1.堆排序
堆排序是用堆这种数据结构所设计的一种排序算法,近似一颗完成二叉树,同时具有一个特性,父节点的值大于(小于)子节点的值。
堆分两种,父节点比子节点大的叫最大堆,父节点比子节点小的叫最小堆
下面就是一个最大堆

2.堆排序步骤
以最大堆为例,假设有n个元素,
1)构造最大堆
2)交换根节点与第n个节点的值
3)将当前的堆调整为最大堆
4)n减一,继续2)3)步骤,直到n==1
3.如何构造最大堆
由最大堆的性质可知,每个父节点的值都比子节点的值大,所以要从下往上调整,调整后根节点就是最大的。举个例子
假设数组array : 
1)先把它想象成下面的形式(完全二叉树),在数组中还是按顺序排序的,
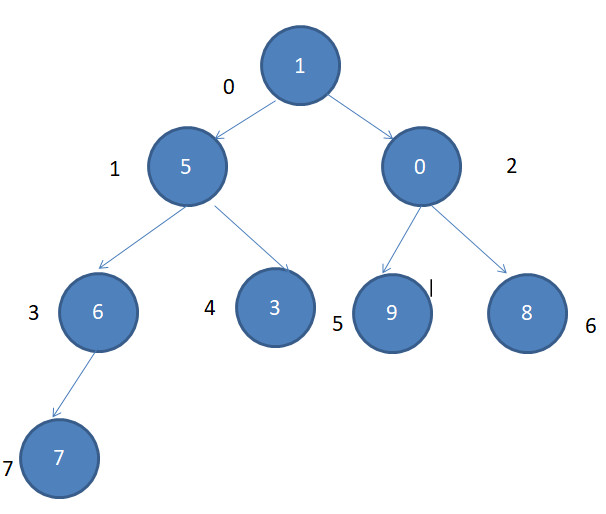
2)开始构造最大堆
1.先找到最后一个父节点,由于最大堆的形式是上面的形式,所以很容易得到最后一个父节点的下标,上面的元素是8个
那么最后父节点的下标:i=8/2-1=3,而且该节点的左子节点的下标是:2i+1,右子节点下标是:2i+2 这是很重要的性质。
比较i和2i+1,2i+2的对应值,如果这两个子节点比父节点大,那么就交换父子节点的值,要注意要判断2i+1和2i+2存不存在(即下标不能越界)
第一次调整后:
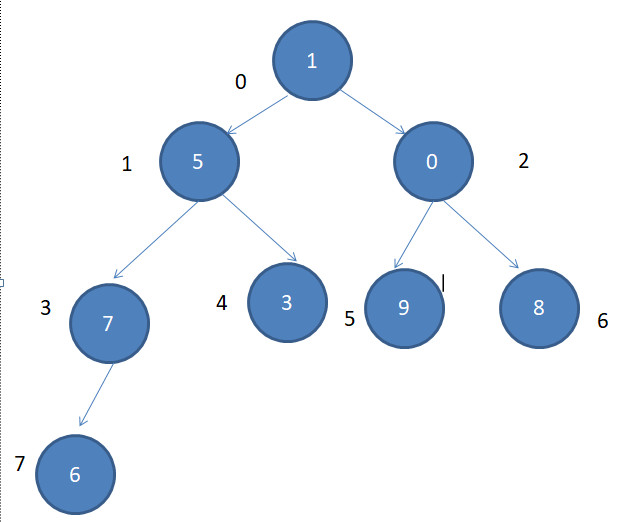
第二次:
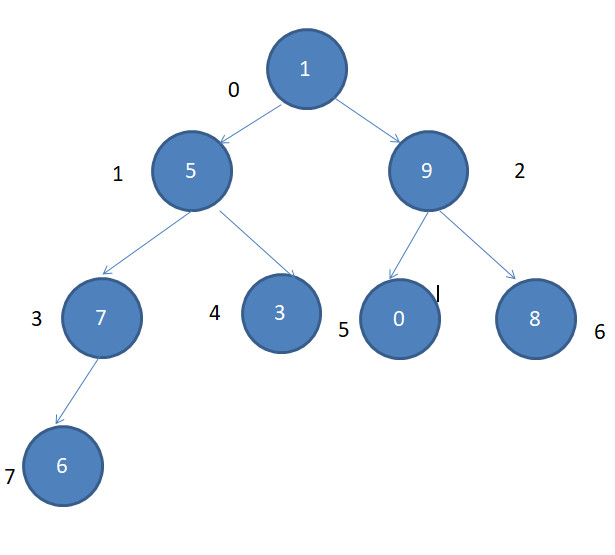
第三次
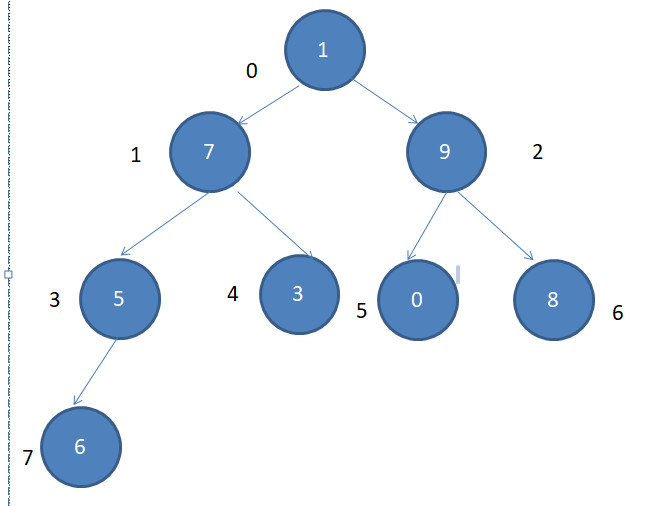
第四次

这时,要注意交换后可能导致后面的节点不满足最大堆的性质,此时继续按照上面的步骤来,其实就是一个递归,等下看代码就好理解了
第五次,调整完成

开始交换
3)交换根节点与第 n-i(i是已经交换的元素个数)个元素的值

4)然后把它调整成一个最大堆,此时要从上往下调整,即从根节点开始调整。

5) 继续 3),4)步骤,直到n-i==1,此时排序完成
结合代码过一遍就很容易懂了
代码如下:
1 #include<stdio.h> 2 //交换两个数的值 3 void swap(int *a,int * b) 4 { 5 int temp=*a; 6 *a=*b; 7 *b=temp; 8 } 9 //构造最大堆过程 10 void maxHead(int *arr,int start,int end) 11 { 12 int parentNode=start;//父节点 13 int childNode=parentNode*2+1;//左子节点 14 while(childNode<=end) 15 { 16 //childNode+1是右子节点 17 if(childNode+1<=end&&arr[childNode+1]>arr[childNode]) 18 childNode++;//右子节点大,取右子节点 19 //父节点比子节点大,不用交换,直接返回 20 if(arr[parentNode]>arr[childNode]) 21 return; 22 //否则,交换父节点与子节点的值 23 else 24 { 25 swap(&arr[parentNode],&arr[childNode]); 26 27 //交换后有可能导致后面的节点 28 //不满足最大堆的要求,所以继续对后面的节点进行构造 29 parentNode=childNode; 30 childNode=parentNode*2+1; 31 } 32 } 33 34 } 35 void headSort(int * arr,int num) 36 { 37 //num数组元素个数 38 int i; 39 //一开始先构造一个最大堆 40 for(i=num/2-1;i>=0;i--) 41 maxHead(arr,i,num-1); 42 43 for(i=num-1;i>0;i--) 44 { 45 swap(&arr[i],&arr[0]);//交换第一个元素与第i(i从后面开始)个元素 46 maxHead(arr,0,i-1);//交换后继续进行构造最大堆操作 47 } 48 } 49 int main() 50 { 51 int i; 52 int arr[8]={1,5,0,6,3,9,8,7}; 53 headSort(arr,8);//堆排序 54 for(i=0;i<8;i++) 55 printf("%d ",arr[i]); 56 return 0; 57 }
堆排序的平均时间复杂度是:O(nlogn)
有问题,随时联系