自从6月份出山以来 就一直琢磨着搞一套通用的服务化平台。在设计用户行为分析以及用户推广的时候,发现自己的构架里对海量文件的存储没有一个合理的方案。起初打算用windows2003中dfs系统开发一套新的文件系统,后来发现win下的dfs是个大坑,未遂。然后考虑到win平台与linux系统之间关于文件处理的优劣与稳定性,最终选择linux下fastdfs。
下面先简单介绍下分布式文件系统然后结合我的实际case给大家图文演示,在这之前先感谢下fishman、咕咚、以及菲雪同学的大力支持。你们是最棒的!!
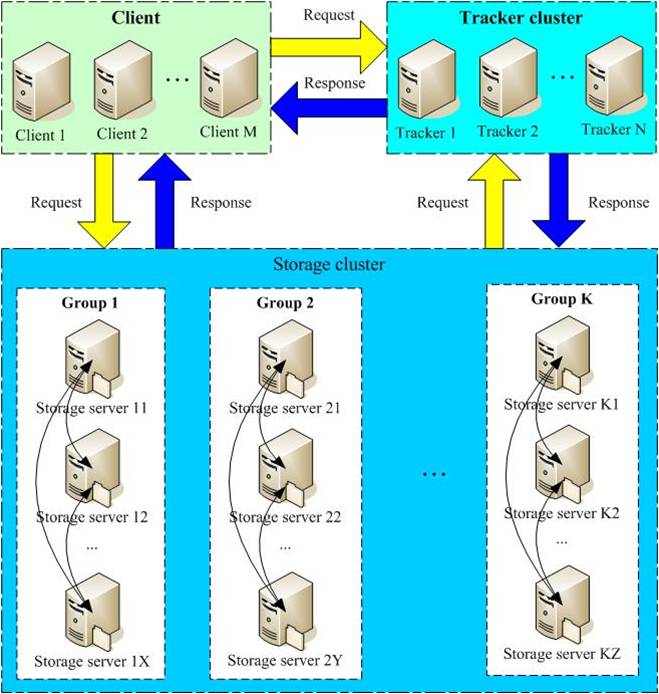
Tracker Server:跟踪服务器,主要做调度工作,在访问上起负载均衡的作用。在内存中记录集群中group和storage server的状态信息,是连接Client和Storage server的枢纽。
Storage Server:存储服务器,文件和文件属性(meta data)都保存到存储服务器上
架构解读:
只有两个角色,tracker server和storage server,不需要存储文件索引信息
所有服务器都是对等的,不存在Master-Slave关系
存储服务器采用分组方式,同组内存储服务器上的文件完全相同(RAID 1)
不同组的storage server之间不会相互通信
由storage server主动向tracker server报告状态信息,tracker server之间通常不会相互通信
上传文件流程图:
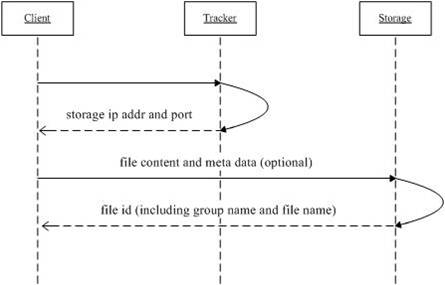
1.client询问tracker上传到的storage;
2.tracker返回一台可用的storage;
3.client直接和storage通信完成文件上传,storage返回文件ID
下载文件流程图:

1. client询问tracker可以下载指定文件的storage,参数为文件ID(组名和文件名);
2. tracker返回一台可用的storage;
3. client直接和storage通信完成文件下载。
同步机制:
采用binlog文件记录文件上传、删除等操作,根据binlog进行文件同步
binlog中只记录文件名,不记录文件内容
记录已同步的位置到.mark文件中
同组内的storage server之间是对等的,文件上传、删除等操作可以在任意一台storage server上进行
文件同步只在同组内的storage server之间进行,采用push方式,即源头服务器同步给目标服务器
同步延迟问题:
storage生成的文件名中,包含源头storage IP地址和文件创建时间戳
源头storage定时向tracker报告同步情况,包括向目标服务器同步到的文件时间戳
tracker收到storage的同步报告后,找出该组内每台storage被同步到的时间戳(取最小值),作为storage属性保存到内存中
通信协议:
二进制通信协议
协议包由两部分组成:header和body
header共10字节,格式如下:
8 bytes body length
1 byte command
1 byte status
body数据包格式由取决于具体的命令, body可以为空
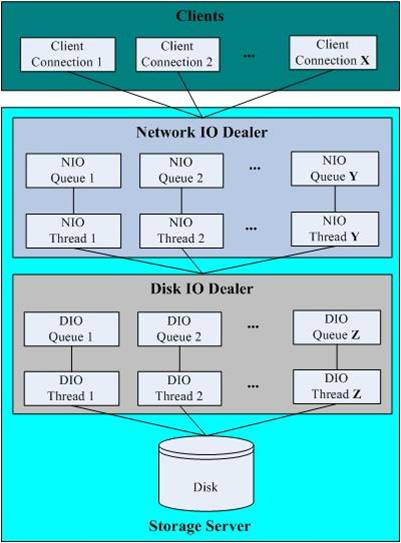
IO模型: