最近在学习hadoop mapreduce编程的过程中遇到一个莫名奇妙的问题。最后通过调试时发现同时使用setCombinerClass(Reducer.class) 与 setReducerClass(Reducer.class)造成的。我个人觉得这两个不能同时使用,官方给出的WordCount例子中同时使用了这两个方法,我觉得是不严谨的,下面通过实验证明。
首先,我们来了解一下 setCombinerClass 的用法

如果同时使用这两个类会造成什么问题呢?会造成你reduce 输出的key value会当成map阶段的输出key value再次输入到reduce中进行处理。下面通过实验证明。首先官方WordCount中部分代码如下:
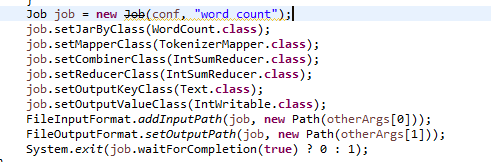
可以看到同时使用了
我们使用测试数据如下
Tom Lucy Tom Jack Jone Lucy Jone Jack Lucy Mary Lucy Ben Jack Alice Jack Jesse Terry Alice Terry Jesse Philip Terry Philip Alma Mark Terry Mark Alma
我们在reduce方法里添加一个调试信息,每次执行reduce都会输出相应的信息。

最后运行mapreduce程序。调试信息输出如下:
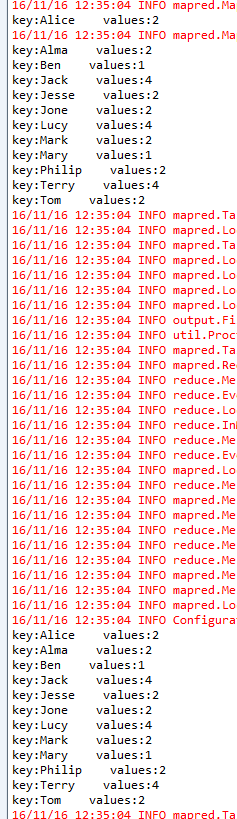
可以看见reduce执行了24次,而我们map阶段最后的key只有12个。
所以执行的流程为map(输出key--value)---->setCombinerClass(reduce)(输出key-value)---->reduce(key---value)
所以我们reduce执行了两次,第一次执行Combiner reduce的输入为map的输出,第二次执行reduece的输入为第一次执行Combiner reduce的输出。
由于这个例子刚好map的输出与Combiner reduce的输出一模一样,所以对结果没有影响,但如果这两个输出不一样,就会产生错误的结果。
所以setCombinerClass 与 setReducerClass同时只能使用一个。