1、主要思路
获取京东所有商品列表:https://www.jd.com/allSort.aspx,大概有分类1190条

连接格式为:https://list.jd.com/list.html?cat=xxx
页面如下:

此页面可以从该页面直接获取商品价格、商品标题、商品URL、商品ID、商品品牌、商品店铺地址、商品型号,所以在获取此页面时直接解析这些数据。
需要的数据分析:本次爬取主要获取以下信息(已评价为基础存储商品信息,可以将评价和商品分开存):


CREATE TABLE `JDAll` ( `shop_id` VARCHAR (16) NOT NULL, //商品ID `url` VARCHAR (255) DEFAULT NULL, //商品url `title` VARCHAR (1024) DEFAULT NULL, //商品标题 `brand` VARCHAR (255) DEFAULT NULL,//品牌 `brand_url` VARCHAR (1024) DEFAULT NULL,//店铺地址 `price` VARCHAR (16) DEFAULT NULL,//价格 `comment_num` INT (16) DEFAULT NULL,//评价总数 `good_comment_rate` VARCHAR (16) DEFAULT NULL,//好评率 `good_comment` VARCHAR (16) DEFAULT NULL,//好评数 `general_count` VARCHAR (16) DEFAULT NULL,//中评数 `poor_count` VARCHAR (16) DEFAULT NULL,//差评数 `hot_comment_dict` LONGTEXT,//热评信息 `default_comment_num` VARCHAR (16) DEFAULT NULL,//默认好评数 `comment_id` VARCHAR (32) NOT NULL,//评价ID,主键 `comment_context` LONGTEXT,//评价内容 `comnent_time` VARCHAR (255) DEFAULT NULL,//评价时间 `comment_score` VARCHAR (8) DEFAULT NULL,//评价星级 `comment_source` VARCHAR (255) DEFAULT NULL,//评价来源 `produce_size` VARCHAR (255) DEFAULT NULL,//商品大小 `produce_color` VARCHAR (255) DEFAULT NULL,//商品颜色 `user_level` VARCHAR (32) DEFAULT NULL,//用户会员级别 `user_exp` VARCHAR (32) DEFAULT NULL,//用户京享值 `comment_thumpup` VARCHAR (8) DEFAULT NULL,//评价点赞数 `comment_reply_content` LONGTEXT,//店家回复 `comment_reply_time` VARCHAR (255) DEFAULT NULL,//店铺回复时间 `append_comment` LONGTEXT,//买家追评 `append_comment_time` VARCHAR (255) DEFAULT NULL,//追评时间 PRIMARY KEY (`comment_id`) ) ENGINE = INNODB DEFAULT CHARSET = utf8
商品评价获取:采用京东json接口:https://club.jd.com/comment/skuProductPageComments.action?callback=fetchJSON_comment98vv46561&productId=4207732&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
可更改参数:productId=4207732(商品ID)、page=0(第几页评价)、pageSize=10(每页显示的条数)
基本评价信息:

热评信息:

主要评价:

2、代码实现
主代码:
# -*- coding: utf-8 -*- import os,sys import scrapy import json import requests from scrapy_splash import SplashRequest from scrapy.linkextractors import LinkExtractor # from scrapy.spiders import Rule,CrawlSpider from scrapy.spiders.splashcrawl import Rule,CrawlSpider from scrapy_redis.spiders import RedisSpider from ArticleSpider.items import JDAllItem lua_script = """ function main(splash) splash:go(splash.args.url) splash:wait(0.5) return splash:html() end """ class JdAllSpider(RedisSpider): name = "jd_all" redis_key = "jd:start_urls" allowed_domains = ["jd.com"] header = { 'Host': 'club.jd.com', 'Connection': 'keep-alive', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0', 'Accept-Encoding': 'gzip, deflate, sdch', 'Accept-Language': 'zh-CN,zh;q=0.8', } list_header = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, sdch', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Cache-Control': 'max-age=0', 'Connection': 'keep-alive', 'Host': 'list.jd.com', 'If-Modified-Since': 'Mon, 22 Jan 2018 06:23:20 GMT', 'Upgrade-Insecure-Requests': '1' } # rules = { # # 商品列表 # Rule(LinkExtractor(allow=r'https://list.jd.com/list.html?cat=.*'), follow=False,callback="parse_shop"), # # 匹配商品 # # Rule(LinkExtractor(allow=r'.*item.jd.com/d+.html$'), callback="parse_shop",follow=True), # # 匹配下一页 # Rule(LinkExtractor(restrict_css='a.pn-next'), follow=True,callback="parse_shop"), # } def parse(self,response): # 解析list链接 pattern = "https://list.jd.com/list.html?cat=.*" le = LinkExtractor(allow=pattern) links = le.extract_links(response) print("发现list页面共:【%s】" %len(links)) for i in links: print("-------------------->%s" %i.url) yield scrapy.Request(i.url,callback=self.next_page) #yield SplashRequest(i.url, endpoint='execute', args={'images': 0, 'lua_source': lua_script},cache_args=['lua_source'], callback=self.parse_shop) def next_page(self,response): # 获取page total page_total = int(response.css('span.fp-text i::text').extract_first()) print("开始获取下一页") for page in range(1,page_total + 1): page_url = "%s&page=%s" %(response.url,page) print("获取list:【%s】,第【%s】页。"%(response.url, page)) yield SplashRequest(page_url, args={'wait': 0.5, 'images': 0}, callback=self.parse_shop,splash_headers=self.header) # yield SplashRequest(page_url, endpoint='execute', args={'images': 0, 'lua_source': lua_script},cache_args=['lua_source'], callback=self.parse_shop,dont_filter=True) def parse_shop(self, response): sel_list = response.xpath('//div[@id="plist"]').xpath('.//li[@class="gl-item"]') for sel in sel_list: print("开始解析list页面,商品信息") url = "http:%s" %sel.css(".p-name a::attr('href')").extract_first() shop_id = url.split("/")[-1].split(".")[0] title = sel.css(".p-name a em::text").extract_first().strip(" ").strip(" ") brand = sel.css(".p-shop span a::attr('title')").extract_first() brand_url = sel.css(".p-shop span a::attr('href')").extract_first() price = sel.css(".p-price strong i::text").extract_first() session = requests.Session() print("获取%s商品评价页面" %title) comment_url = "https://club.jd.com/comment/skuProductPageComments.action?productId={shop_id}&score=0&sortType=5&page={page_num}&pageSize=10&isShadowSku=0&fold=1".format(shop_id=shop_id,page_num=0) html = session.get(comment_url, headers=self.header) print("获取商品评价页 json") try: comment_json = json.loads(html.text) except: continue # 获取评价信息 public_comment = comment_json['productCommentSummary'] # 评价数 comment_num = public_comment['commentCount'] # 获取好评率 good_comment_rate = public_comment['goodRate'] # 好评数 good_comment =public_comment['goodCount'] # 中评数 general_count = public_comment['generalCount'] # 差评 poor_count = public_comment['poorCount'] # 默认好评 default_comment_num = public_comment['defaultGoodCount'] # 获取热评信息 hot_comment = comment_json['hotCommentTagStatistics'] if len(hot_comment) == 0: hot_comment_dict = "Null" else: hot_comment_dict = {} for i in hot_comment: hot_comment_dict[i['id']] = {'name': i['name'], 'count': i['count']} hot_comment_dict = json.dumps(hot_comment_dict) shop_info = { 'url': url, 'shop_id': shop_id, 'title': title, 'brand': brand, 'brand_url': brand_url, 'price': price, 'comment_num': comment_num, 'good_comment_rate': good_comment_rate, 'good_comment': good_comment, 'general_count': general_count, 'poor_count': poor_count, 'hot_comment_dict': hot_comment_dict, 'default_comment_num': default_comment_num, } page_num = (comment_num + 9) // 10 if page_num >= 100: page_num = 100 print("【%s】评价页面共计【%s】" %(title,page_num)) for page in range(0,page_num): comment_url = "https://club.jd.com/comment/skuProductPageComments.action?productId={shop_ids}&score=0&sortType=5&page={page_nums}&pageSize=10&isShadowSku=0&fold=1".format(shop_ids=shop_id,page_nums=page) print("yield评价第%s页"%page) yield scrapy.Request(comment_url,meta=shop_info,headers=self.header,callback=self.parse_comment) def parse_comment(self,response): print("开始解析评价") shop_id = response.meta.get("shop_id") url = response.meta.get("url") title = response.meta.get("title") brand = response.meta.get("brand") brand_url = response.meta.get("brand_url") price = response.meta.get("price") comment_num = response.meta.get("comment_num") good_comment_rate = response.meta.get("good_comment_rate") good_comment = response.meta.get("good_comment") general_count = response.meta.get("general_count") poor_count = response.meta.get("poor_count") hot_comment_dict = response.meta.get("hot_comment_dict") default_comment_num = response.meta.get("default_comment_num") try: comment_json = json.loads(response.text) except: shop_info = { 'url': url, 'shop_id': shop_id, 'title': title, 'brand': brand, 'brand_url': brand_url, 'price': price, 'comment_num': comment_num, 'good_comment_rate': good_comment_rate, 'good_comment': good_comment, 'general_count': general_count, 'poor_count': poor_count, 'hot_comment_dict': hot_comment_dict, 'default_comment_num': default_comment_num, } yield scrapy.Request(response.url,meta=shop_info,headers=self.header,callback=self.parse_comment) else: comment_info = comment_json['comments'] for comment in comment_info: JDItem = JDAllItem() # 主键 评论ID comment_id = comment['id'] comment_context = comment['content'] comnent_time = comment['creationTime'] # 用户评分 comment_score = comment['score'] # 来源 comment_source = comment['userClientShow'] if comment_source == []: comment_source = "非手机端" # 型号 try: produce_size = comment['productSize'] except: produce_size = "None" # 颜色 try: produce_color = comment['productColor'] except: produce_color = "None" # 用户级别 user_level = comment['userLevelName'] try: append_comment = comment['afterUserComment']['hAfterUserComment']['content'] append_comment_time = comment['afterUserComment']['created'] except: append_comment = "无追加" append_comment_time = "None" # 用户京享值 user_exp = comment['userExpValue'] # 评价点赞数 comment_thumpup = comment['usefulVoteCount'] # 店铺回复 try: comment_reply = comment['replies'] except: comment_reply = [] if len(comment_reply) == 0: comment_reply_content = "Null" comment_reply_time = "Null" else: comment_reply_content = comment_reply[0]["content"] comment_reply_time = comment_reply[0]["creationTime"] JDItem["shop_id"] = shop_id JDItem["url"] = url JDItem["title"] = title JDItem["brand"] = brand JDItem["brand_url"] = brand_url JDItem["price"] = price JDItem["comment_num"] = comment_num JDItem["good_comment_rate"] = good_comment_rate JDItem["good_comment"] = good_comment JDItem["general_count"] = general_count JDItem["poor_count"] = poor_count JDItem["hot_comment_dict"] = hot_comment_dict JDItem["default_comment_num"] = default_comment_num JDItem["comment_id"] = comment_id JDItem["comment_context"] = comment_context JDItem["comnent_time"] = comnent_time JDItem["comment_score"] = comment_score JDItem["comment_source"] = comment_source JDItem["produce_size"] = produce_size JDItem["produce_color"] = produce_color JDItem["user_level"] = user_level JDItem["user_exp"] = user_exp JDItem["comment_thumpup"] = comment_thumpup JDItem["comment_reply_content"] = comment_reply_content JDItem["comment_reply_time"] = comment_reply_time JDItem["append_comment"] = append_comment JDItem["append_comment_time"] = append_comment_time print("yield评价") yield JDItem
Item
# Item定义 class JDAllItem(scrapy.Item): # 商品信息 shop_id = scrapy.Field() url = scrapy.Field() title = scrapy.Field() brand = scrapy.Field() brand_url = scrapy.Field() price = scrapy.Field() comment_num = scrapy.Field() good_comment_rate = scrapy.Field() good_comment = scrapy.Field() general_count = scrapy.Field() poor_count = scrapy.Field() hot_comment_dict = scrapy.Field() default_comment_num = scrapy.Field() # 主键 评论ID comment_id = scrapy.Field() comment_context = scrapy.Field() comnent_time = scrapy.Field() # 用户评分 comment_score = scrapy.Field() # 来源 comment_source = scrapy.Field() # 型号 produce_size = scrapy.Field() # 颜色 produce_color = scrapy.Field() # 用户级别 user_level = scrapy.Field() # 用户京享值 user_exp = scrapy.Field() # 评价点赞数 comment_thumpup = scrapy.Field() # 商家回复 comment_reply_content = scrapy.Field() comment_reply_time = scrapy.Field() append_comment = scrapy.Field() append_comment_time = scrapy.Field() def get_insert_sql(self): shop_id = self["shop_id"] url = self["url"] title = self["title"] brand = self["brand"] brand_url = self["brand_url"] price = self["price"] comment_num = self["comment_num"] good_comment_rate = self["good_comment_rate"] good_comment = self["good_comment"] general_count = self["general_count"] poor_count = self["poor_count"] hot_comment_dict = self["hot_comment_dict"] default_comment_num = self["default_comment_num"] comment_id = self["comment_id"] comment_context = self["comment_context"] comnent_time = self["comnent_time"] comment_score = self["comment_score"] comment_source = self["comment_source"] produce_size = self["produce_size"] produce_color = self["produce_color"] user_level = self["user_level"] user_exp = self["user_exp"] comment_thumpup = self["comment_thumpup"] comment_reply_content = self["comment_reply_content"] comment_reply_time = self["comment_reply_time"] append_comment = self["append_comment"] append_comment_time = self["append_comment_time"] insert_sql = """ insert into JDAll(shop_id,url,title,brand,brand_url,price,comment_num,good_comment_rate,good_comment,general_count,poor_count,hot_comment_dict,default_comment_num,comment_id,comment_context,comnent_time,comment_score,comment_source,produce_size,produce_color,user_level,user_exp,comment_thumpup,comment_reply_content,comment_reply_time,append_comment,append_comment_time) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) """ params = ( shop_id, url, title, brand, brand_url, price, comment_num, good_comment_rate, good_comment, general_count, poor_count, hot_comment_dict, default_comment_num, comment_id, comment_context, comnent_time, comment_score, comment_source, produce_size, produce_color, user_level, user_exp, comment_thumpup, comment_reply_content, comment_reply_time, append_comment, append_comment_time) print("return SQL 语句") return insert_sql, params
自定义pipelines异步存储数据到MySQL
class MysqlTwistedPipline(object): def __init__(self,dbpool): self.dbpool = dbpool @classmethod def from_settings(cls,settings): dbparms = dict( host=settings["MYSQL_HOST"], db=settings["MYSQL_DBNAME"], user=settings["MYSQL_USER"], passwd=settings["MYSQL_PASSWORD"], charset='utf8', cursorclass=MySQLdb.cursors.DictCursor, use_unicode=True, ) dbpool = adbapi.ConnectionPool("MySQLdb",**dbparms) return cls(dbpool) def process_item(self,item,spider): query = self.dbpool.runInteraction(self.do_insert,item) query.addErrback(self.handle_error,item,spider) def handle_error(self,failure,item,spider): print (failure) def do_insert(self,cursor,item): print("写入数据库") insert_sql,params = item.get_insert_sql() cursor.execute(insert_sql,params)
配置settings启用相关功能
SPIDER_MIDDLEWARES = { # 启用SplashDeduplicateArgsMiddleware中间件 'scrapy_splash.SplashDeduplicateArgsMiddleware': 100, } DOWNLOADER_MIDDLEWARES = { # splash 所用 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, } ITEM_PIPELINES = { #异步保存数据到mysql 'ArticleSpider.pipelines.MysqlTwistedPipline': 404, 'scrapy_redis.pipelines.RedisPipeline' : 300, } # 数据库配置 MYSQL_HOST = "xxx" MYSQL_DBNAME = "xxx" MYSQL_USER = "xxx" MYSQL_PASSWORD = "xxx" # redis配置 SCHEDULER = "scrapy_redis.scheduler.Scheduler" REDIS_URL = 'redis://192.168.1.241:6379' DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" REDIS_HOST = "192.168.1.241" REDIS_PORT = 6379 SCHEDULER_PERSIST = True REDIS_DB_INDEX = 1 # splash配置,此处使用的nginx反代多台splash SPLASH_URL = 'http://192.168.1.234'
main.py配置,用于启动函数
execute(["scrapy","crawl","jd_all","-s", "LOG_LEVEL=DEBUG", "-s", "JOBDIR=job_info/jd_all"])
数据库建表
# 本次存储采用已评价为基础存储商品信息 CREATE TABLE `JDAll` ( `shop_id` VARCHAR (16) NOT NULL, //商品ID `url` VARCHAR (255) DEFAULT NULL, //商品url `title` VARCHAR (1024) DEFAULT NULL, //商品标题 `brand` VARCHAR (255) DEFAULT NULL,//品牌 `brand_url` VARCHAR (1024) DEFAULT NULL,//店铺地址 `price` VARCHAR (16) DEFAULT NULL,//价格 `comment_num` INT (16) DEFAULT NULL,//评价总数 `good_comment_rate` VARCHAR (16) DEFAULT NULL,//好评率 `good_comment` VARCHAR (16) DEFAULT NULL,//好评数 `general_count` VARCHAR (16) DEFAULT NULL,//中评数 `poor_count` VARCHAR (16) DEFAULT NULL,//差评数 `hot_comment_dict` LONGTEXT,//热评信息 `default_comment_num` VARCHAR (16) DEFAULT NULL,//默认好评数 `comment_id` VARCHAR (32) NOT NULL,//评价ID,主键 `comment_context` LONGTEXT,//评价内容 `comnent_time` VARCHAR (255) DEFAULT NULL,//评价时间 `comment_score` VARCHAR (8) DEFAULT NULL,//评价星级 `comment_source` VARCHAR (255) DEFAULT NULL,//评价来源 `produce_size` VARCHAR (255) DEFAULT NULL,//商品大小 `produce_color` VARCHAR (255) DEFAULT NULL,//商品颜色 `user_level` VARCHAR (32) DEFAULT NULL,//用户会员级别 `user_exp` VARCHAR (32) DEFAULT NULL,//用户京享值 `comment_thumpup` VARCHAR (8) DEFAULT NULL,//评价点赞数 `comment_reply_content` LONGTEXT,//店家回复 `comment_reply_time` VARCHAR (255) DEFAULT NULL,//店铺回复时间 `append_comment` LONGTEXT,//买家追评 `append_comment_time` VARCHAR (255) DEFAULT NULL,//追评时间 PRIMARY KEY (`comment_id`) ) ENGINE = INNODB DEFAULT CHARSET = utf8
启动splash,需要自建splash
# 需要注意的是splash运行时间长会占用很高内存,可能会导致502 504错误,所以我本次爬取将splash分在了两台服务器(一台三个,一台两个),并且前面使用nginx进行反代,并定时重启docker容器 docker run -tid -p 8050:8050 scrapinghub/splash docker run -tid -p 8051:8050 scrapinghub/splash docker run -tid -p 8052:8050 scrapinghub/splash docker run -tid -p 8053:8050 scrapinghub/splash docker run -tid -p 8054:8050 scrapinghub/splash
启动爬虫:python main.py,启动后会定格此处,需要在redis上push对应的key
Redis上push 启动页的key

爬虫开始正常爬取
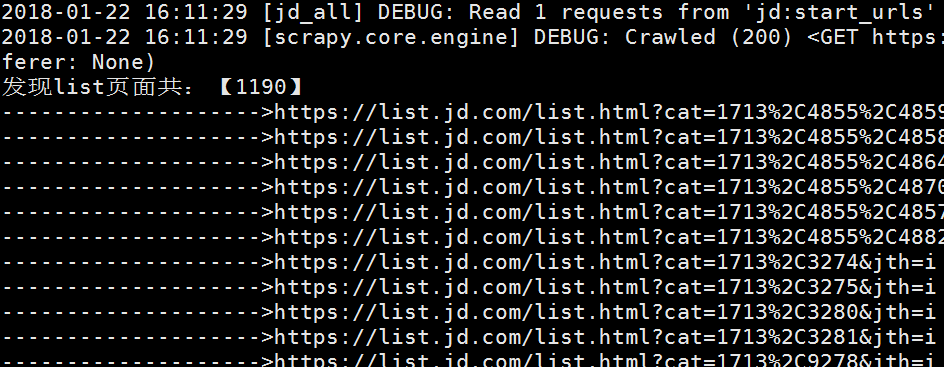
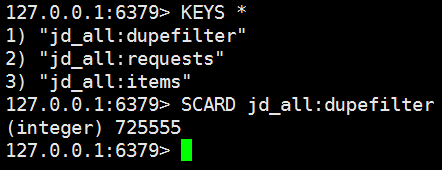
Redis去重队列、请求队列、item队列如下
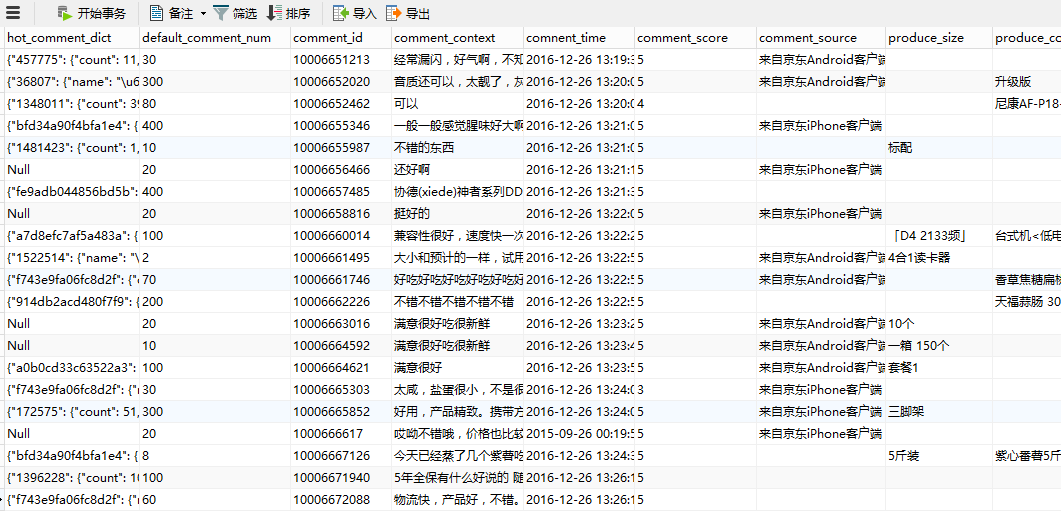
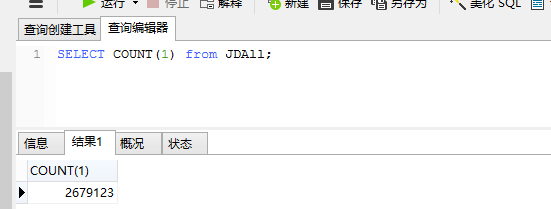
3、数据存储情况
我一共起了五个进程,爬了一个晚上。

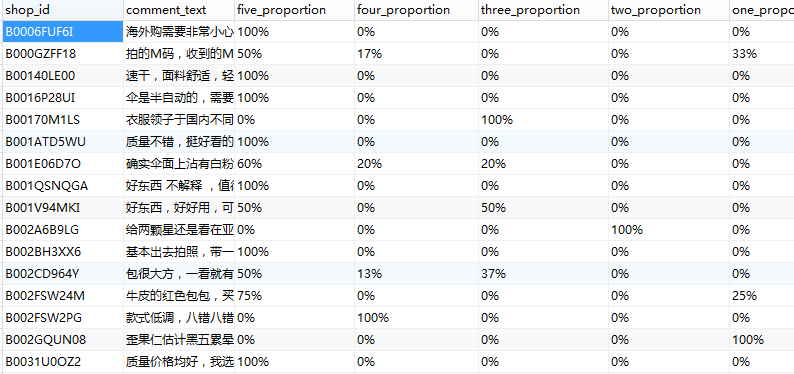
4、亚马逊爬取结果展示
商品信息

评价信息
ps:京东项目地址:https://github.com/dotbalo/ScrapySplash/tree/jd_all_next_rule
亚马逊项目地址:https://github.com/dotbalo/ScrapySplash/tree/amazon
阿里全球速卖通地址:https://github.com/dotbalo/ScrapySplash/tree/aliexpress
知乎、智联、伯乐在线、拉钩:https://github.com/dotbalo/ScrapySplash