re 66 content = 'Extra strings Hello 1234567 World_This is a Regex Demo' 67 result = re.search('Hello.*?(d+).*?Demo', content) 68 print(result) 69 print(result.group(1)) 70 71 # 总结:为匹配方便,能用search就不用match