1、基本概念
GIL是CPython解释器引入的锁,GIL在解释器层面阻止了真正的并行运行。解释器在执行任何线程之前,必须等待当前正在运行的线程释放GIL,事实上,解释器会强迫想要运行的线程必须拿到GIL才能访问解释器的任何资源,例如栈或Python对象等,这也正是GIL的目的,为了阻止不同的线程并发访问Python对象。这样GIL可以保护解释器的内存,让垃圾回收工作正常。但事实上,这却造成了程序员无法通过并行执行多线程来提高程序的性能。如果我们去掉GIL,就可以实现真正的并行。GIL并没有影响多处理器并行的线程,只是限制了一个解释器只能有一个线程在运行。
2、测试用例
测试一:空函数
from threading import Thread def function_to_run(): pass class threads_object(Thread): def run(self): function_to_run() class nothreads_object(object): def run(self): function_to_run() def non_threaded(num_iter): funcs = [] for i in range(int(num_iter)): funcs.append(nothreads_object()) for i in funcs: i.run() def threaded(num_threads): funcs = [] for i in range(int(num_threads)): funcs.append(threads_object()) for i in funcs: i.start() for i in funcs: i.join() def show_results(func_name, results): print("%-23s %4.6f seconds" % (func_name, results)) if __name__ == "__main__": import sys from timeit import Timer repeat = 100 number = 1 num_threads = [1, 2, 4, 8] print('starting tests') for i in num_threads: t = Timer("non_threaded(%s)" % i, "from __main__ import non_threaded") best_result = min(t.repeat(repeat=repeat, number=number)) show_results("non_threaded (%s iters)" % i, best_result) t = Timer("threaded(%s)" % i, "from __main__ import threaded") best_result = min(t.repeat(repeat=repeat, number=number)) show_results("threaded (%s threads)" % i, best_result) print('Iterations complete')
下面的代码是用来评估多线程应用性能的简单代码。每一次测试都循环调用函数100次,重复执行多次,取速度最快的一次。在for循环中,调用non_threaded和threaded函数。同时,我们会不断增加调用次数和线程数来重复执行这个测试。在非线程测试中,调用函数与定义线程数一样多的次数。只需改变function_to_run的内容即可进行测试。
上面代码测试的为空函数,执行结果如下:
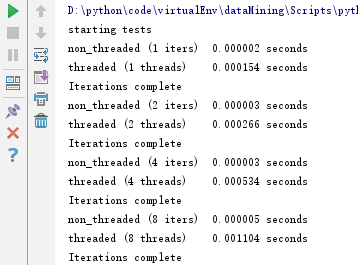
通过结果发现,使用线程的开销比不使用线程的开销大得多。
测试二:数字处理
将function_to_run改成计算斐波那契数列
def function_to_run(): # pass a, b = 0, 1 for i in range(10000): a, b = b, a + b
结果如下:
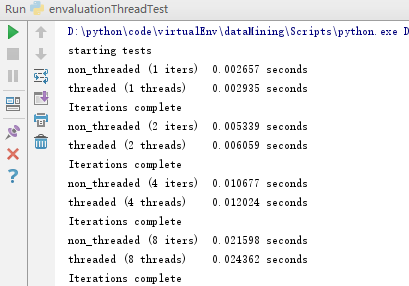
结果:提高线程的数量并没有带来收益,因为GIL和线程管理代码的开销,多线程运行永远不可能比函数顺序执行更快。GIL只允许解释器一次执行一个线程。
测试三:数据读取
更改function_to_run如下:
def function_to_run(): # pass # a, b = 0, 1 # for i in range(10000): # a, b = b, a + b fh = open("README.md","rb") size = 1024 for i in range(1000): fh.read(size)
运行结果:
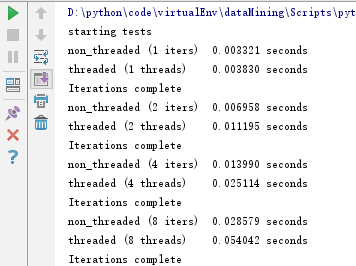
测试四:URL请求
from threading import Thread def function_to_run(): # pass # a, b = 0, 1 # for i in range(10000): # a, b = b, a + b # fh = open("README.md","rb") # size = 1024 # for i in range(1000): # fh.read(size) import urllib.request for i in range(10): with urllib.request.urlopen("https://www.baidu.com/") as f: f.read(1024) class threads_object(Thread): def run(self): function_to_run() class nothreads_object(object): def run(self): function_to_run() def non_threaded(num_iter): funcs = [] for i in range(int(num_iter)): funcs.append(nothreads_object()) for i in funcs: i.run() def threaded(num_threads): funcs = [] for i in range(int(num_threads)): funcs.append(threads_object()) for i in funcs: i.start() for i in funcs: i.join() def show_results(func_name, results): print("%-23s %4.6f seconds" % (func_name, results)) if __name__ == "__main__": import sys from timeit import Timer repeat = 100 number = 1 num_threads = [1, 2, 4, 8] print('starting tests') for i in num_threads: t = Timer("non_threaded(%s)" % i, "from __main__ import non_threaded") best_result = min(t.repeat(repeat=repeat, number=number)) show_results("non_threaded (%s iters)" % i, best_result) t = Timer("threaded(%s)" % i, "from __main__ import threaded") best_result = min(t.repeat(repeat=repeat, number=number)) show_results("threaded (%s threads)" % i, best_result) print('Iterations complete')
运行结果:
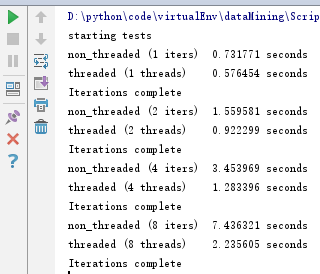
在有I/O操作时,多线程比单线程快得多。增加线程并不会提高应用启动的时间,但是可以支持并发。例如,一次性创建一个线程池,并重用worker会很有用,这可以让我们切分一个大的数据集,用同样的函数处理不同的部分。