一、文件的操作流程
1、打开文件,得到文件句柄并赋值给一个变量
2、通过句柄对文件进行操作
3、关闭文件
二、文件的打开与关闭
A、文件的打开——open函数
语法:open(file[,mode[,buffering[,encoding[,errors[,newline[,closefd=True]]]]]])
[参数说明]:
file——文件的位置+文件的名字,需要加引号 [注]:若不指明文件的位置,则默认其位于当前文件夹下
mode——文件的的打开模式
| mode的取值 | 作用 |
| 'r' | 以只读的方式打开文件。文件的指针会放在文件的开头。这是默认模式 |
| 'rb' | 以二进制的格式打开一个文件用于只读。文件指针会放在文件的开头 |
| 'r+' | 打开一个文件用于读写。文件指针将会放在文件的开头 |
| 'rb+' | 以二进制的格式打开一个文件用于读写。文件指针将会放在文件的开头 |
| 'w' | 打开一个文件只用于写入。如果该文件已经存在则将其覆盖。如果该文件不存在,则创建新文件 |
| 'wb' | 以二进制格式打开一个文件只用于写入。如果该文件已经存在则将其覆盖。如果该文件不存在,则创建新的文件 |
| 'w+' | 打开一个文件用于写读。如果该文件已经存在则将其覆盖。如果该文件不存在则创建新的文件 |
| 'wb+' | 以二进制的格式打开一个文件用于写读。如果该文件已经存在则将其覆盖。如果该文件不存在则创建新的文件 |
| 'a' | 打开一个文件用于追加。如果该文件存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,则创建新的文件进行写入 |
| ''ab | 以二进制的格式打开一个文件用于追加。如果该文件已经存在,文件指针将会放在文件的结尾。如果文件不存在,则创建新的文件进行写入 |
| 'a+' | 打开一个文件进行读写。如果该文件已经存在,文件指针将会放在文件的结尾,文件打开时会是追加模式。如果该文件不存在,则创建新的文件用于读写 |
| 'ab+' | 以二进制的格式打开一个文件用于读写。如果该文件已经存在,文件指针将会放在文件的结尾,文件打开时会是追加模式。如果该文件不存在,则创建的新的文件用于读写 |
[特别注意1]:r+、w+、a+的区别
r+: 具有读写属性,保留原文件中没有被覆盖的内容,该文件必须存在。所写内容添加在原有文件内容之后
1 f=open('example.txt','r+',encoding='utf-8') 2 print(f.readline().strip()) 3 print(f.readline().strip()) 4 f.write('这是新添加的一行 ') 5 print(f.readline().strip())

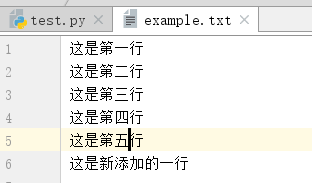
w+:具有写读属性,写的时候如果文件存在,会被清空,从头开始写,但可以从文件中读取所写的内容(一般需要借助seek方法)
1 f=open('example.txt','w+',encoding='utf-8') 2 print(f.readline().strip())#pycharm中没有任何输出 3 print(f.readline().strip()) 4 f.write('这是新添加的一行 ') 5 print(f.readline().strip())
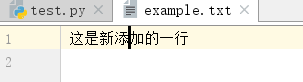
a+:a是追加操作,只能写不能读;a+也是追加操作,但既能读也能写
[特别注意2]:"U"表示在读取时,可以将
自动转换成
(与 r 或 r+ 模式同时使用),如‘rU’、‘’r+U
buffering——可以取0,1,大于1的整数或负数
| buffering的取值 | 作用 |
| 0 | 访问文件时不会有寄存(buffer) |
| 1 | 访问文件时会寄存行,即line buffer(只使用于文本模式) |
| 大于1的整数 | 设置访问文件时寄存区的缓冲大小 |
| 负数 | 访问文件时的寄存区的缓冲大小为系统默认 |
encoding——表示返回的数据采用何种编码,一般采用utf-8或者gbk
errors——取值一般有strict、ignore,当取strict的时候,字符编码若出现问题会报错;当取ignore的时候,字符编码如出现问题,程序会忽略而过,继续执行下面的程序
newline——可以取得值有None, , , ;用于区分换行符,但这个参数只对文本模式有效
closefd——可以取True或False,默认情况下取True
| closefd的取值 | 作用 |
| True | 传入的file参数为文件的文件名 |
| False |
传入的file参数为文件的文件描述符(文件描述符就是一个非负整数,在Unix内核的系统中,打开一个文件,便会返回一个文件描述符) |
B、文件的关闭
方法一、fileObjiec.close() 方法
1 try: 2 file=open('example.txt','r')# 打开一个文件 3 #...对文件的操作 4 except FileNotFoundError:#也可以是其他异常 5 #...对异常的处理 6 finally: 7 file.close() #关闭文件
[注]:关闭文件后不能再进行读写操作
方法二、with
1 with open('example.txt',''r) as f: 2 f.read() 3 #....对文件的其他操作
三、文件对象的常用属性
| 属性 | 描述 |
| file.name | 显示文件的名字 |
| file.closed | 判断文件是否关闭。如果文件被关闭,返回True |
| file.mode | 显示文件的打开模式 |
| file.encoding | 显示文件的编码类型 |
|
file.newlines |
显示文件使用的换行模式 |
1 with open('example.txt','w') as f: 2 print(f.name) 3 print(f.closed) 4 print(f.mode) 5 print(f.encoding) 6 print(f.newlines)

四、文件的常用操作
A、文件的读取
1.file.read([size]):从文件读取指定的字节数,如果没有给定size参数或size参数为负值则读取文件中的所有内容
2.file.readline([size]):从文件读取整行,包括‘ ’字符。如果制定了一个非负数的参数,则返回指定大小的字节数,包括‘ ’字符
1 with open('example.txt','r') as f: 2 while True: 3 line=f.readline() 4 if line: 5 print(line) 6 else: 7 break
3.file.readlines(sizeint):读取文件的所有行(直到结束符EOF)并返回列表,若给定的sizeint>0,返回总和大约为sizeint字节的行,实际读取值可能比sizeint较大,因为需要填充缓冲区。如果碰到结束符EOF则返回空字符串。
1 with open('example.txt','r') as f: 2 lines=f.readlines() #一次读取多行 3 for line in lines: 4 print(line)
B、文件的写入
1.file.write([str]):向文件中写入指定的字符串。
[注]:在文件关闭前或缓冲区刷新前,字符串内容存储在缓冲区中,这是你在文件中是看不到写入的内容的
1 with open('example.txt','w+') as f: 2 content='...' #想写入文件中的内容 3 f.write(content)
2.file.writelines([str]):把列表中存储的内容写入文件
[注]:
(1)换行需要制定换行符
(2)writelines()写文件的速度更快。如果需要写入文件的字符串非常多,可以考虑使用writelines(),如果只考虑写入少量的字符串,则可以直接使用write()
1 with open('example.txt','w') as f: 2 content=['My name is Tomwenxing ','I am 23 years old this year ','I hope I can have a good job '] 3 f.writelines(content)

C、文件的定位
1.file.seek(offset[,whence]):用于移动文件读取指针到指定位置
[参数说明]:
offset——开始的偏移量,也就是代表需要移动偏移的字节数
whence——可选,默认值为0.给offsert参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起
2.file.tell():返回文件的当前位置,即文件指针当前位置
3.file.__next__():返回文件的下一行,如果到达文件结尾(EOF),则触发StopIteration
[注]:在Python2.x中是file.next()
1 with open('example.txt','r') as f: 2 for index in range(3): 3 line=f.__next__() 4 print('第%d行-%s' %(index,line.strip()))

D、文件的其他重要操作
1.file.flush():刷新缓冲区,即将缓冲区中的数据立刻写入文件,同时清空缓冲区,不需要被动的等待输出缓冲区写入
[注]:一般情况下,文件关闭后会自动刷新缓冲区,但使用flush()方法可以手动的刷新缓冲区,从而将缓冲区中的内容写入到打开的文件当中
2.file.isatty():检测文件是否连到一个终端设备,如果是返回True,否则返回False
[注]:在linux中,一切皆为文件,故可以利用此方法判断一个文件代表的是否是一个终端设备
3.file.fileno():返回底层实现使用的整数文件描述符,以从操作系统请求I/O操作
4.file.truncate([size]):用于截断文件,如果指定了可选参数size,则表示截断文件为size个字符。如果没有指定size,则从当前位置起截断;截断之后size后面的所有字符被删除
[注]:
(1)此方法不会在文件处于“只读模式”时打开
(2)如果指定的大小超过了文件当前的大小,其最终的结果依赖于平台
(3)如果打开文件之后就调用truncate方法且不指定size参数的大小,则其效果与清空文件相同
1 f=open('example.txt','r+') 2 print('Name of the file:',f.name) 3 #文件内容如下: 4 #This is the 1st line 5 #This is the 2nd line 6 #This is the 3rd line 7 #This is the 4th line 8 #This is the 5th line 9 print('Read Line: %s' %f.readline()) 10 f.truncate() 11 print('Read Line: %s' %f.readline()) 12 f.close()

1 f=open('example.txt','r+') 2 print('Name of the file:',f.name) 3 #文件内容如下: 4 #This is the 1st line 5 #This is the 2nd line 6 #This is the 3rd line 7 #This is the 4th line 8 #This is the 5th line 9 f.truncate(10) 10 print('数据读取:',f.read())

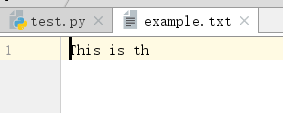
5.file.readable():如果打开文件在读模式下(包括'r',‘r+’,‘a+’等),返回True,否则返回False
6.file.writable():如果打开文件在写模式下(包括‘w’,‘w+’,‘a’,‘a+’等),返回True,否则返回False
1 f=open('example.txt','a',encoding='utf-8') 2 print(f.readable()) 3 print(f.writable())
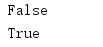
1 f=open('example.txt','a+',encoding='utf-8') 2 print(f.readable()) 3 print(f.writable())

7.file.seekable():如果该文件对象支持seek()方法,返回True,否则返回False
[注]:并不是所有的文件都支持seek方法