import包:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SQLContext}
样例类:
case class Person(id:Int,name:String,age:Int)
主函数:
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setAppName(this.getClass.getName).setMaster("local")
val sparkContext = new SparkContext(sparkConf)
val sqlContext = new SQLContext(sparkContext)
val rdd: RDD[String] = sparkContext.textFile("C:\Users\dummy\Desktop\person.txt")
val lineRdd: RDD[Array[String]] = rdd.map(_.split(" "))
InferringSchema(lineRdd,sqlContext)
SpecifyingSchema(lineRdd,sqlContext)
sparkContext.stop()
}
第一种方法:(需要创建样例类)
/**
* 通过反射推断Schema
* @param lineRdd
* @param sqlContext
*/
def InferringSchema(lineRdd: RDD[Array[String]],sqlContext:SQLContext): Unit ={
//将RDD和case class关联
val personRdd: RDD[Person] = lineRdd.map(x=>Person(x(0).toInt,x(1),x(2).toInt))
//导入隐式转换,如果不导入无法将RDD转换成DataFrame
import sqlContext.implicits._
//将RDD转换成DataFrame
val personDF: DataFrame = personRdd.toDF()
personDF.show()
//注册一张临时表
//personDF.registerTempTable("person")
//val personDF2: DataFrame = sqlContext.sql("select * from person")
//将结果以JSON的方式存储到指定位置
//personDF2.write.json("C:\Users\dummy\Desktop\out")
//personDF2.show()
}
第二种方法:
/**
* 通过StructType直接指定Schema
* @param lineRdd
* @param sqlContext
*/
def SpecifyingSchema(lineRdd: RDD[Array[String]],sqlContext:SQLContext): Unit ={
//通过StructType直接指定每个字段的schema
val schema=StructType(
List(
/**StructField只需传入前面两个参数即可
* name: String,
* dataType: DataType,
* nullable: Boolean = true,
* metadata: Metadata = Metadata.empty)
*/
StructField("id",IntegerType),
StructField("name",StringType),
StructField("age",IntegerType)
)
)
val rowRdd: RDD[Row] = lineRdd.map(x=>Row(x(0).toInt,x(1),x(2).toInt))
val personDF: DataFrame = sqlContext.createDataFrame(rowRdd,schema)
//personDF.show()
personDF.registerTempTable("person")
val personDF2: DataFrame = sqlContext.sql("select * from person")
//personDF2.write.json("C:\Users\dummy\Desktop\out")
personDF2.show()
}
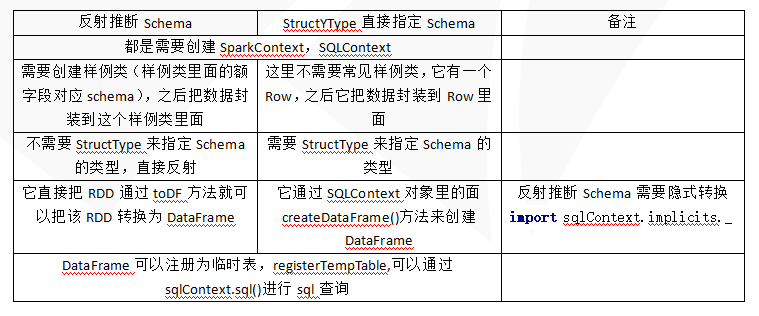
对比: