在进行数据分析之前,我们需要做的事情是对数据有初步的了解,比如对数据本身的敏感程度,通俗来说就是对数据的分布有大概的理解,此时我们需要工具进行数据的描述,观测数据的形状等;而后才是对数据进行建模分析,挖掘数据中隐藏的位置信息。怒气按在数据描述和简单分析方面做得比较好的是Pandas库。当然,它还需要结合Numpy。Scipy等科学计算相关库才能发挥功效。
Pandas数据结构
在进行Pandas相关介绍时,我们首先需要知道的是Pandas的两个数据结构(即对象)Series和DataFrame,这是Pandas的核心结构,掌握了此二者结构和属性要素,会在具体的数据处理过程中如虎添翼。
1)Series简介
Series是一种类似于一维数组的对象,它由两部分组成,第一部分是一维数据,另外一部分是与此一维数据对应的标签数据。但是语言描述不好理解,具体如下:
import pandas as pd #这是约定俗成的写法,一般而言,大家都会写pd,当然也可以换成别的 centerSeries=pd.Series(['中国科学院','文献情报中心','大楼','北四环西路']); print(centerSeries); #output: # 0 中国科学院 # 1 文献情报中心 # 2 大楼 # 3 北四环西路 # dtype: object
因为我们没有指定标签数据,而Python默认是通过数字排序进行标识,接下来给它添加标识数据。
import pandas as pd #这是约定俗成的写法,一般而言,大家都会写pd,当然也可以换成别的 centerSeries=pd.Series(['中国科学院','文献情报中心','大楼','北四环西路'],index=['a','b','c','d']); # index的size同Series必须一样大,否则报错 print(centerSeries); #output: # a 中国科学院 # b 文献情报中心 # c 大楼 # d 北四环西路 # dtype: object
对比之前的默认标识,我们可以看出它是由1,2,3,4变成了a,b,c,d。接下来将解释这样标识的意义。
import pandas as pd #这是约定俗成的写法,一般而言,大家都会写pd,当然也可以换成别的 centerSeries=pd.Series(['中国科学院','文献情报中心','大楼','北四环西路'],index=['a','b','c','d']); # index的size同Series必须一样大,否则报错 print(centerSeries[0])#通过一维数组进行获取数据 print(centerSeries[1]) print(centerSeries['c'])#通过标识index获取数据 print(centerSeries['d']) # output: # 中国科学院 # 文献情报中心 # 大楼 # 北四环西路
另外,我们可以看到通过一位数组格式获取数据和通过index标识获取数据都可以,这样的index就像曾经学过的数据库中的id列的作用,相当于建立了每个数据的索引。当然,针对Series的操作不只限于此,还有很多需要我们自己去通过“help”查看得到的。
2)DataFrame简介
DataFrame是一个表格型的数据结构,它包含有列和行索引,当然你也可以把它看做是由Series组织成的字典。需要说明的是,DataFrame的每一列中不需要数据类型相同,且它的数据是通过一个或者多个二维块进行存放,在了解DataFrame之前如果你对层次化索引有所了解,那么DataFrame可能相对容易理解,当然不知道也没有关系,举个简单的例子:它类似于常见的excel表格格式,可将它理解为一张excel表,至于DataFrame在内部具体如何处理,这个作为应用层的过程我们先不讨论。
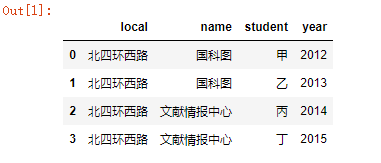
import pandas as pd # 简单的DataFrame制作 # 字典格式的数据 data={'name':['国科图','国科图','文献情报中心','文献情报中心'], 'year':['2012','2013','2014','2015'], 'local':['北四环西路','北四环西路','北四环西路','北四环西路'], 'student':['甲','乙','丙','丁']} centerDF=pd.DataFrame(data); centerDF #同样,默认的index是数字表示,而且它的列名也是按字母顺序排序的
运行结果:
当然我们可以调整列的格式,index仍采用默认:
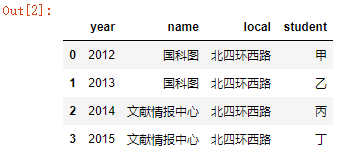
在pd.DataFrame()函数中明确指定参数columns
centerDF=pd.DataFrame(data,columns=['year','name','local','student']);
结果:
更改index的默认设置:
在pd.DataFrame()函数中明确指定参数index
centerDF=pd.DataFrame(data,columns=['year','name','local','student'],index=['a','b','c','d']);
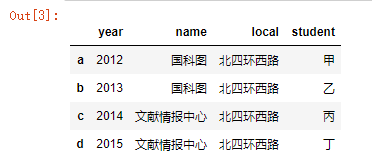
既然DataFrame是行列格式的数据,那么理所当然可以通过行、列的方式进行数据获取,按列进行数据获取:
import pandas as pd # 简单的DataFrame制作 # 字典格式的数据 data={'name':['国科图','国科图','文献情报中心','文献情报中心'], 'year':['2012','2013','2014','2015'], 'local':['北四环西路','北四环西路','北四环西路','北四环西路'], 'student':['甲','乙','丙','丁']} centerDF=pd.DataFrame(data,columns=['year','name','local','student'],index=['a','b','c','d']); print(centerDF['name']); print() print('列的类型:',type(centerDF['name'])) print(); print(centerDF['year']) # output: # a 国科图 # b 国科图 # c 文献情报中心 # d 文献情报中心 # Name: name, dtype: object # 列的类型: <class 'pandas.core.series.Series'> # a 2012 # b 2013 # c 2014 # d 2015 # Name: year, dtype: object
另外,可以看出按列进行获取时它们的index表示是相同的,且每一列是一个Series对象。
按行进行数据获取,其实是通过index进行操作。
import pandas as pd # 简单的DataFrame制作 # 字典格式的数据 data={'name':['国科图','国科图','文献情报中心','文献情报中心'], 'year':['2012','2013','2014','2015'], 'local':['北四环西路','北四环西路','北四环西路','北四环西路'], 'student':['甲','乙','丙','丁']} centerDF=pd.DataFrame(data,columns=['year','name','local','student'],index=['a','b','c','d']); print(centerDF.loc['a']); print() print('行的类型:',type(centerDF.loc['a'])) # output: #year 2012 # name 国科图 # local 北四环西路 # student 甲 # Name: a, dtype: object # 行的类型: <class 'pandas.core.series.Series'>
其中‘loc’,也可用‘iloc’,不推荐使用‘ix’,因为其已经被弃用。
可以看出,每一行是一个Series对象,此时该Series的index其实就是DataFrame的列名称,综上来看,对于一个DataFrame来说,它是纵横双向进行索引,只是每个Series(纵横)都共用一个索引而已。
3)利用Pandas加载、保存数据
在进行数据处理时我们首要的工作是把数据加载到内存中,这一度成为程序编辑的软肋,但是Pandas包所提供的功能几乎涵盖了大多数的数据处理的加载问题,如read_csv、read_ExcelFile等。
1.加载、保存csv格式的数据
原文件:
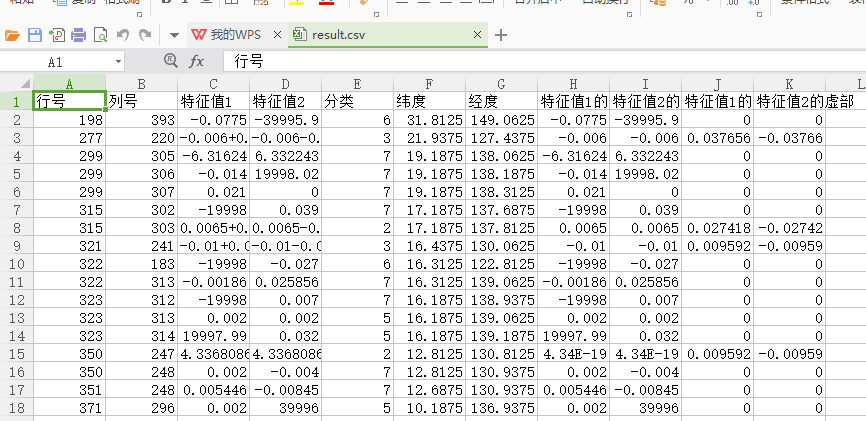
代码:
#! /usr/bin/env python #coding=utf-8 #加载csv格式的数据 data_csv=pd.read_csv(r'C:Users123Desktop esult.csv');#它的默认属性有sep=',' data_csv
运行结果:
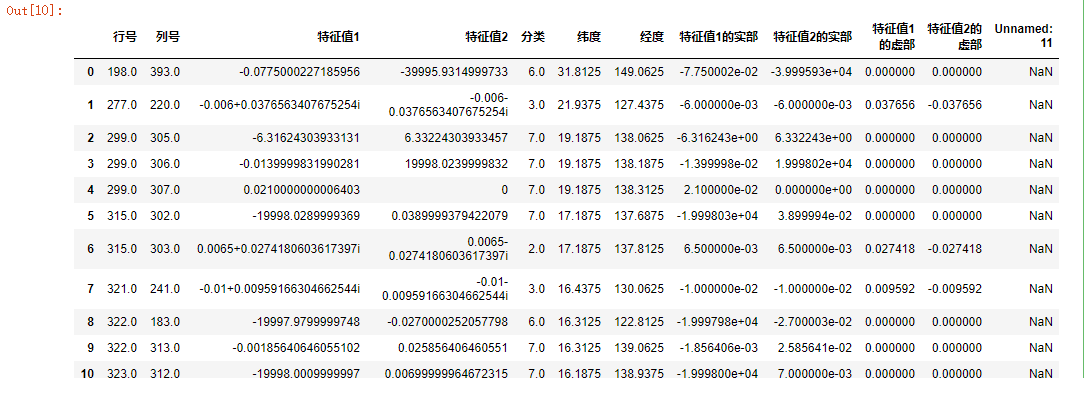
更改默认属性
data_csv=pd.read_csv(r'C:Users123Desktop esult.csv',sep='#');#更改默认属性有sep='#' data_csv
运行结果:
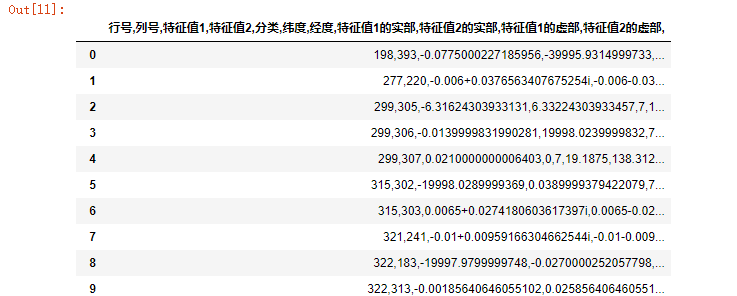
不要表头:
data_csv=pd.read_csv(r'C:Users123Desktop esult.csv',header=None,skiprows=[0]);#不要表头Header data_csv
结果:
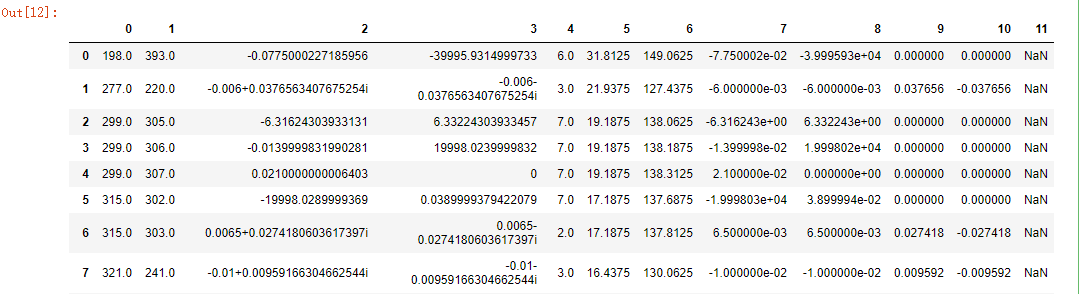
自行添加表头列:
#! /usr/bin/env python #coding=utf-8 #加载csv格式的数据 data_csv=pd.read_csv(r'C:Users123Desktop esult.csv',header=None,skiprows=[0]);#不要表头Header print(type(data_csv))#通过它的类型我们可以看到它是DataFrame #可自行添加表头列 data_csv.columns=['第一列','第二列','第三列','第四列','第五列','第六列','第七列','第八列','第十列','第十一列','第十二列','第十三列']; data_csv
运行结果:
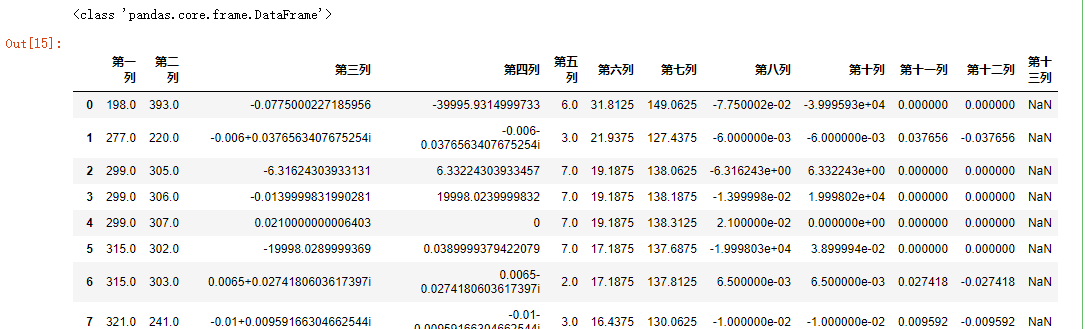
保存csv数据:
#! /usr/bin/env python #coding=utf-8 #加载csv格式的数据 data_csv=pd.read_csv(r'C:Users123Desktop esult.csv',header=None,skiprows=[0]);#不要表头Header print(type(data_csv))#通过它的类型我们可以看到它是DataFrame #可自行添加表头列 data_csv.columns=['第一列','第二列','第三列','第四列','第五列','第六列','第七列','第八列','第十列','第十一列','第十二列','第十三列']; data_csv.loc[0,'第一列']='新添加内容'; data_csv.to_csv(r'C:Users123Desktop esult2.csv'); data_csv
运行结果:
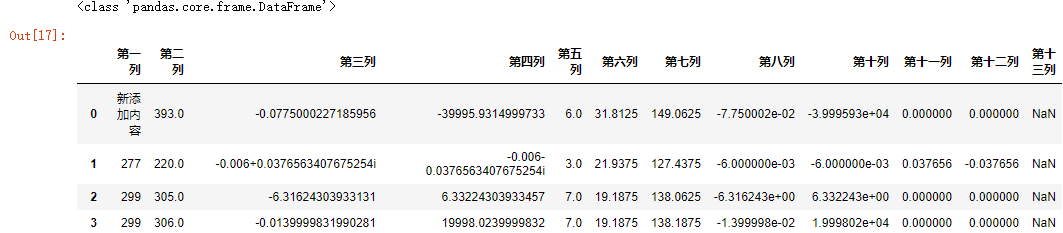
生成新文件:
综上所述,通过对csv格式的文件进行读取,我们可以指定读入的格式(sep=','),也可以指定它的header为空None,最后添加column,而之所以可以后来添加的原因是读入的csv已经是DataFrame对象了。
2.加载、保存excel格式的数据
# 读取excel文件 data_excel=pd.read_excel(r'result.xlsx',encoding='utf-8',sheetname='Sheet1'); #保存数据 data_excel.to_excel(r'result2.xlsx',sheet_name='Sheet1');
对于excel文件来说,同csv格式的处理相差无几,但是excel文件在处理时需要指定sheetname属性(读取和写入sheet_name)。
3.加载、保存json格式的数据
将json的数据格式也在此说明是因为json数据通常是系统之间数据交互的定制化xml格式的数据,现在它已经成为web系统进行数据交互的默认标准。
import json #源数据(真实的json格式的数据多数是通过http传输过来的) obj={'school':'UCAS','institute':'NSLCAS','name':['tovi','karen','jack']}; # 读取json obj_json=json.dumps(obj) data_json=json.loads(obj_json) print(data_json) print(type(data_json)) # output: # {'school': 'UCAS', 'institute': 'NSLCAS', 'name': ['tovi', 'karen', 'jack']} # <class 'dict'>
我们可以看到读入的json数据被转换成了字典。
关于json数据的保存,实际来说只是在数据交换处理中的一种格式,真正的保存没有实际意义,因为真实的场景是进行数据交换,处理完的json数据会做后续的处理。
利用Pandas处理数据
一、汇总计算
当我们知道如何加载数据后,接下来就是如何处理数据,虽然之前的赋值计算也是一种计算,但是如果Pandas的作用就停留在此,那我们也许只是看到了它的冰山一角,它首先比较吸引人的作用是汇总计算。
1)基本的数学统计计算
这里的基本计算指的是sum、mean等操作,主要是基于Series(也可能是来自DataFrame)进行统计计算。
代码1:
#统计计算sum、mean等 import numpy as np import pandas as pd df=pd.DataFrame(np.arange(16).reshape((4,4)),columns=['aa','bb','cc','dd'],index=['a','b','c','d']) print(df) # output: # aa bb cc dd # a 0 1 2 3 # b 4 5 6 7 # c 8 9 10 11 # d 12 13 14 15
代码2:
df_data=df.reindex(['a','b','c','d','e']); df_data #数据中既有正常值,也有NaN值
结果:
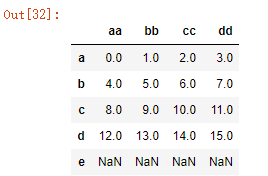
代码3:
df_data.sum()#默认是通过列进行求和,即axis=0;默认NaN值也是忽略的
结果:
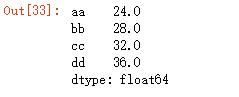
代码4:
df_data.sum(axis=1)#改为通过行进行求和
结果:
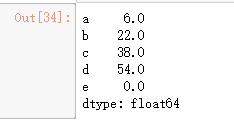
代码5:
df_data.mean()#NaN值默认忽略
同样的sum()函数也是NaN值默认忽略。
结果:
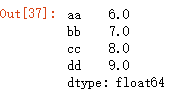
代码6:
df_data.mean(axis=0,skipna=False) #对于NaN不跳过
结果:

代码7:
#idxmax idxmin最大值、最小值的索引 print(df.idxmax()) print(df.idxmin()) # output: # aa d # bb d # cc d # dd d # dtype: object # aa a # bb a # cc a # dd a # dtype: object
代码8:
#进行累计cumsum print(df.cumsum())
代码9:
#对于刚才提到的大多数描述性统计可以使用describe df_data.describe()
结果:
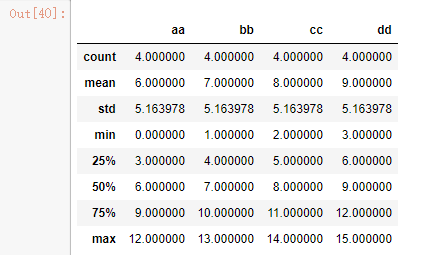
代码10:
#对于这些统计量的含义可以查找“help”得到,此处不再赘述 help()
2)唯一值、值的计数、成员资格的设定
采用几行代码、一个output进行演示:
import pandas as pd #是否是唯一值 obj=pd.Series(['a','a','b','b','b','c','c']) print(obj) # output: # 0 a # 1 a # 2 b # 3 b # 4 b # 5 c # 6 c # dtype: object print(obj.unique()) # output: # ['a' 'b' 'c'] # value_counts是Python针对Series进行的顶级操作 print(pd.value_counts(obj.values,sort=False)) # output: # a 2 # b 3 # c 2 # dtype: int64 mark=obj.isin(['a'])#是否存在a print(mark) # output: # 0 True # 1 True # 2 False # 3 False # 4 False # 5 False # 6 False # dtype: bool obj[mark]#根据判定条件进行数据获取 # output: # 0 a # 1 a # dtype: object
另外,实际应用中不只是这些统计函数在发挥作用,还有很多统计函数,比如计算数值之间的百分比变化(pct_change),或者是相关数据的系数与协方差等,这里就不做讨论了,需要时可查看帮助文档来解决。
二、缺失值处理
1)缺失值概念
缺失值(missing data)是在数据处理中在所难免的问题,Pandas对缺失值的处理目的是简化对缺失值处理的工作。缺失值在Pandas中使用的是浮点数(numpy.nan:Not a Number)。
代码1:
data=pd.Series([11,22,33,np.nan,55]);#定义NaN值通过numpy.nan data # output: # 0 11.0 # 1 22.0 # 2 33.0 # 3 NaN # 4 55.0 # dtype: float64
代码2:
data.isnull()#判定是否为空NaN # output: # 0 False # 1 False # 2 False # 3 True # 4 False # dtype: bool
代码3:
#Python 中对于None也认为是NaN data[2]=None; data # output: # 0 11.0 # 1 22.0 # 2 NaN # 3 NaN # 4 55.0 # dtype: float64
2)过滤缺失值
对于缺失值的过滤主要通过dropna进行。
代码1:
data.dropna()#过滤掉NaN值 # output: # 0 11.0 # 1 22.0 # 4 55.0 # dtype: float64
代码2:
#当然drop太过暴力——它会过滤点所有的NaN值,这样往往不是一般正常需要的处理结果 #我们可以通过dropna的属性进行限定 df=pd.DataFrame(np.arange(16).reshape(4,4),columns=['aa','bb','cc','dd'],index=['a','b','c','d']) #制造NaN值 df.loc[:1,:]=np.nan print(df) # output: # aa bb cc dd # a NaN NaN NaN NaN # b 4.0 5.0 6.0 7.0 # c 8.0 9.0 10.0 11.0 # d 12.0 13.0 14.0 15.0 print(df.dropna(axis=1,how='all'))#0行1列 # 并没有什么变化,因为过滤的是列,要求一列全都是NaN值 # output: # aa bb cc dd # a NaN NaN NaN NaN # b 4.0 5.0 6.0 7.0 # c 8.0 9.0 10.0 11.0 # d 12.0 13.0 14.0 15.0 print(df.dropna(axis=0,how='all'))#0行1列 # output: # aa bb cc dd # b 4.0 5.0 6.0 7.0 # c 8.0 9.0 10.0 11.0 # d 12.0 13.0 14.0 15.0
3)填充缺失值
因为数据处理的要求,可能并不需要将所有数据进行过滤,此时需要对数据进行必要的填充(比如0.0);还可以用线性插值进行必要的填充,而这个在数据处理中经常需要用到的方式如下:
df=pd.DataFrame(np.arange(16).reshape(4,4),columns=['aa','bb','cc','dd'],index=['a','b','c','d']) #制造NaN值 df.loc[:1,:]=np.nan print(df) # output: # aa bb cc dd # a NaN NaN NaN NaN # b 4.0 5.0 6.0 7.0 # c 8.0 9.0 10.0 11.0 # d 12.0 13.0 14.0 15.0 print(df.fillna(0.0))#fillna默认会返回新的对象 #也可以像dropna操作一样进行必要的限定而不是所有的值都进行填充 # print(df.fillna({1:0.5,2:5.5}))#测试失败 #当需要在旧的对象上进行更改,而不是经过过滤返回一个新的对象时 df.fillna(0.5,inplace=True) print(df) # output: # aa bb cc dd # a 0.5 0.5 0.5 0.5 # b 4.0 5.0 6.0 7.0 # c 8.0 9.0 10.0 11.0 # d 12.0 13.0 14.0 15.0 #可以选择一些线性插值进行填充 df.loc[:1,:]=np.nan #后向寻值填充 print(df.fillna(method='bfill')) # output: # aa bb cc dd # a 4.0 5.0 6.0 7.0 # b 4.0 5.0 6.0 7.0 # c 8.0 9.0 10.0 11.0 # d 12.0 13.0 14.0 15.0 print(df.fillna(df.mean()))#使用平均值进行填充 # output: # aa bb cc dd # a 8.0 9.0 10.0 11.0 # b 4.0 5.0 6.0 7.0 # c 8.0 9.0 10.0 11.0 # d 12.0 13.0 14.0 15.0
另外,在处理缺失值时除了以上介绍的简单操作之外,更多的时候需要根据数据挖掘需求或者程序运行方面灵活地进行缺失值处理,程序是认为设定的规则,但针对这些规则进行优化组合将会带来新的效果。
参考书目:《数据馆员的Python简明手册》