1、基本概念
多进程主要用multiprocessing和mpi4py这两个模块。
multiprocessing是Python标准库中的模块,实现了共享内存机制,可以让运行在不同处理器核心的进程能读取共享内存。
mpi4py库实现了消息传递的编程范例(设计模式)。简单来说就是进程之间不靠任何共享信息来进行通讯,所有的交流都通过传递信息代替。
这与使用共享内存通讯、加锁或类似机制实现互斥的技术形成对比。在信息传递的代码中,进程通过send和receive进行交流。
2、创建一个进程
由父进程创建子进程。父进程既可以在产生子进程之后继续异步执行,也可以暂停等待子进程创建完成之后再继续执行。创建进程的步骤如下:
1. 创建进程对象
2. 调用start()方法,开启进程的活动
3. 调用join()方法,在进程结束之前一直等待
3、创建进程用例
# coding : utf-8 import multiprocessing def foo(i): print('called function in process: %s' %i) return if __name__ == '__main__': Process_jobs = [] for i in range(5): p = multiprocessing.Process(target=foo, args=(i, )) Process_jobs.append(p) p.start() p.join()
运行结果:
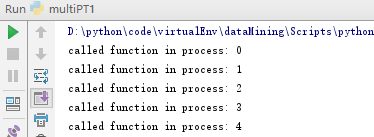
创建进程对象的时候需要分配一个函数,作为进程的执行任务,本例为foo()。最后进程对象调用join()方法,如果没有join主进程退出之后子进程会留在idle中。
提示:为了预防无限递归调用,可以在不同脚本文件中定义目标函数,然后导入进来使用。
4、进程命名
进程命名和线程命名大同小异。
使用示例:
# coding:utf-8 import multiprocessing import time def foo(): # get name of process name = multiprocessing.current_process().name print("Starting %s " %name) time.sleep(3) print("Exiting %s " %name) if __name__ == '__main__': # create process with DIY name process_with_name = multiprocessing.Process(name='foo_process', target=foo) # process_with_name.daemon = True # create process with default name process_with_default_name = multiprocessing.Process(target=foo) process_with_name.start() process_with_default_name.start()
5、杀死一个进程
通过terminate方法杀死一个进程,也可以使用is_alive方法判断一个进程是否存活。
测试用例:
import multiprocessing, time def foo(): print('Starting function') time.sleep(0.1) print('Finished function') if __name__ == '__main__': p = multiprocessing.Process(target=foo) print('Process before execution:', p, p.is_alive()) p.start() print('Process running:', p, p.is_alive()) p.terminate() print('Process terminated:', p, p.is_alive()) p.join() print('Process joined:', p, p.is_alive()) print('Process exit code:',p.exitcode)
运行结果:
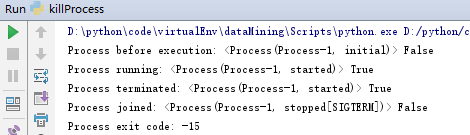
正常结束返回值为0,且foo会被执行。exitcode为0为正常结束,为负表示信号杀死,大于0进程有错误。
6、子类中使用进程
实现一个自定义的进程子类,需要以下三步:
- 定义Process子类
- 覆盖__init__(self [,args])方法来添加额外的参数
- 覆盖run方法来实现Process启动的时候执行的任务
创建Process子类之后,可以创建它的实例。并且通过start方法启动它,启动之后会运行run方法。
测试用例:
# coding:utf-8 import multiprocessing class MyProcess(multiprocessing.Process): def run(self): print('called run method in process: %s' %self.name) return if __name__ == '__main__': jobs = [] for i in range(5): p = MyProcess() jobs.append(p) p.start() p.join()
运行结果:
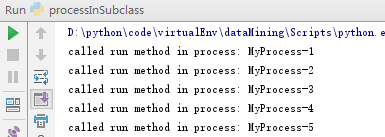
7、进程之间交换对象
并行应用常常需要在进程之间交换数据。Multiprocessing库有两个Communication Channel可以交换对象:队列queue和管道pipe。
使用队列交换对象:
Queue返回一个进程共享的队列,是线程安全的,也是进程安全的。任何可序列化的对象(Python通过pickable模块序列化对象)都可以通过它进行交换。
测试用例:
import multiprocessing import random import time class Producer(multiprocessing.Process): def __init__(self, queue): multiprocessing.Process.__init__(self) self.queue = queue def run(self): for i in range(10): item = random.randint(0,256) self.queue.put(item) print("Process Producer:item %d appended to queue %s" %(item, self.name)) time.sleep(1) print("The size of queue is %s" % self.queue.qsize()) class Consumer(multiprocessing.Process): def __init__(self, queue): multiprocessing.Process.__init__(self) self.queue = queue def run(self): while True: if self.queue.empty(): print("The queue is empty") break else: time.sleep(2) item = self.queue.get() print("Process Consumer:item %d popped from by %s " %(item, self.name)) time.sleep(1) if __name__ == "__main__": # create Queue in the main process queue = multiprocessing.Queue() # create process_producer = Producer(queue) process_consumer = Consumer(queue) process_producer.start() process_consumer.start() process_producer.join() process_consumer.join()
运行结果:
Process Producer:item 106 appended to queue Producer-1 The size of queue is 1 Process Producer:item 167 appended to queue Producer-1 The size of queue is 2 Process Producer:item 202 appended to queue Producer-1 Process Consumer:item 106 popped from by Consumer-2 The size of queue is 2 Process Producer:item 124 appended to queue Producer-1 The size of queue is 3 Process Producer:item 19 appended to queue Producer-1 The size of queue is 4 Process Producer:item 5 appended to queue Producer-1 Process Consumer:item 167 popped from by Consumer-2 The size of queue is 4 Process Producer:item 178 appended to queue Producer-1 The size of queue is 5 Process Producer:item 207 appended to queue Producer-1 The size of queue is 6 Process Producer:item 154 appended to queue Producer-1 Process Consumer:item 202 popped from by Consumer-2 The size of queue is 6 Process Producer:item 228 appended to queue Producer-1 The size of queue is 7 Process Consumer:item 124 popped from by Consumer-2 Process Consumer:item 19 popped from by Consumer-2 Process Consumer:item 5 popped from by Consumer-2 Process Consumer:item 178 popped from by Consumer-2 Process Consumer:item 207 popped from by Consumer-2 Process Consumer:item 154 popped from by Consumer-2 Process Consumer:item 228 popped from by Consumer-2 The queue is empty
队列补充:
队列还有一个JoinaleQueue子类,有以下两个额外的方法:
- task_done():此方法意味着之前入队的一个任务已经完成,比如,get方法从队列取回item之后调用。所以此方法只能被队列的消费者调用。
- join():此方法将进程阻塞,直到队列中的item全部被取出并执行。
因为使用队列进行通信是一个单向的、不确定的过程,所以你不知道什么时候队列的元素被取出来了,所以使用task_done来表示队列里的一个任务已经完成,这个方法一般和join一起使用,当队列的所有任务都处理之后,也就是说put到队列的每个任务都调用task_done方法后,join才会完成阻塞。
JoinaleQueue测试用例:
from multiprocessing import Process, JoinableQueue import time,random def consumer(name, q): while True: time.sleep(1) get_res = q.get() print("%s got %s" %(name, get_res)) q.task_done() def producer(seq, q): for item in seq: # time.sleep(1) q.put(item) print("Produced %s" %item) # block main process and don't run "print("Ended")" q.join() if __name__ == "__main__": q = JoinableQueue() seq = ("item-%s" %i for i in range(10)) c1 = Process(target=consumer, args=("c1", q)) c2 = Process(target=consumer, args=("c2", q)) c3 = Process(target=consumer, args=("c3", q)) c1.daemon = True c2.daemon = True c3.daemon = True c1.start() c2.start() c3.start() # start producer producer(seq,q) # run the command when all the item is consumed print("Ended")
使用管道交换对象:
一个管道可以做一下事情:
- 返回一对被管道连接的连接对象
- 然后对象使用send/receive方法可以在进程之间通信
简单示例:
import multiprocessing def create_items(pipe): output_pipe, _ = pipe for item in range(10): output_pipe.send(item) output_pipe.close() def multiply_items(pipe_1, pipe_2): close, input_pipe = pipe_1 close.close() output_pipe, _ = pipe_2 try: while True: item = input_pipe.recv() output_pipe.send(item * item) except EOFError: output_pipe.close() if __name__ == "__main__": # The first pipe sends numbers pipe_1 = multiprocessing.Pipe(True) process_pipe_1 = multiprocessing.Process(target=create_items, args=(pipe_1,)) process_pipe_1.start() # The second pipe receives numbers and Calculations pipe_2 = multiprocessing.Pipe(True) process_pipe_2 = multiprocessing.Process(target=multiply_items, args=(pipe_1, pipe_2)) process_pipe_2.start() pipe_1[0].close() pipe_2[0].close() try: while True: # print(pipe_2) print(pipe_2[1].recv()) except EOFError: print("End")
上述代码定义两个进程,一个发送数字0-9到管道pipe_1,另一个进程通过receive获取pipe_1的数字,并进行平方,然后将结果输出到管道pipe_2中。最后通过recv获取pipe_2的数据。