来自:https://blog.csdn.net/qq_38455201/article/details/80308771 十分详细,几张图片不显示,看这个地址
1.首先我们简单了解一下消息中间件的应用场景
异步处理
场景说明:用户注册后,需要发注册邮件和注册短信,传统的做法有两种1.串行的方式;2.并行的方式
(1)串行方式:将注册信息写入数据库后,发送注册邮件,再发送注册短信,以上三个任务全部完成后才返回给客户端。 这有一个问题是,邮件,短信并不是必须的,它只是一个通知,而这种做法让客户端等待没有必要等待的东西. 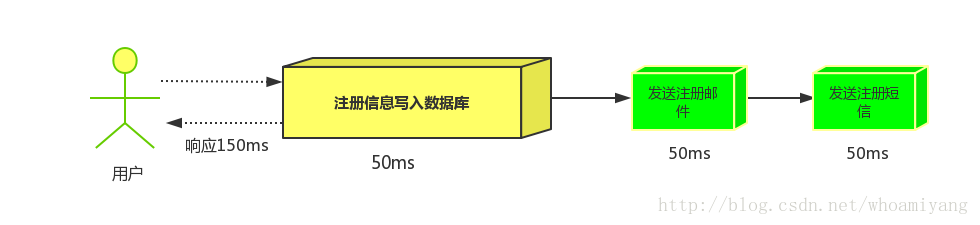
(2)并行方式:将注册信息写入数据库后,发送邮件的同时,发送短信,以上三个任务完成后,返回给客户端,并行的方式能提高处理的时间。 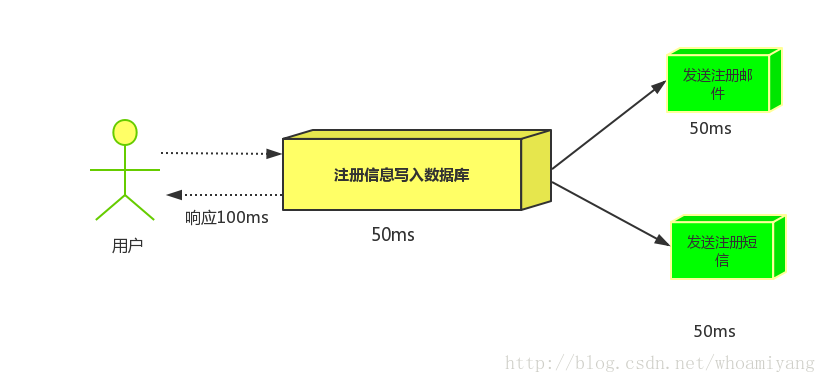
假设三个业务节点分别使用50ms,串行方式使用时间150ms,并行使用时间100ms。虽然并性已经提高的处理时间,但是,前面说过,邮件和短信对我正常的使用网站没有任何影响,客户端没有必要等着其发送完成才显示注册成功,英爱是写入数据库后就返回.
(3)消息队列
引入消息队列后,把发送邮件,短信不是必须的业务逻辑异步处理 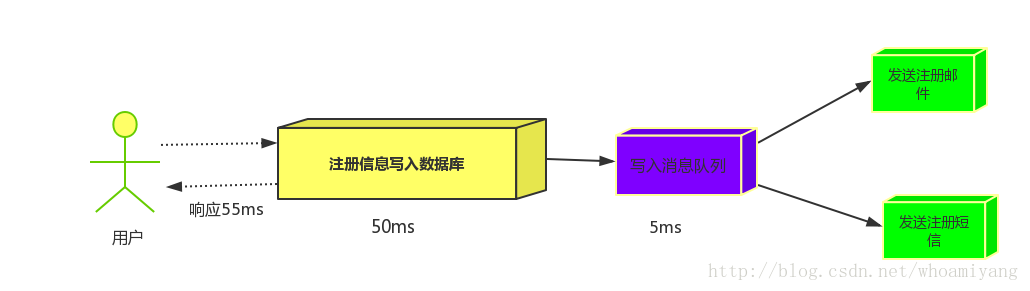
由此可以看出,引入消息队列后,用户的响应时间就等于写入数据库的时间+写入消息队列的时间(可以忽略不计),引入消息队列后处理后,响应时间是串行的3倍,是并行的2倍。
应用解耦
场景:双11是购物狂节,用户下单后,订单系统需要通知库存系统,传统的做法就是订单系统调用库存系统的接口. 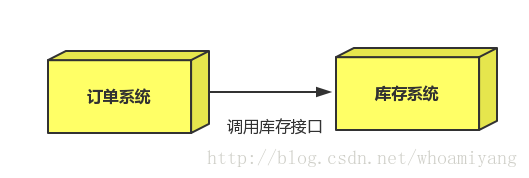
这种做法有一个缺点:
- 当库存系统出现故障时,订单就会失败。
订单系统和库存系统高耦合.
引入消息队列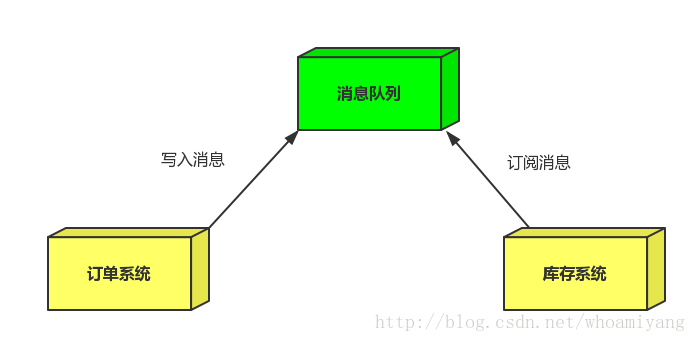
订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功。
- 库存系统:订阅下单的消息,获取下单消息,进行库操作。
就算库存系统出现故障,消息队列也能保证消息的可靠投递,不会导致消息丢失。
流量削峰
流量削峰一般在秒杀活动中应用广泛
场景:秒杀活动,一般会因为流量过大,导致应用挂掉,为了解决这个问题,一般在应用前端加入消息队列。
作用:
1.可以控制活动人数,超过此一定阀值的订单直接丢弃(我为什么秒杀一次都没有成功过呢^^)
2.可以缓解短时间的高流量压垮应用(应用程序按自己的最大处理能力获取订单) 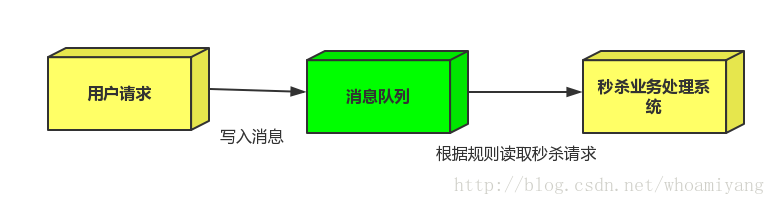
1.用户的请求,服务器收到之后,首先写入消息队列,加入消息队列长度超过最大值,则直接抛弃用户请求或跳转到错误页面.
2.秒杀业务根据消息队列中的请求信息,再做后续处理.
以上内容的来源是:https://blog.csdn.net/whoamiyang/article/details/54954780,在此感谢
2.各种消息中间件性能的比较:
TPS比较 一ZeroMq 最好,RabbitMq 次之, ActiveMq 最差。
持久化消息比较—zeroMq不支持,activeMq和rabbitMq都支持。持久化消息主要是指:MQ down或者MQ所在的服务器down了,消息不会丢失的机制。
可靠性、灵活的路由、集群、事务、高可用的队列、消息排序、问题追踪、可视化管理工具、插件系统、社区—RabbitMq最好,ActiveMq次之,ZeroMq最差。
高并发—从实现语言来看,RabbitMQ最高,原因是它的实现语言是天生具备高并发高可用的erlang语言。
综上所述:RabbitMQ的性能相对来说更好更全面,是消息中间件的首选。
3.接下来我们在springboot当中整合使用RabbitMQ
第一步:导入maven依赖
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-amqp</artifactId>
- <version>1.5.2.RELEASE</version>
- </dependency>
第二步:在application.properties文件当中引入RabbitMQ基本的配置信息
- #对于rabbitMQ的支持
- spring.rabbitmq.host=127.0.0.1
- spring.rabbitmq.port=5672
- spring.rabbitmq.username=guest
- spring.rabbitmq.password=guest
第三步:编写RabbitConfig类,类里面设置很多个EXCHANGE,QUEUE,ROUTINGKEY,是为了接下来的不同使用场景。
- /**
- Broker:它提供一种传输服务,它的角色就是维护一条从生产者到消费者的路线,保证数据能按照指定的方式进行传输,
- Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
- Queue:消息的载体,每个消息都会被投到一个或多个队列。
- Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来.
- Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
- vhost:虚拟主机,一个broker里可以有多个vhost,用作不同用户的权限分离。
- Producer:消息生产者,就是投递消息的程序.
- Consumer:消息消费者,就是接受消息的程序.
- Channel:消息通道,在客户端的每个连接里,可建立多个channel.
- */
- @Configuration
- public class RabbitConfig {
-
- private final Logger logger = LoggerFactory.getLogger(this.getClass());
-
- @Value("${spring.rabbitmq.host}")
- private String host;
-
- @Value("${spring.rabbitmq.port}")
- private int port;
-
- @Value("${spring.rabbitmq.username}")
- private String username;
-
- @Value("${spring.rabbitmq.password}")
- private String password;
-
-
- public static final String EXCHANGE_A = "my-mq-exchange_A";
- public static final String EXCHANGE_B = "my-mq-exchange_B";
- public static final String EXCHANGE_C = "my-mq-exchange_C";
-
-
- public static final String QUEUE_A = "QUEUE_A";
- public static final String QUEUE_B = "QUEUE_B";
- public static final String QUEUE_C = "QUEUE_C";
-
- public static final String ROUTINGKEY_A = "spring-boot-routingKey_A";
- public static final String ROUTINGKEY_B = "spring-boot-routingKey_B";
- public static final String ROUTINGKEY_C = "spring-boot-routingKey_C";
-
- @Bean
- public ConnectionFactory connectionFactory() {
- CachingConnectionFactory connectionFactory = new CachingConnectionFactory(host,port);
- connectionFactory.setUsername(username);
- connectionFactory.setPassword(password);
- connectionFactory.setVirtualHost("/");
- connectionFactory.setPublisherConfirms(true);
- return connectionFactory;
- }
-
- @Bean
- @Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
- //必须是prototype类型
- public RabbitTemplate rabbitTemplate() {
- RabbitTemplate template = new RabbitTemplate(connectionFactory());
- return template;
- }
- }
第四步:编写消息的生产者
- @Component
- public class MsgProducer implements RabbitTemplate.ConfirmCallback {
-
- private final Logger logger = LoggerFactory.getLogger(this.getClass());
-
- //由于rabbitTemplate的scope属性设置为ConfigurableBeanFactory.SCOPE_PROTOTYPE,所以不能自动注入
- private RabbitTemplate rabbitTemplate;
- /**
- * 构造方法注入rabbitTemplate
- */
- @Autowired
- public MsgProducer(RabbitTemplate rabbitTemplate) {
- this.rabbitTemplate = rabbitTemplate;
- rabbitTemplate.setConfirmCallback(this); //rabbitTemplate如果为单例的话,那回调就是最后设置的内容
- }
-
- public void sendMsg(String content) {
- CorrelationData correlationId = new CorrelationData(UUID.randomUUID().toString());
- //把消息放入ROUTINGKEY_A对应的队列当中去,对应的是队列A
- rabbitTemplate.convertAndSend(RabbitConfig.EXCHANGE_A, RabbitConfig.ROUTINGKEY_A, content, correlationId);
- }
- /**
- * 回调
- */
- @Override
- public void confirm(CorrelationData correlationData, boolean ack, String cause) {
- logger.info(" 回调id:" + correlationData);
- if (ack) {
- logger.info("消息成功消费");
- } else {
- logger.info("消息消费失败:" + cause);
- }
- }
- }
第五步:把交换机,队列,通过路由关键字进行绑定,写在RabbitConfig类当中
- /**
- * 针对消费者配置
- * 1. 设置交换机类型
- * 2. 将队列绑定到交换机
- FanoutExchange: 将消息分发到所有的绑定队列,无routingkey的概念
- HeadersExchange :通过添加属性key-value匹配
- DirectExchange:按照routingkey分发到指定队列
- TopicExchange:多关键字匹配
- */
- @Bean
- public DirectExchange defaultExchange() {
- return new DirectExchange(EXCHANGE_A);
- }
- /**
- * 获取队列A
- * @return
- */
- @Bean
- public Queue queueA() {
- return new Queue(QUEUE_A, true); //队列持久
- }
- @Bean
- public Binding binding() {
-
- return BindingBuilder.bind(queueA()).to(defaultExchange()).with(RabbitConfig.ROUTINGKEY_A);
- }
一个交换机可以绑定多个消息队列,也就是消息通过一个交换机,可以分发到不同的队列当中去。
- @Bean
- public Binding binding() {
- return BindingBuilder.bind(queueA()).to(defaultExchange()).with(RabbitConfig.ROUTINGKEY_A);
- }
- @Bean
- public Binding bindingB(){
- return BindingBuilder.bind(queueB()).to(defaultExchange()).with(RabbitConfig.ROUTINGKEY_B);
- }
第六步:编写消息的消费者,这一步也是最复杂的,因为可以编写出很多不同的需求出来,写法也有很多的不同。
比如一个生产者,一个消费者
- @Component
- @RabbitListener(queues = RabbitConfig.QUEUE_A)
- public class MsgReceiver {
-
- private final Logger logger = LoggerFactory.getLogger(this.getClass());
-
- @RabbitHandler
- public void process(String content) {
- logger.info("接收处理队列A当中的消息: " + content);
- }
-
- }

比如一个生产者,多个消费者,可以写多个消费者,并且他们的分发是负载均衡的。
- @Component
- @RabbitListener(queues = RabbitConfig.QUEUE_A)
- public class MsgReceiverC_one {
- private final Logger logger = LoggerFactory.getLogger(this.getClass());
-
- @RabbitHandler
- public void process(String content) {
- logger.info("处理器one接收处理队列A当中的消息: " + content);
- }
- }
- @Component
- @RabbitListener(queues = RabbitConfig.QUEUE_A)
- public class MsgReceiverC_two {
- private final Logger logger = LoggerFactory.getLogger(this.getClass());
- @RabbitHandler
- public void process(String content) {
- logger.info("处理器two接收处理队列A当中的消息: " + content);
- }
-
- }

另外一种消息处理机制的写法如下,在RabbitMQConfig类里面增加bean:
- @Bean
- public SimpleMessageListenerContainer messageContainer() {
- //加载处理消息A的队列
- SimpleMessageListenerContainer container = new SimpleMessageListenerContainer(connectionFactory());
- //设置接收多个队列里面的消息,这里设置接收队列A
- //假如想一个消费者处理多个队列里面的信息可以如下设置:
- //container.setQueues(queueA(),queueB(),queueC());
- container.setQueues(queueA());
- container.setExposeListenerChannel(true);
- //设置最大的并发的消费者数量
- container.setMaxConcurrentConsumers(10);
- //最小的并发消费者的数量
- container.setConcurrentConsumers(1);
- //设置确认模式手工确认
- container.setAcknowledgeMode(AcknowledgeMode.MANUAL);
- container.setMessageListener(new ChannelAwareMessageListener() {
- @Override
- public void onMessage(Message message, Channel channel) throws Exception {
- /**通过basic.qos方法设置prefetch_count=1,这样RabbitMQ就会使得每个Consumer在同一个时间点最多处理一个Message,
- 换句话说,在接收到该Consumer的ack前,它不会将新的Message分发给它 */
- channel.basicQos(1);
- byte[] body = message.getBody();
- logger.info("接收处理队列A当中的消息:" + new String(body));
- /**为了保证永远不会丢失消息,RabbitMQ支持消息应答机制。
- 当消费者接收到消息并完成任务后会往RabbitMQ服务器发送一条确认的命令,然后RabbitMQ才会将消息删除。*/
- channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
- }
- });
- return container;
- }
下面是当一个消费者,处理多个队列里面的信息打印的log

Fanout Exchange
Fanout 就是我们熟悉的广播模式,给Fanout交换机发送消息,绑定了这个交换机的所有队列都收到这个消息。
- //配置fanout_exchange
- @Bean
- FanoutExchange fanoutExchange() {
- return new FanoutExchange(RabbitConfig.FANOUT_EXCHANGE);
- }
-
- //把所有的队列都绑定到这个交换机上去
- @Bean
- Binding bindingExchangeA(Queue queueA,FanoutExchange fanoutExchange) {
- return BindingBuilder.bind(queueA).to(fanoutExchange);
- }
- @Bean
- Binding bindingExchangeB(Queue queueB, FanoutExchange fanoutExchange) {
- return BindingBuilder.bind(queueB).to(fanoutExchange);
- }
- @Bean
- Binding bindingExchangeC(Queue queueC, FanoutExchange fanoutExchange) {
- return BindingBuilder.bind(queueC).to(fanoutExchange);
- }
消息发送,这里不设置routing_key,因为设置了也无效,发送端的routing_key写任何字符都会被忽略。
- public void sendAll(String content) {
- rabbitTemplate.convertAndSend("fanoutExchange","", content);
- }
消息处理的结果如下所示:
