一、总运行流程
当你发出请求后,hystrix是这么运行的
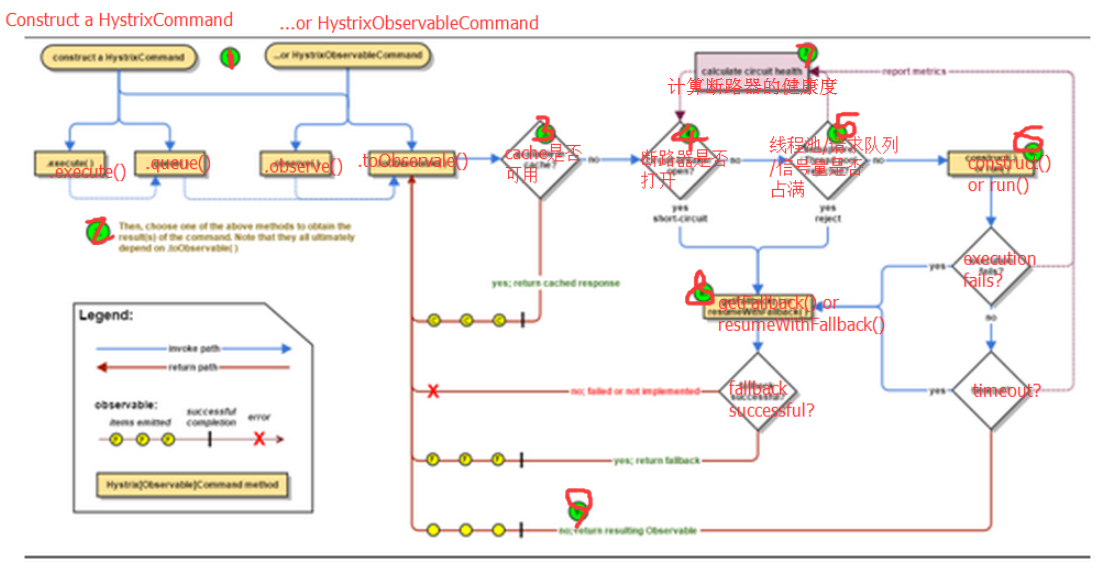
红圈 :Hystrix 命令执行失败,执行回退逻辑。也就是大家经常在文章中看到的“服务降级”。
绿圈 :四种情况会触发失败回退逻辑( fallback )。
第一种 :short-circuit ,处理链路处于熔断的回退逻辑,在 「3. #handleShortCircuitViaFallback()」 详细解析。
第二种 :semaphore-rejection ,处理信号量获得失败的回退逻辑,在 「4. #handleShortCircuitViaFallback()」 详细解析。
第三种 :thread-pool-rejection ,处理线程池提交任务拒绝的回退逻辑,在 「5. #handleThreadPoolRejectionViaFallback()」 详细解析。
第四种 :execution-timeout ,处理命令执行超时的回退逻辑,在 「6. #handleTimeoutViaFallback()」 详细解析。
第五种 :execution-failure ,处理命令执行异常的回退逻辑,在 「7. #handleFailureViaFallback()」 详细解析。
第六种 :bad-request ,TODO 【2014】【HystrixBadRequestException】,和 hystrix-javanica 子项目相关。
另外,#handleXXXX() 方法,整体代码比较类似,最终都是调用 #getFallbackOrThrowException() 方法,获得【回退逻辑 Observable】或者【异常 Observable】,在 「8. #getFallbackOrThrowException(…)」 详细解析。

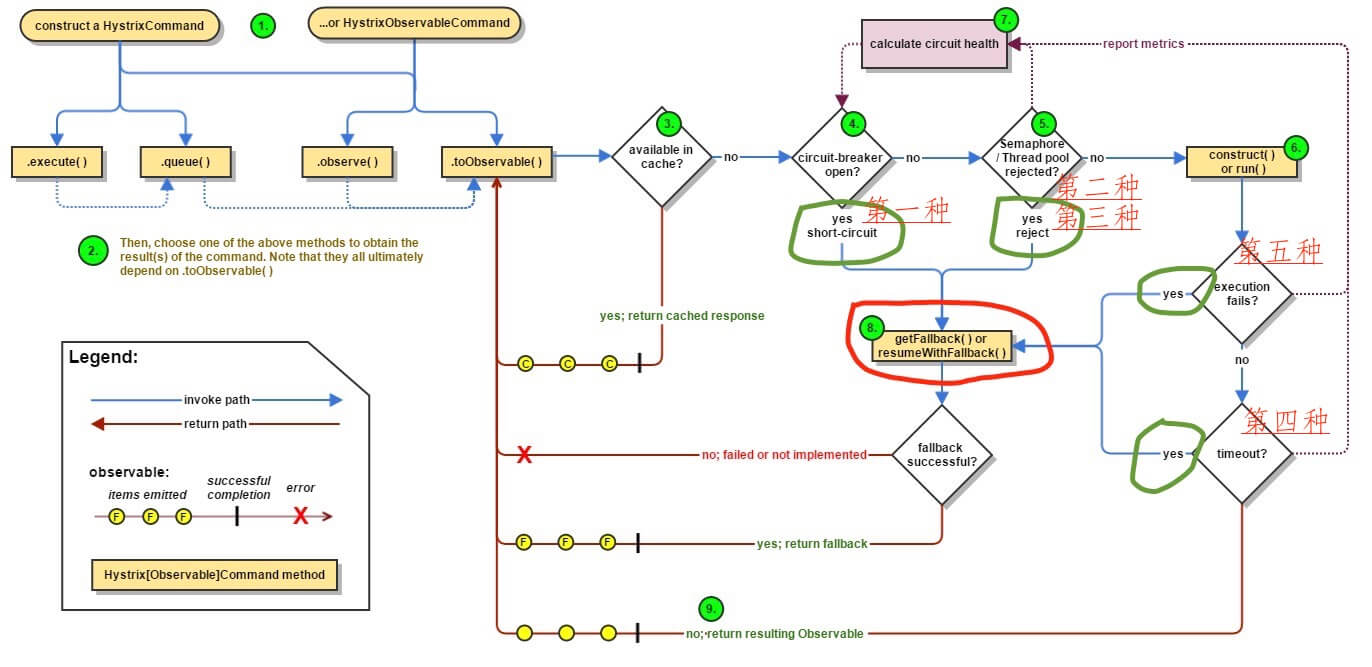
详细解释个步骤
1.创建 HystrixCommand or HystrixObservableCommand Object
用于返回单一的响应
HystrixObservableCommand
用于返回多个可自定义的响应
命令模式,将来自客户端的请求封装成一个对象,从而让你可以使用不同的请求对客户端进行参数化。它可以被用于实现“行为请求者"与”行为实现者“的解耦,以便使两者可以适应变化。
这一过程也包含了策略、资源的初始化,参看AbstractCommand的构造函数:
protected AbstractCommand(...) { // 初始化group,group主要是用来对不同的command key进行统一管理,比如统一监控、告警等 this.commandGroup = initGroupKey(...); // 初始化command key,用来标识降级逻辑,可以理解成command的id this.commandKey = initCommandKey(...); // 初始化自定义的降级策略 this.properties = initCommandProperties(...); // 初始化线程池key,相同的线程池key将共用线程池 this.threadPoolKey = initThreadPoolKey(...); // 初始化监控器 this.metrics = initMetrics(...); // 初始化断路器 this.circuitBreaker = initCircuitBreaker(...); // 初始化线程池 this.threadPool = initThreadPool(...); // Hystrix通过SPI实现了插件机制,允许用户对事件通知、处理和策略进行自定义 this.eventNotifier = HystrixPlugins.getInstance().getEventNotifier(); this.concurrencyStrategy = HystrixPlugins.getInstance().getConcurrencyStrategy(); HystrixMetricsPublisherFactory.createOrRetrievePublisherForCommand(this.commandKey, this.commandGroup, this.metrics, this.circuitBreaker, this.properties); this.executionHook = initExecutionHook(executionHook); this.requestCache = HystrixRequestCache.getInstance(this.commandKey, this.concurrencyStrategy); this.currentRequestLog = initRequestLog(this.properties.requestLogEnabled().get(), this.concurrencyStrategy); /* fallback semaphore override if applicable */ this.fallbackSemaphoreOverride = fallbackSemaphore; /* execution semaphore override if applicable */ this.executionSemaphoreOverride = executionSemaphore; }
其实构造函数中的很多初始化工作只会集中在创建第一个Command时来做,后续创建的Command对象主要是从静态Map中取对应的实例来赋值,比如监控器、断路器和线程池的初始化,因为相同的Command的command key和线程池key都是一致的,在HystrixCommandMetrics、HystrixCircuitBreaker.Factory、HystrixThreadPool中会分别有如下静态属性:
private static final ConcurrentHashMap<String, HystrixCommandMetrics> metrics = new ConcurrentHashMap<String, HystrixCommandMetrics>(); private static ConcurrentHashMap<String, HystrixCircuitBreaker> circuitBreakersByCommand = new ConcurrentHashMap<String, HystrixCircuitBreaker>(); final static ConcurrentHashMap<String, HystrixThreadPool> threadPools = new ConcurrentHashMap<String, HystrixThreadPool>();
可见所有Command对象都可以在这里找到自己对应的资源实例。
2. Execute the Command(命令执行)
对于HystrixCommand有4个执行方法
对于HystrixObservableCommand只有后两个
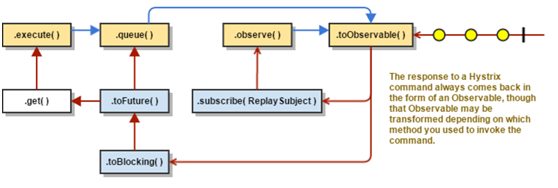
//同步阻塞方法,其实就是调用了queue().get() execute() — blocks, then returns the single response received from the dependency (or throws an exception in case of an error) //异步非阻塞方法,直接返回Future,可以先做自己的事情,做完再.get() queue() — returns a Future with which you can obtain the single response from the dependency //热观察,可以被立即执行,如果订阅了那么会重新通知,其实就是调用了toObservable()并内置ReplaySubject,详细可以参考RxJava observe() — subscribes to the Observable that represents the response(s) from the dependency and returns an Observable that replicates that source Observable //冷观察,返回一个Observable对象,当调用此接口,还需要自己加入订阅者,才能接受到信息,详细可以参考RxJava toObservable() — returns an Observable that, when you subscribe to it, will execute the Hystrix command and emit its responses 注:由于Hystrix底层采用了RxJava框架开发,所以没接触过的可能会一脸懵逼,需要再去对RxJava有所了解。
工作流程的源码说明:
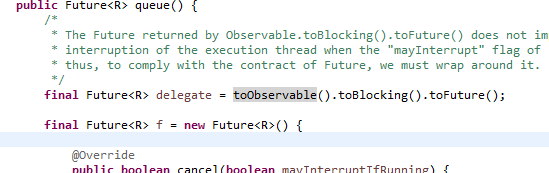
工作流程图中的第1,2步:HystrixCommand.java的execute()是入口,调用的是queue():
public R execute() { try { return queue().get(); } catch (Exception e) { throw Exceptions.sneakyThrow(decomposeException(e)); } }
在queue()中调用了toObservable()的方法,接着看源码:
3. Is the Response Cached?(结果是否被缓存)
判断是否使用缓存:是否实现了getCacheKey() 的方法
如果使用缓存,再判断如果请求缓存可用fromCache != null,并且对于该请求的响应也在缓存中,那么命中的响应会以Observable直接返回。
工作流程的源码说明:
工作流程图中的第3步:AbstractCommand.java的toObservable()方法中的片段:
//.... final boolean requestCacheEnabled = isRequestCachingEnabled(); final String cacheKey = getCacheKey(); /* try from cache first */ if (requestCacheEnabled) { HystrixCommandResponseFromCache<R> fromCache = (HystrixCommandResponseFromCache<R>) requestCache.get(cacheKey); if (fromCache != null) { isResponseFromCache = true; return handleRequestCacheHitAndEmitValues(fromCache, _cmd); } } //....
protected boolean isRequestCachingEnabled() {
return properties.requestCacheEnabled().get() && getCacheKey() != null;
}
下图关于是请求缓存的整个生命周期

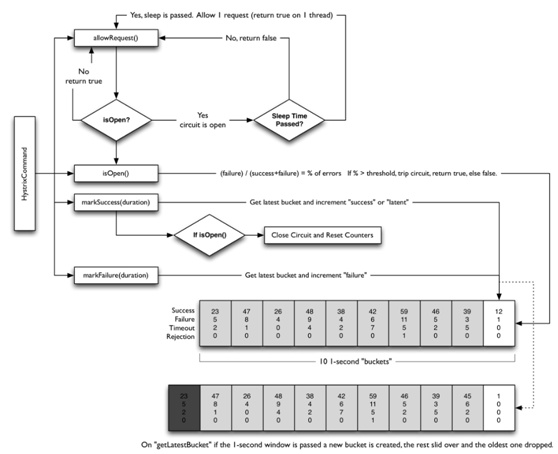
4. Is the Circuit Open?(断路器是否打开)
在命令结果没有缓存命中的时候,Hystrix在执行命令前需检查断路器是否为打开状态:
- 如果是打开的,那么Hystrix不会执行命令,而是转接到fallback处理逻辑(对应下面的第8步)
- 如果断路器是关闭的,那么Hystrix调到第5步,检查是否有可用资源来执行命令。
5. Is the Thread Pool/Queue/Semaphore Full?(线程池/请求队列/信号量是否已经占满)
线程池或者信号量是否已经满负荷,如果已经满负荷那么快速失败
6. HystrixObservableCommand.construct() or HystrixCommand.run())
两个断路器的入口,如果是继承HystrixObservableCommand,那么就调用construct()函数,如果是继承HystrixCommand,那么就调用run()函数。
7. Calculate Circuit Health(计算断路器的健康度)
Hystrix记录了成功,失败,拒绝,超时四种报告
这些报告用于决定哪些用于断路,被断路的点在恢复周期内无法被后来的请求访问到。
8. Get the Fallback
快速失败会在以下几个场景触发
1.由construct() or run()抛出了一个异常
2.断路器已经打开的时候
3.没有空闲的线程池和队列或者信号量
4.一次命令执行超时
可以重写快速失败函数来自定义,
HystrixObservableCommand.resumeWithFallback()
HystrixCommand.getFallback()
9. 成功返回
整体的函数调用流程如下,其实这就是源码的调用流程
源码:
一、AbstractCommand 主要功能点
实现run、getFallback等方法,你就拥有了一个具有基本熔断功能的类。从使用来看,所有的核心逻辑都由AbstractCommand(即HystrixCommand的父类,HystrixCommand只是对AbstractCommand进行了简单包装)抽象类串起来,从功能上来说,AbstractCommand必须将如下功能联系起来:

策略配置:Hystrix有两种降级模型,即信号量(同步)模型和线程池(异步)模型,这两种模型所有可定制的部分都体现在了HystrixCommandProperties和HystrixThreadPoolProperties两个类中。然而还是那句老话,Hystrix只提供了配置修改的入口,没有将配置界面化,如果想在页面上动态调整配置,还需要自己实现。
数据统计:Hystrix以命令模式的方式来控制业务逻辑以及熔断逻辑的调用时机,所以说数据统计对它来说不算难事,但如何高效、精准的在内存中统计数据,还需要一定的技巧。
断路器:断路器可以说是Hystrix内部最重要的状态机,是它决定着每个Command的执行过程。
监控露出:能通过某种可配置方式将统计数据展现在仪表盘上。
二. Hystrix的断路器设计
断路器是Hystrix最核心的状态机,只有了解它的变更条件,我们才能准确掌握Hystrix的内部行为。上面的内部流程图中【断路器状态判断】这个环节直接决定着这次请求(或者说这个Command对象)是尝试去执行正常业务逻辑(即run())还是走降级后的逻辑(即getFallback()),断路器HystrixCircuitBreaker有三个状态,
为了能做到状态能按照指定的顺序来流转,并且是线程安全的,断路器的实现类HystrixCircuitBreakerImpl使用了AtomicReference:
class HystrixCircuitBreakerImpl implements HystrixCircuitBreaker { private final HystrixCommandProperties properties; private final HystrixCommandMetrics metrics; enum Status { CLOSED, OPEN, HALF_OPEN; }
// 断路器初始状态肯定是关闭状态 private final AtomicReference<Status> status = new AtomicReference<Status>(Status.CLOSED);
断路器在状态变化时,使用了AtomicReference#compareAndSet来确保当条件满足时,只有一笔请求能成功改变状态。
那么,什么条件下断路器会改变状态?
1. CLOSED -> OPEN :
时间窗口内(默认10秒)请求量大于请求量阈值(即circuitBreakerRequestVolumeThreshold,默认值是20),并且该时间窗口内错误率大于错误率阈值(即circuitBreakerErrorThresholdPercentage,默认值为50,表示50%),那么断路器的状态将由默认的CLOSED状态变为OPEN状态。看代码可能更直接:
// 检查是否超过了我们设置的断路器请求量阈值 if (hc.getTotalRequests() < properties.circuitBreakerRequestVolumeThreshold().get()) { // 如果没有超过统计窗口的请求量阈值,则不改变断路器状态, // 如果它是CLOSED状态,那么仍然是CLOSED. // 如果它是HALF-OPEN状态,我们需要等待请求被成功执行, // 如果它是OPEN状态, 我们需要等待睡眠窗口过去。 } else { if (hc.getErrorPercentage() < properties.circuitBreakerErrorThresholdPercentage().get()) { //如果没有超过统计窗口的错误率阈值,则不改变断路器状态,, // 如果它是CLOSED状态,那么仍然是CLOSED. // 如果它是HALF-OPEN状态,我们需要等待请求被成功执行, // 如果它是OPEN状态, 我们需要等待【睡眠窗口】过去。 } else { // 如果错误率太高,那么将变为OPEN状态 if (status.compareAndSet(Status.CLOSED, Status.OPEN)) { // 因为断路器处于打开状态会有一个时间范围,所以这里记录了变成OPEN的时间 circuitOpened.set(System.currentTimeMillis()); } } }
这里的错误率是个整数,即errorPercentage= (int) ((double) errorCount / totalCount * 100);,至于睡眠窗口,下面会提到。
2. OPEN ->HALF_OPEN:
前面说过,当进入OPEN状态后,会进入一段睡眠窗口,即只会OPEN一段时间,所以这个睡眠窗口过去,就会“自动”从OPEN状态变成HALF_OPEN状态,这种设计是为了能做到弹性恢复,这种状态的变更,并不是由调度线程来做,而是由请求来触发,每次请求都会进行如下检查:
@Override public boolean attemptExecution() { if (properties.circuitBreakerForceOpen().get()) { return false; } if (properties.circuitBreakerForceClosed().get()) { return true; } // circuitOpened值等于1说明断路器状态为CLOSED if (circuitOpened.get() == -1) { return true; } else { if (isAfterSleepWindow()) { // 睡眠窗口过去后只有第一个请求能被执行 // 如果执行成功,那么状态将会变成CLOSED // 如果执行失败,状态仍变成OPEN if (status.compareAndSet(Status.OPEN, Status.HALF_OPEN)) { return true; } else { return false; } } else { return false; } } } // 睡眠窗口是否过去 private boolean isAfterSleepWindow() { // 还记得上面CLOSED->OPEN时记录的时间吗? final long circuitOpenTime = circuitOpened.get(); final long currentTime = System.currentTimeMillis(); final long sleepWindowTime = properties.circuitBreakerSleepWindowInMilliseconds().get(); return currentTime > circuitOpenTime + sleepWindowTime; }
3. HALF_OPEN ->CLOSED :
变为半开状态后,会放第一笔请求去执行,并跟踪它的执行结果,如果是成功,那么将由HALF_OPEN状态变成CLOSED状态:
@Override public void markSuccess() { if (status.compareAndSet(Status.HALF_OPEN, Status.CLOSED)) { //This thread wins the race to close the circuit - it resets the stream to start it over from 0 metrics.resetStream(); Subscription previousSubscription = activeSubscription.get(); if (previousSubscription != null) { previousSubscription.unsubscribe(); } Subscription newSubscription = subscribeToStream(); activeSubscription.set(newSubscription); // 已经进入了CLOSED阶段,所以将OPEN的修改时间设置成-1 circuitOpened.set(-1L); } }
4. HALF_OPEN ->OPEN :
变为半开状态时,如果第一笔被放去执行的请求执行失败(资源获取失败、异常、超时等),就会由HALP_OPEN状态再变为OPEN状态:
@Override public void markNonSuccess() { if (status.compareAndSet(Status.HALF_OPEN, Status.OPEN)) { // This thread wins the race to re-open the circuit - it resets the start time for the sleep window circuitOpened.set(System.currentTimeMillis()); } }
三. 滑动窗口(滚动窗口)
上面提到的断路器需要的时间窗口请求量和错误率这两个统计数据,都是指固定时间长度内的统计数据,断路器的目标,就是根据这些统计数据来预判并决定系统下一步的行为,Hystrix通过滑动窗口来对数据进行“平滑”统计,默认情况下,一个滑动窗口包含10个桶(Bucket),每个桶时间宽度是1秒,负责1秒的数据统计。滑动窗口包含的总时间以及其中的桶数量都是可以配置的,来张官方的截图认识下滑动窗口:
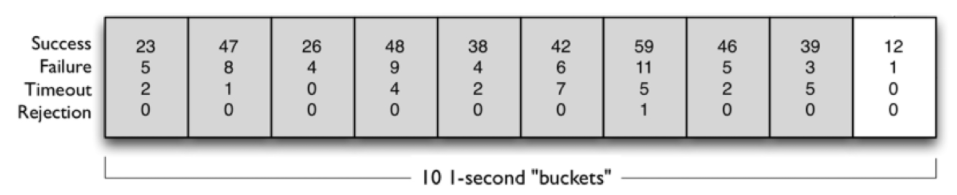
上图的每个小矩形代表一个桶,可以看到,每个桶都记录着1秒内的四个指标数据:成功量、失败量、超时量和拒绝量,这里的拒绝量指的就是上面流程图中【信号量/线程池资源检查】中被拒绝的流量。10个桶合起来是一个完整的滑动窗口,所以计算一个滑动窗口的总数据需要将10个桶的数据加起来。
我们现在来具体看看滑动窗口和桶的设计,如果将滑动窗口设计成对一个长度为10的整形数组的操作,第一个想到的应该是AtomicLongArray,AtomicLongArray中每个位置的数据都能线程安全的操作,提供了譬如incrementAndGet、getAndSet、compareAndSet等常用方法。但由于一个桶需要维护四个指标,如果用四个AtomicLongArray来实现,做法不够高级,于是我们想到了AtomicReferenceArray<Bucket>,Bucket对象内部可以用AtomicLong来维护着这四个指标。滑动窗口和桶的设计特别讲究技巧,需要尽可能做到性能、数据准确性两方面的极致,我们来看Hystrix是如何做到的。
桶的数据统计简单来说可以分为两类,一类是简单自增计数器,比如请求量、错误量等,另一类是并发最大值,比如一段时间内的最大并发量(或者说线程池的最大任务数),下面是桶类Bucket的定义:
class Bucket { // 标识是哪一秒的桶数据 final long windowStart; // 如果是简单自增统计数据,那么将使用adderForCounterType final LongAdder[] adderForCounterType; // 如果是最大并发类的统计数据,那么将使用updaterForCounterType final LongMaxUpdater[] updaterForCounterType; Bucket(long startTime) { this.windowStart = startTime; // 预分配内存,提高效率,不同事件对应不同的数组index adderForCounterType = new LongAdder[HystrixRollingNumberEvent.values().length]; for (HystrixRollingNumberEvent type : HystrixRollingNumberEvent.values()) { if (type.isCounter()) { adderForCounterType[type.ordinal()] = new LongAdder(); } } // 预分配内存,提高效率,不同事件对应不同的数组index updaterForCounterType = new LongMaxUpdater[HystrixRollingNumberEvent.values().length]; for (HystrixRollingNumberEvent type : HystrixRollingNumberEvent.values()) { if (type.isMaxUpdater()) { updaterForCounterType[type.ordinal()] = new LongMaxUpdater(); // initialize to 0 otherwise it is Long.MIN_VALUE updaterForCounterType[type.ordinal()].update(0); } } } //...略... }
我们可以看到,并没有用所谓的AtomicLong,为了方便的管理各种事件(参见com.netflix.hystrix.HystrixEventType)的数据统计,Hystrix对不同的事件使用不同的数组index(即枚举的顺序),这样对于某个桶(即某一秒)的指定类型的数据,总能从数组中找到对应的LongAdder(用于统计前面说的简单自增)或LongMaxUpdater(用于统计前面说的最大并发值)对象来进行自增或更新操作。对于性能有要求的中间件或库类都避不开要CPUCache优化的问题,比如cache line,以及cache line带来的false sharing问题。Bucket的内部并没有使用AtomicLong,而是使用了JDK8新提供的LongAdder,在高并发的单调自增场景,LongAdder提供了比AtomicLong更好的性能,至于LongAdder的设计思想,本文不展开,感兴趣的朋友可以去拜读Doug Lea大神的代码(有意思的是Hystrix没有直接使用JDK中的LongAdder,而是copy过来改了改)。LongMaxUpdater也是类似的,它和LongAddr一样都派生于Striped64,这里不再展开。
滑动窗口由多个桶组成,业界一般的做法是将数组做成环,Hystrix中也类似,多个桶是放在AtomicReferenceArray<Bucket>来维护的,为了将其做成环,需要保存头尾的引用,于是有了ListState类:
class ListState { /* * 这里的data之所以用AtomicReferenceArray而不是普通数组,是因为data需要 * 在不同的ListState对象中跨线程来引用,需要可见性和并发性的保证。 */ private final AtomicReferenceArray<Bucket> data; private final int size; private final int tail; private final int head; private ListState(AtomicReferenceArray<Bucket> data, int head, int tail) { this.head = head; this.tail = tail; if (head == 0 && tail == 0) { size = 0; } else { this.size = (tail + dataLength - head) % dataLength; } this.data = data; } //...略... }
我们可以发现,真正的数据是data,而ListState只是一个时间段的数据快照而已,所以tail和head都是final,这样做的好处是我们不需要去为head、tail的原子操作而苦恼,转而变成对ListState的持有操作,所以滑动窗口看起来如下:
我们可以看到,由于默认一个滑动窗口包含10个桶,所以AtomicReferenceArray<Bucket>的size得达到10+1=11才能“滑动/滚动”起来,在确定的某一秒内,只有一个桶被更新,其他的桶数据都没有变化。既然通过ListState可以拿到所有的数据,那么我们只需要持有最新的ListState对象即可,为了能做到可见性和原子操作,于是有了环形桶类BucketCircularArray:
class BucketCircularArray implements Iterable<Bucket> { // 持有最新的ListState private final AtomicReference<ListState> state; //...略... }
注意到BucketCircularArray实现了迭代器接口,这是因为我们输出给断路器的数据需要计算滑动窗口中的所有桶,于是你可以看到真正的滑动窗口类HystrixRollingNumber有如下属性和方法:
public class HystrixRollingNumber { // 环形桶数组 final BucketCircularArray buckets; // 获取该事件类型当前滑动窗口的统计值 public long getRollingSum(HystrixRollingNumberEvent type) { Bucket lastBucket = getCurrentBucket(); if (lastBucket == null) return 0; long sum = 0; // BucketCircularArray实现了迭代器接口环形桶数组 for (Bucket b : buckets) { sum += b.getAdder(type).sum(); } return sum; } //...略... }
断路器就是通过监控来从HystrixRollingNumber的getRollingSum方法来获取统计值的。
到这里断路器和滑动窗口的核心部分已经分析完了,当然里面还有不少细节没有提到,感兴趣的朋友可以去看一下源码。Hystrix中通过RxJava来实现了事件的发布和订阅,所以如果想深入了解Hystrix,需要熟悉RxJava,而RxJava在服务端的应用没有像客户端那么广,一个原因是场景的限制,还一个原因是大多数开发者认为RxJava设计的过于复杂,加上响应式编程模型,有一定的入门门槛。
四、线程池隔离
.withExecutionIsolationStrategy(HystrixCommandProperties.ExecutionIsolationStrategy.THREAD));
.withKeepAliveTimeMinutes(resourcesManager.getThreadPoolProperties(platformProtocol.getAppId()).getKeepAliveSeconds())
.withMaxQueueSize(resourcesManager.getThreadPoolProperties(platformProtocol.getAppId()).getMaxQueueSize())
@Override public boolean isQueueSpaceAvailable() { if (queueSize <= 0) { // we don't have a queue so we won't look for space but instead // let the thread-pool reject or not return true; } else { return threadPool.getQueue().size() < properties.queueSizeRejectionThreshold().get(); } }
public Thread newThread(Runnable r) {
Thread thread = new Thread(r, "hystrix-" + threadPoolKey.name() + "-" + threadNumber.incrementAndGet());
thread.setDaemon(true);
return thread;
// this should find it for all but the first time
HystrixThreadPool previouslyCached = threadPools.get(key);
if (previouslyCached != null) {
return previouslyCached;
}
// if we get here this is the first time so we need to initialize
synchronized (HystrixThreadPool.class) {
if (!threadPools.containsKey(key)) {
threadPools.put(key, new HystrixThreadPoolDefault(threadPoolKey, propertiesBuilder));
}
}
return Observable.create(new OnSubscribe<R>() {
@Override
public void call(Subscriber<? super R> s) {
try {
s.onNext(run());
s.onCompleted();
} catch (Throwable e) {
s.onError(e);
}
}
});
}
二、模块详解
2.1、创建请求命令
2.1.1、有4种方式
1、同步阻塞方法,其实就是调用了queue().get()
2、异步非阻塞方法,直接返回Future,可以先做自己的事情,做完再.get()
3、热观察,可以被立即执行,如果订阅了那么会重新通知,其实就是调用了toObservable()并内置ReplaySubject,详细可以参考RxJava
4、冷观察,返回一个Observable对象,当调用此接口,还需要自己加入订阅者,才能接受到信息,详细可以参考RxJava
2.1.2、原生模式
基于hystrix的原生接口,也就是继承HystrixCommand或者HystirxObservableCommand。
在《服务容错保护断路器Hystrix之一:入门介绍》中的示例基础上修改如下,
同步方式/异步方式:
package com.dxz.ribbon; import org.springframework.web.client.RestTemplate; import com.netflix.hystrix.HystrixCommand; import com.netflix.hystrix.HystrixCommandGroupKey; public class ComputeCommand extends HystrixCommand<String> { RestTemplate restTemplate; String a; String b; protected ComputeCommand(RestTemplate restTemplate, String a, String b) { super(HystrixCommandGroupKey.Factory.asKey("ExampleGroup")); this.restTemplate = restTemplate; this.a = a; this.b = b; } @Override protected String run() throws Exception { return restTemplate.getForEntity("http://compute-service/add?a="+a +"&b="+b+"&sn=1", String.class).getBody(); } /** * 快速失败后调用函数 * @return */ @Override protected String getFallback(){ return "404 :)"; } }
观察方式:
package com.dxz.ribbon; import org.springframework.web.client.RestTemplate; import com.netflix.hystrix.HystrixCommandGroupKey; import com.netflix.hystrix.HystrixObservableCommand; import rx.Observable; import rx.Subscriber; public class ComputeObservableCommand extends HystrixObservableCommand<String> { RestTemplate restTemplate; String a; String b; protected ComputeObservableCommand(RestTemplate restTemplate, String a, String b) { super(HystrixCommandGroupKey.Factory.asKey("ExampleGroup")); this.restTemplate = restTemplate; this.a = a; this.b = b; } @Override protected Observable<String> construct() { return Observable.create(new Observable.OnSubscribe<String>() { @Override public void call(Subscriber<? super String> observer) { if(!observer.isUnsubscribed()) { String result = restTemplate.getForEntity("http://compute-service/add?a="+a +"&b="+b+"&sn=1", String.class).getBody(); observer.onNext(result); observer.onCompleted(); } } }); } }
调用方法:
package com.dxz.ribbon; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; import org.springframework.web.client.RestTemplate; import rx.functions.Action1; @RestController public class ConsumerController2 { @Autowired RestTemplate restTemplate; @RequestMapping(value = "/add2", method = RequestMethod.GET) public String add(@RequestParam String m) throws InterruptedException, ExecutionException { if("s".equals(m)) { String result = new ComputeCommand(restTemplate, "1", "2").execute(); System.out.println("result:="+result); return result; } else if("a".equals(m)) { Future<String> result = new ComputeCommand(restTemplate, "1", "2").queue(); System.out.println("result:="+result.get()); return result.get(); } else { ComputeObservableCommand command1 = new ComputeObservableCommand(restTemplate, "1","2"); rx.Observable<String> result = command1.observe(); result.subscribe(new Action1<String>() { @Override public void call(String s) { System.out.println("Command called. Result is:" + s); } }); return null; } } }
结果:
2.1.3、注解模式
在《服务容错保护断路器Hystrix之一:入门介绍》已经展示过。
2.2、定义服务降级
有些情况不去实现降级逻辑,如下所示。
执行写操作的命令:当Hystrix命令是用来执行写操作而不是返回一些信息的时候,通常情况下这类操作的返回类型时void或是为空的Observable,实现服务降级的意义不是很大。当写入操作失败的时候,我们通常只需要通知调用者即可。
执行批处理或离线计算的命令:当Hystrix命令是用来执行批处理程序生成一份报告或是进行任何类型的离线计算时,那么通常这些操作只需要将错误传播给调用者,然后让调用者稍后重试而不是发送给调用者一个静默的降级处理响应。
2.3、工作流程图
2.4、开关条件
关于断路器打开
·时间窗口内请求次数(限流)
如果在10s内,超过某个阈值的请求量,才会考虑断路(小于这个次数不会被断路)
配置是circuitBreaker.requestVolumeThreshold
默认10s 20次
·失败率
默认失败率超过50%就会被断路
配置是circuitBreaker.errorThresholdPercentage
关于断路器关闭
·重新尝试
在一定时间之后,重新尝试请求来决定是否继续打开或者选择关闭断路器
配置是circuitBreaker.sleepWindowInMilliseconds
默认5000ms
2.5、关于隔离
bulkhead pattern模式(舱壁模式)
Htstrix使用了bulkhead pattern模式,典型的例子就是线程隔离。
简单解释一下bulkhead pattern模式。一般情况我们都用一个线程池来管理所有线程,容易造成一个问题,粒度太粗,无法对线程进行分类管理,会导致局部问题影响全局。bulkhead pattern模式在于,采用多个线程池来管理线程,这样使得1个线程池资源出现问题时不会造成另一个线程池资源问题。尽量使问题最小化。
如图所示,采用了bulkhead pattern模式的效果
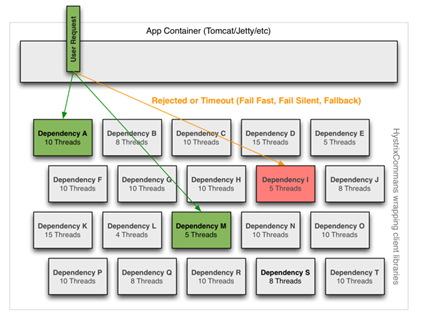
说完原理说实现,如何针对不同依赖采用不同的线程池管理呢
Hystrix给了我们三种key来用于隔离:
·CommandKey,针对相同的接口一般CommandKey值相同,目的是把HystrixCommand,HystrixCircuitBreaker,HytrixCommandMerics以及其他相关对象关联在一起,形成一个原子组。采用原生接口的话,默认值为类名;采用注解形式的话,默认值为方法名。
·CommandGroupKey,对CommandKey分组,用于真正的隔离。相同CommandGroupKey会使用同一个线程池或者信号量。一般情况相同业务功能会使用相同的CommandGroupKey。
·ThreadPoolKey,如果说CommandGroupKey只是逻辑隔离,那么ThreadPoolKey就是物理隔离,当没有设置ThreadPoolKey的时候,线程池或者信号量的划分按照CommandGroupKey,当设置了ThreadPoolKey,那么线程池和信号量的划分就按照ThreadPoolKey来处理,相同ThreadPoolKey采用同一个线程池或者信号量。
Coding
原生模式
可以通过HystrixCommand.Setter来自定义配置
HystrixCommandGroupKey.Factory.asKey(""))
HystrixCommandKey.Factory.asKey("")
HystrixThreadPoolKey.Factory.asKey("")
注解模式
可以直接在方法名上添加
@HystrixCommand(groupKey = "", commandKey = "", threadPoolKey = "")
2.6、关于请求缓存
工作流程图
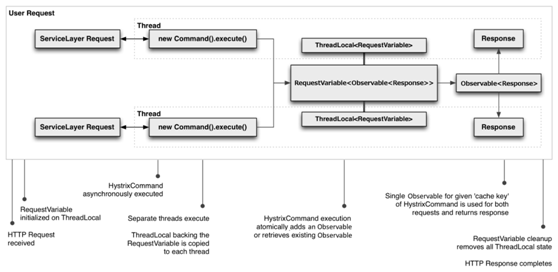
优势
·复用性
这里的复用性指的是代码复用性
·一致性
也就是常说的幂等性,不管请求几次,得到的结果应该都是一样的
·减少重复工作
由于请求缓存是在HystrixCommand的construct()或run()运行之前运行,所有可以有效减少线程的使用
适用场景
请求缓存的优势显而易见,但是也不是银弹。
在读少写多的场景就显得不太合适,对于读的请求,需要add缓存。对于增删改的请求,需要把缓存remove。在增加系统资源开销的同时,又很鸡肋。
所以一般适合读多写少的场景。似乎所有缓存机制都有这个局限性吧。
Coding
原生模式
继承HystrixCommand后,重写getCacheKey()方法,该方法默认返回的是null,也就是不使用请求缓存功能。相同key的请求会使用相同的缓存。
package com.dxz.ribbon; import org.springframework.web.client.RestTemplate; import com.netflix.hystrix.HystrixCommand; import com.netflix.hystrix.HystrixCommandGroupKey; public class ComputeCommandCache extends HystrixCommand<String> { RestTemplate restTemplate; String a; String b; protected ComputeCommandCache(RestTemplate restTemplate, String a, String b) { super(HystrixCommandGroupKey.Factory.asKey("ExampleGroup")); this.restTemplate = restTemplate; this.a = a; this.b = b; } @Override protected String run() throws Exception { return restTemplate.getForEntity("http://compute-service/add?a="+a +"&b="+b+"&sn=1", String.class).getBody(); } @Override protected String getCacheKey() { System.out.println("调用getCacheKey");//打印一下什么时候会触发 return a + b; } /** * 快速失败后调用函数 * @return */ @Override protected String getFallback(){ return "404 :)"; } }
调用类,如果不加HystrixRequestContext.initializeContext();//初始化请求上下文,会报错如下:
报错了:java.util.concurrent.ExecutionException: Observable onError
Caused by: java.lang.IllegalStateException: Request caching is not available. Maybe you need to initialize the HystrixRequestContext?
package com.dxz.ribbon; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; import org.springframework.web.client.RestTemplate; import com.netflix.hystrix.strategy.concurrency.HystrixRequestContext; import rx.functions.Action1; @RestController public class ConsumerControllerCache { @Autowired RestTemplate restTemplate; @RequestMapping(value = "/add3", method = RequestMethod.GET) public String add(@RequestParam String m) throws InterruptedException, ExecutionException { HystrixRequestContext.initializeContext();//初始化请求上下文 if("s".equals(m)) { String result = new ComputeCommandCache(restTemplate, "1", "2").execute(); System.out.println("result:="+result); return result; } else if("a".equals(m)) { Future<String> result = new ComputeCommandCache(restTemplate, "1", "2").queue(); System.out.println("result:="+result.get()); return result.get(); } else { ComputeObservableCommand command1 = new ComputeObservableCommand(restTemplate, "1","2"); rx.Observable<String> result = command1.observe(); result.subscribe(new Action1<String>() { @Override public void call(String s) { System.out.println("Command called. Result is:" + s); } }); return null; } } }
注解模式
在方法名上增加,并添加与cacheKeyMethod字符串相同的方法。两者共用入参。

@CacheResult(cacheKeyMethod = "getCacheKey")
public String post2AnotherService(String seed){
}
public String getCacheKey(String seed){
return seed;
}
初始化HystrixRequestContext
还有关键的一步,在调用HystrixCommand之前初始化HystrixRequestContext,其实就是创建一个ThreadLocal的副本,共享请求缓存就是通过ThreadLocal来实现的。
HystrixRequestContext context=HystrixRequestContext.initializeContext(); 操作完成后context.shutdown(); 一般情况可以在过滤器中控制是初始化和关闭整个生命周期
//启动HystrixRequestContext
HystrixRequestContext context = HystrixRequestContext.initializeContext();
try {
chain.doFilter(req, res);
} finally {
//关闭HystrixRequestContext
context.shutdown();
}
2.7、关于请求合并(Requst Collapsing)
工作流程图
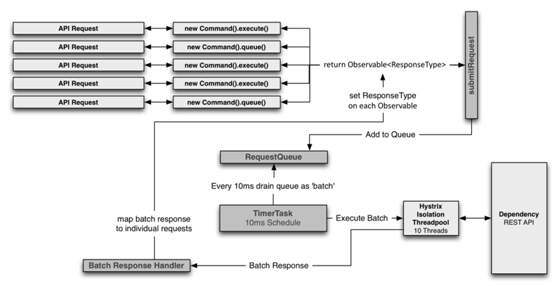
上半部分是模拟请求,下半部分是该请求的依赖设置,时间窗口默认是10ms,在这个时间窗口内,所有对于该接口的请求都会被加入队列,然后进行批处理。这样的好处在于,如果短时间内对于某个接口有大量请求,那么可以只处理一次就完成所有响应。
优势
全局线程合并
在tomcat容器中,所有请求共用一个进程,也就是一个JVM容器,在并发场景下会派生出许多线程,collapsing可以合并整个JVM中的请求线程,这样可以解决不同使用者同时请求的大量并发问题。
局部线程合并
可以合并单个tomcat请求线程,比如在10ms内有10个请求被同一线程处理(这不是像往常一样请求->处理,而是请求->加入请求队列,所有可以快速收集请求),那这些请求可以被合并。
对象建模和代码复杂度
在实际场景下,调用接口取数据的复杂度往往高于数据的复杂度,通俗来说就是取数据可以千变万化的取,而数据就那么几个接口。
collapsing可以帮助你更好的实现你的业务,比如多次请求合并结果后再广播出去。
适用场景
·并发量大接口
当并发量小,一个时间窗口内只有几个或没有请求,那么就白白浪费了请求合并的资源。
·请求耗时接口
时间窗口是固定的,假如一个请求实际耗时10ms,加上固定的时间窗口,最大延迟达到20ms,延迟被提高了100%。若一个请求实际耗时有1s,那么时间窗口的延迟就可以被忽略不计。
Coding
原生模式
/**
* 批量返回值类型
* 返回值类型
* 请求参数类型
*/
public class CommandCollapserGetValueForKey extends HystrixCollapser<List<String>, String, Integer> {
private static Logger logger = LoggerFactory.getLogger(CommandCollapserGetValueForKey.class);
private final Integer key;
public CommandCollapserGetValueForKey(Integer key) {
this.key = key;
}
/**
*获取请求参数
*/
public Integer getRequestArgument() {
return key;
}
/**
*合并请求产生批量命令的具体实现
*/
protected HystrixCommand<List<String>> createCommand(final Collection<CollapsedRequest<String, Integer>> requests) {
return new BatchCommand(requests);
}
/**
*批量命令结果返回后的处理,需要实现将批量结果拆分并传递给合并前的各原子请求命令的逻辑中
*/
protected void mapResponseToRequests(List<String> batchResponse, Collection<CollapsedRequest<String, Integer>> requests) {
int count = 0;
//请求响应一一对应
for (CollapsedRequest<String, Integer> request : requests) {
request.setResponse(batchResponse.get(count++));
}
}
private static final class BatchCommand extends HystrixCommand<List<String>> {
private static Logger logger = LoggerFactory.getLogger(CommandCollapserGetValueForKey.BatchCommand.class);
private final Collection<CollapsedRequest<String, Integer>> requests;
private BatchCommand(Collection<CollapsedRequest<String, Integer>> requests) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("ExampleGroup"))
.andCommandKey(HystrixCommandKey.Factory.asKey("GetValueForKey")));
this.requests = requests;
}
@Override
protected List<String> run() {
ArrayList<String> response = new ArrayList<String>();
// 处理每个请求,返回结果
for (CollapsedRequest<String, Integer> request : requests) {
logger.info("request.getArgument()={}",request.getArgument());
// artificial response for each argument received in the batch
response.add("ValueForKey: " + request.getArgument());
}
return response;
}
}
}
调用的时候只需要new CommandCollapserGetValueForKey(1).queue()
在同一个时间窗口内,批处理的函数调用顺序为
getRequestArgument()->createCommand()->mapResponseToRequests()
//官方配置文档
https://github.com/Netflix/Hystrix/wiki/Configuration#circuitBreaker.sleepWindowInMilliseconds