操作系统:CentOS-6.6
Redis:4.0.9
知识点
—— redis集群是从redis3.0之后的版本才有的,redis3.0之前的版本是搭不了集群的。
—— redis集群中没有特定入口,链接任意节点都可以。redis集群内置了16384个slot,会分配到每个主节点,例:节点1-(0-5460),节点2-(5461-10922),节点3-(10923-13684)。当存入值得时候,会通过一个算法crc16(key)%16384得到一个数字,这个数字就是要存入的slot。
—— redis各个节点都是互联的,当一个节点向目标节点发送PING命令时,目标节点如若没有在有效时限内回复PING命令,那么发送命令的节点会为目标节点标记一个状态PFAIL(possible failure 可能已失效),并将目标节点可能已失效广播给其它节点。当节点收到某一节点被标记为PEAIL转态它会记下这个节点,在集群中如果有超过半数的节点认为某一节点可能已失效,则标记这一节点的状态为FAIL(已失效)。
—— redis中当一个节点失效了,如果该节点有从节点,则从节点顶上,否则集群就挂了。
—— redis集群至少要有6台服务器,其中3个节点,3个从节点。因为集群中标记一个节点已失效至少要有超过半数的节点认为某一节点失效,所以需要至少3个节点。如果其中一个及节点失效了,没有从节点顶上,那集群就挂了,所以需要3个从节点做替补。
搭建集群
—— 这里不描述redis安装过程,假设已经安装成功。
—— 首先关闭防火墙,因为是搭建伪集群,是在同一台服务器上部署6个redis实例,不确定会占用哪些端口。
—— redis实例,这是一个redis实例,嗯。
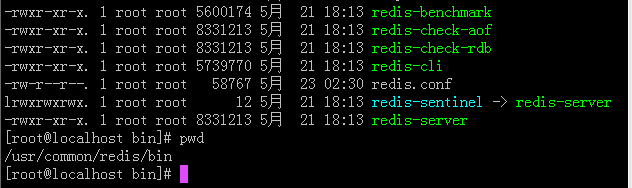
—— 创建一个文件,存放redis实例,名称位置随意。

—— 复制一个redis实例到 redis-cluster文件,如果实例中有dump.rdb文件,删除dump.rdb。
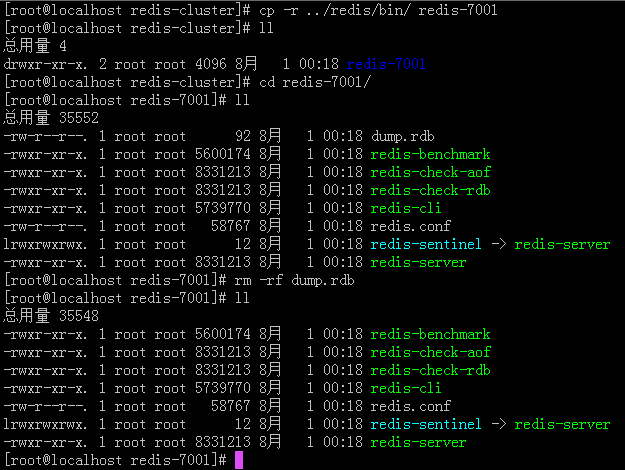
—— 修改redis.conf文件
—— port 7001 #端口
—— cluster-enabled yes #此redis实例作为集群的一个节点
—— cluster-node-timeout 15000 #节点能够失联的最大时间
—— cluster-config-file nodes-7001.conf #集群配置文件,系统自动维护,不能人工编辑,主要记录集群中有哪些节点,状态等参数
—— pidfile /var/run/redis_7001.pid #redis以守护进程方式运行时,系统默认会把pid写入/var/run/redis_7001.pid
—— 复制刚刚修改过的redis实例,最后一共6个
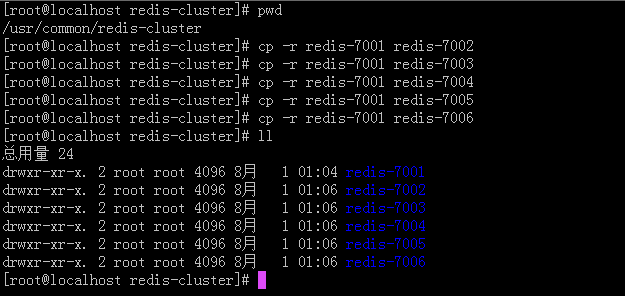
—— 修改redis.conf文件。
—— port对应7001-7006
—— cluster-config-file对应nodes-7001.conf-nodes-7006.conf
—— pidfile对应/var/run/redis_7001.pid - redis_7006.pid
—— 创建一个批处理文件,启动所有的redis实例。
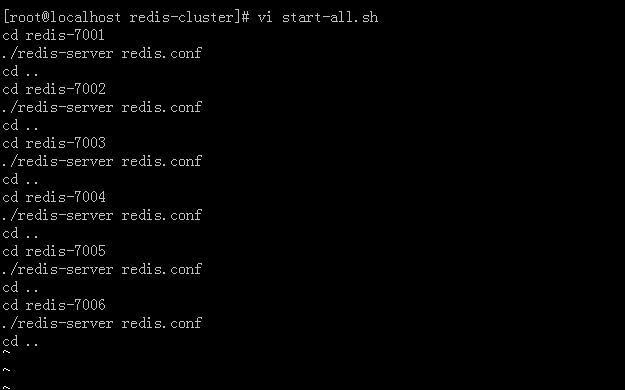
—— 修改satrt-all.sh文件可执行权限。
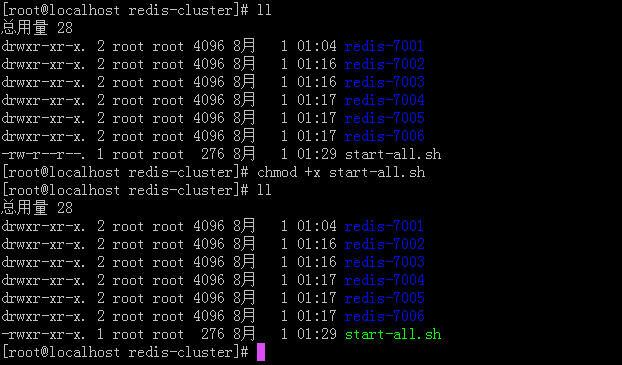
—— 执行批处理文件start-all.sh,启动所有redis实例。
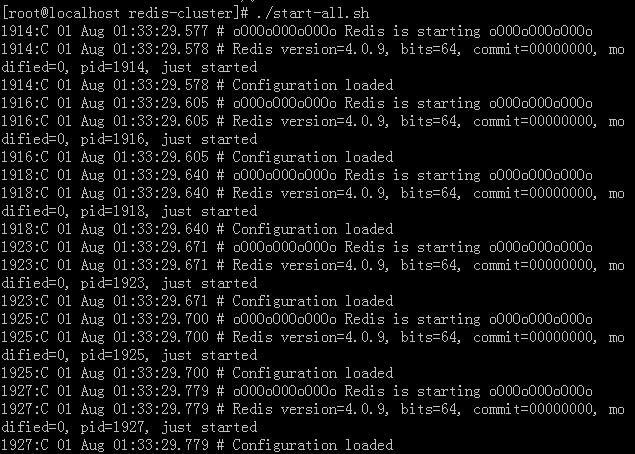
—— 查看redis进程。
—— 集群搭建需要ruby的运行环境,安装ruby。 安装过程中如果需要输入,全部输入y或yes。为什么要ruby环境,因为要执行一个redis-trib.rb的脚本。
—— yum install ruby
—— yum install rubygems
—— 使用gem命令安装redis接口,gem是ruby的一个工具包。
—— 如果报错了,像这样,说明ruby版本太低升级ruby。

—— 升级ruby需要rvm,使用命令 rvm -v 看一下是否已经安装rvm
—— 如果没有安装rvm,安装rvm需要curl命令,如果没有curl命令安装curl命令:yum install curl
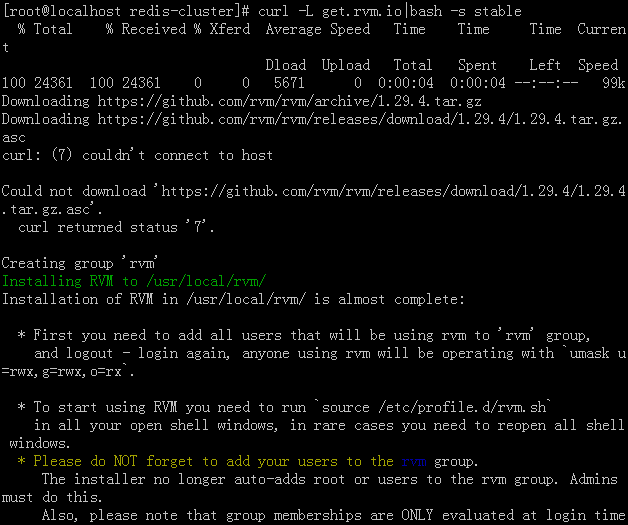
—— 在执行curl -L get.rvm.io|bash -s stable命令时,有的提示需要安装一个key,所以需要去获取一个key,怎么获取百度问百度。
—— 让rvm生效
—— 通过rvm list known命令可以查看ruby可以安装的版本
—— 安装ruby2.4.1版本
—— 安装ruby-redis插件
—— 将redis源码包下src目录中的redis-trib.rb脚本复制到存放redis实例的文件夹下。
—— 补充一句装了半天的环境,其实就是为了能运行这个redis-trib.rb的脚本,使用ruby的redis-trib.rb搭建集群。
—— 接下来执行命令:./redis-trib.rb create --replicas 1 192.168.229.128:7001 192.168.229.128:7002 192.168.229.128:7003 192.168.229.128:7004 192.168.229.128:7005 192.168.229.128:7006
—— --replicas 1 代表每个节点有一个备份机,redis集群至少要有三个节点,每个节点有一个备份机,就代表一共有6个节点,所以后面要跟上6个IP+端口。
—— 192.168.229.128 代表你本机的IP,至于端口就是上面配置的那些。
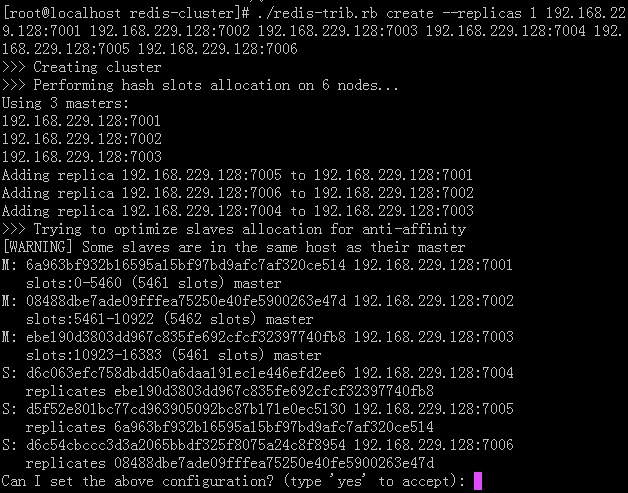
—— 这里解释一下:
—— Performing hash slots allocation on 6 nodes... # 代表一共有6个节点
—— Using 3 masters: # 有三个主节点 分别是端口 7001、7002、7003
—— Adding replica 192.168.229.128:7005 to 192.168.229.128:7001 # 端口7005的节点是端口7001节点的从节点,以此类推
—— M: 6a963bf932b16595a15bf97bd9afc7af320ce514 192.168.229.128:7001 # 前面内一串是ID唯一标识
—— slots:0-5460 (5461 slots) master # 代表当前节点的哈希槽为0-5460,主节点才有哈希槽,redis集群中内置了16384(0-16383)个哈希槽。
—— 然后yes,开始搭建

—— 到此redis集群就搭完了。
测试
—— 链接redis客户端:reds-cli
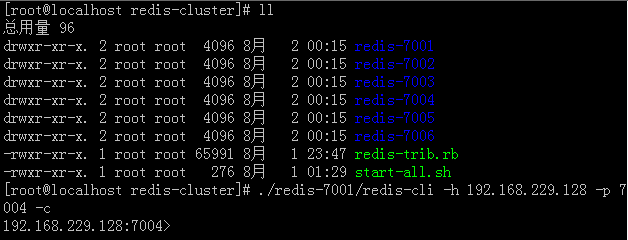
—— redis集群是没有指定入口的,所以连哪个客户端都可以,当然同样的连哪个端口都可以,包括从节点。
—— -h 对应的IP地址,不写的话默认就是本机,这里之所以写上,就是为了做笔记,嗯。
—— -p 对应的是端口,哪个端口都可以,但是必须是及群中redis实例中的,这句话第一个逗号后面都是为了凑字数,长点好看。
—— -c 这是必须的,代表集群启动,这是集群启动与单机启动唯一的区别。
—— 存几个值试试
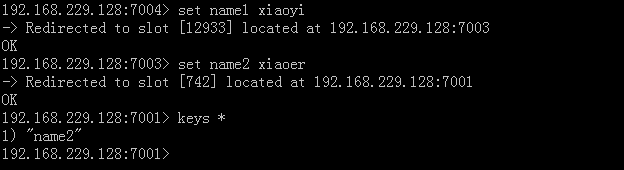
—— [12933]、[742]代表的是通过算法计算出的当前key的哈希槽,每个节点都有对应的哈希槽范围,存储的的数据是根据key的哈希槽存储到对应节点。
—— 应该没啥可记得了……
参考文章
—— https://blog.csdn.net/mysqldba23/article/details/67640478
—— https://blog.csdn.net/qq_36318234/article/details/80007358