在之前的文章中Spark的demo对RDD的简单操作,通过学习《Spark快速大数据分析》,记录一下对RDD的详细操作
1.转化操作
map
我们可以使用map()来做各种各样的事情:可以把我们的URL集合中的每个URL对应的
主机名提取出来,也可以简单到只对各个数字求平方值。map()的返回值类型不需要和输
入类型一样。这样如果有一个字符串RDD,并且我们的map()函数是用来把字符串解析
并返回一个Double值的,那么此时我们的输入RDD类型就是RDD[String],而输出类型
是RDD[Double]。
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD<Integer> result = rdd.map(new Function<Integer, Integer>() {
public Integer call(Integer x) { return x*x; }
});
System.out.println(StringUtils.join(result.collect(), ","));
flatMap
有时候,我们希望对每个输入元素生成多个输出元素。实现该功能的操作叫作flatMap()。
和map()类似,我们提供给flatMap()的函数被分别应用到了输入RDD的每个元素上。不
过返回的不是一个元素,而是一个返回值序列的迭代器。输出的RDD倒不是由迭代器组
成的。我们得到的是一个包含各个迭代器可访问的所有元素的RDD。
JavaRDD<String> lines = sc.parallelize(Arrays.asList("hello world", "hi"));
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
public Iterable<String> call(String line) {
return Arrays.asList(line.split(" "));
}
});
words.first(); // 返回"hello"
distinct()
我们的RDD中最常缺失的集合属性是元素的唯一性,因为常常有重复的元素。如果只
要唯一的元素,我们可以使用RDD.distinct()转化操作来生成一个只包含不同元素的新
RDD。不过需要注意,distinct()操作的开销很大,因为它需要将所有数据通过网络进行
混洗(shuffle),以确保每个元素都只有一份。第4章会详细介绍数据混洗,以及如何避免
数据混洗。
在例子中还有一些其他的操作:
filter
JavaRDD<String> errorLines = lines.filter (new Function<String, Boolean>() {
@Override
public Boolean call(String v1) throws Exception {
return v1.contains( "error");
}
});
foreach
badLines.foreach(new VoidFunction<String>() {
@Override
public void call(String t) throws Exception {
System. out.println(t);
}
});

2.集合的操作(也属于转化操作)

3.行动操作
reduce()
你很有可能会用到基本
RDD
上最常见的行动操作reduce()。它接收一个函数作为参数,这个
函数要操作两个
RDD
的元素类型的数据并返回一个同样类型的新元素。一个简单的例子就
是函数
+,可以用它来对我们的RDD
进行累加。使用
reduce(),可以很方便地计算出RDD
中所有元素的总和、元素的个数,以及其他类型的聚合操作
aggregate()
Integer sum = rdd.reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer x, Integer y) { return x + y; }
});
例:
JavaRDD<Integer> lines = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
Integer aaa = lines.reduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
System.out.println(aaa);//结果为55
fold()
fold()
和reduce()
类似,接收一个与
reduce()
接收的函数签名相同的函数,再加上一个
“初始值”来作为每个分区第一次调用时的结果。你所提供的初始值应当是你提供的操作
的单位元素;也就是说,使用你的函数对这个初始值进行多次计算不会改变结果(例如
+
对应的0,
*
对应的1
,或拼接操作对应的空列表)。
JavaRDD<Integer> lines = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
Integer aaa = lines.fold(100, new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
System.out.println(aaa);//结果为255
aggregate()
public class AvgCount implements Serializable{
public AvgCount( int total, int num) {
this. total = total;
this. num = num;
}
public int total;
public int num;
public double avg() {
return total / ( double) num;
}
}
JavaRDD<Integer> lines = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
AvgCount initial = new AvgCount(0, 0);
Function2<AvgCount, Integer, AvgCount> addAndCount = new Function2<AvgCount, Integer, AvgCount>() {
public AvgCount call(AvgCount a, Integer x) {
a.total += x;
a.num += 1;
return a;
}
};
Function2<AvgCount, AvgCount, AvgCount> combine = new Function2<AvgCount, AvgCount, AvgCount>() {
public AvgCount call(AvgCount a, AvgCount b) {
a.total += b.total;
a.num += b.num;
return a;
}
};
AvgCount result = lines.aggregate(initial, addAndCount, combine);
System.out.println(result.avg());

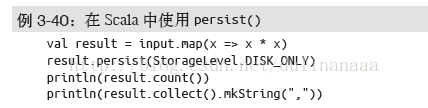
4.持久化
persist()
unpersist()