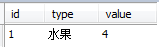
两张表:


sql脚本如下:
CREATE TABLE `test`.`category` ( `id` INT NOT NULL, `type` VARCHAR(45) NULL, PRIMARY KEY (`id`)); CREATE TABLE `test`.`product` ( `id` INT NOT NULL, `typeid` VARCHAR(45) NULL, `name` VARCHAR(45) NULL, PRIMARY KEY (`id`)); INSERT INTO `test`.`category` (`id`, `type`) VALUES ('1', '水果'); INSERT INTO `test`.`category` (`id`, `type`) VALUES ('2', '菜'); INSERT INTO `test`.`product` (`id`, `typeid`, `name`) VALUES ('1', '1', '苹果'); INSERT INTO `test`.`product` (`id`, `typeid`, `name`) VALUES ('2', '2', '大白菜'); INSERT INTO `test`.`product` (`id`, `typeid`, `name`) VALUES ('3', '2', '豆角'); INSERT INTO `test`.`product` (`id`, `typeid`, `name`) VALUES ('4', '1', '西瓜');
按照category表中的品种统计product表中的数量:
select c.id, c.type, count(p.id) as value from category c left join product p on c.id=p.typeid group by c.id,c.type;
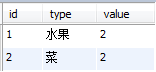
这里要说的是group by,分类统计。不要忘了。否则成了下面这样:
select c.id, c.type, count(p.id) as value from category c left join product p on c.id=p.typeid