delay-queue
redis实现延迟消息队列
需求背景
最近在做一个排队取号的系统
- 在用户预约时间到达前XX分钟发短信通知
- 在用户预约时间结束时要判断用户是否去取号了,不然就记录为爽约
- 在用户取号后开始,等待XX分钟后要发短信提醒是否需要使用其他渠道办理
类似的场景太多,最简单的解决办法就是定时任务去扫表。这样每个业务都要维护自己的扫表逻辑,
而且随着时间的推移数据量会越来越多的,有的数据可能会延迟比较大
经过一番搜索,网上说rabbitmq可以满足延迟执行需求,但是目前系统用了其他消息中间件,所以不打算用。
基于Redis实现的延迟消息队列java版:项目github地址:delay-queue
整体结构
整个延迟队列由4个部分组成:
- JobPool用来存放所有Job的元信息。利用redis 的hash结构
- DelayBucket是一组以时间为维度的有序队列,用来存放所有需要延迟的Job(这里只存放Job Id)。利用redis 的 有序集合zset
- Timer负责实时扫描各个Bucket,并将delay时间大于等于当前时间的Job放入到对应的Ready Queue。利用redis 的list 结构
- ReadyQueue存放处于Ready状态的Job(这里只存放JobId),以供消费程序消费。

消息结构
每个Job必须包含一下几个属性:
- topic:Job类型。可以理解成具体的业务名称。
- id:Job的唯一标识。用来检索和删除指定的Job信息。
- delayTime:jod延迟执行的时间,13位时间戳
- ttr(time-to-run):Job执行超时时间。单位:秒。主要是为了消息可靠性
- message:Job的内容,供消费者做具体的业务处理,以json格式存储。
举例说明一个Job的生命周期
-
用户预约后,同时往JobPool里put一个job。job结构为:{‘topic':'book’, ‘id':'123456’, ‘delayTime’:1517069375398 ,’ttrTime':60 , ‘message':’XXXXXXX’}
同时以jobId作为value,delayTime作为score 存到bucket 中,用jobId取模,放到10个bucket中,以提高效率 -
timer每时每刻都在轮询各个bucket,按照score排序去最小的一个,当delayTime < 当前时间后,,取得job id从job pool中获取元信息。
如果这时该job处于deleted状态,则pass,继续做轮询;如果job处于非deleted状态,首先再次确认元信息中delayTime是否大于等于当前时间,
如果满足则根据topic将jobId放入对应的ready queue,然后从bucket中移除,并且;如果不满足则重新计算delay时间,再次放入bucket,并将之前的job id从bucket中移除。 -
消费端轮询对应的topic的ready queue,获取job后做自己的业务逻辑。与此同时,服务端将已经被消费端获取的job按照其设定的TTR,重新计算执行时间,并将其放入bucket。
消费端处理完业务后向服务端响应finish,服务端根据job id删除对应的元信息。如果消费端在ttr时间内没有响应,则ttr时间后会再收到该消息
后续扩展
- 加上超时重发次数
实现思路
任务job内容包含Array{0,0,2m,10m,10m,1h,2h,6h,15h}和通知到第几次N(这里N=1, 即第1次).
消费者从队列中取出任务, 根据N取得对应的时间间隔为0, 立即发送通知.
第1次通知失败, N += 1 => 2
从Array中取得间隔时间为2m, 添加一个延迟时间为2m的任务到延迟队列, 任务内容仍包含Array和N
第2次通知失败, N += 1 => 3, 取出对应的间隔时间10m, 添加一个任务到延迟队列, 同上
......
第7次通知失败, N += 1 => 8, 取出对应的间隔时间15h, 添加一个任务到延迟队列, 同上
第8次通知失败, N += 1 => 9, 取不到间隔时间, 结束通知
引用说明
参考有赞延迟队列思路设计实现
背景
在业务发展过程中,会出现一些需要延时处理的场景,比如:
a.订单下单之后超过30分钟用户未支付,需要取消订单
b.订单一些评论,如果48h用户未对商家评论,系统会自动产生一条默认评论
c.点我达订单下单后,超过一定时间订单未派出,需要超时取消订单等。。。
处理这类需求,比较直接简单的方式就是定时任务轮训扫表。这种处理方式在数据量不大的场景下是完全没问题,但是当数据量大的时候高频的轮训数据库就会比较的耗资源,导致数据库的慢查或者查询超时。所以在处理这类需求时候,采用了延时队列来完成。
几种延时队列
延时队列就是一种带有延迟功能的消息队列。下面会介绍几种目前已有的延时队列:
1.Java中java.util.concurrent.DelayQueue
优点:JDK自身实现,使用方便,量小适用
缺点:队列消息处于jvm内存,不支持分布式运行和消息持久化
2.Rocketmq延时队列
优点:消息持久化,分布式
缺点:不支持任意时间精度,只支持特定level的延时消息
3.Rabbitmq延时队列(TTL+DLX实现)
优点:消息持久化,分布式
缺点:延时相同的消息必须扔在同一个队列
根据自身业务和公司情况,如果实现一个自己的延时队列服务需要考虑一下几点:
* 消息存储
* 过期延时消息实时获取
* 高可用性
基于Redis实现
1.0版本
功能特性
* 消息可靠性,消息持久化,消息至少被消费一次
* 实时性:存在一定的时间误差(定时任务间隔)
* 支持指定消息remove
* 高可用性
整体结构
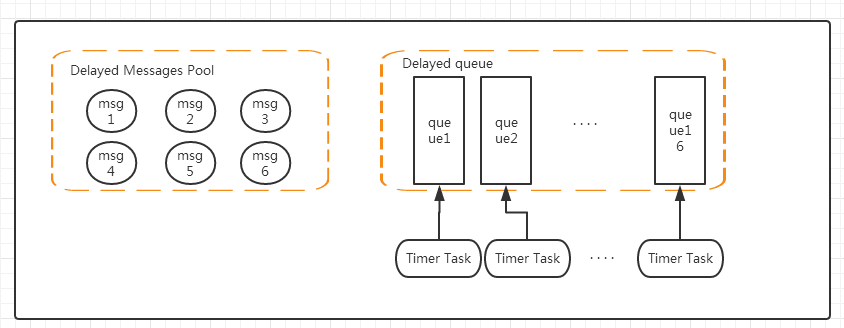
- Messages Pool所有的延时消息存放,结构为KV结构,key为消息ID,value为一个具体的message(这里选择Redis Hash结构主要是因为hash结构能存储较大的数据量,数据较多时候会进行渐进式rehash扩容,并且对于HSET和HGET命令来说时间复杂度都是O(1))
- Delayed Queue是16个有序队列(队列支持水平扩展),结构为ZSET,value为messages pool中消息ID,score为过期时间(分为多个队列是为了提高扫描的速度)
- Timed Task定时任务,负责扫描处理每个队列过期消息
消息结构
每个延时消息必须包括以下参数:
* tags:消息过期之后发送mq的tags
* keys:消息过期之后发送mq的keys
* body:消息过期之后发送mq的body,提供给消费这做具体的消息处理
* delayTime:延时发送时间(默认,delayTime、expectDate有一个即可)
* expectDate:期望发送时间
流程
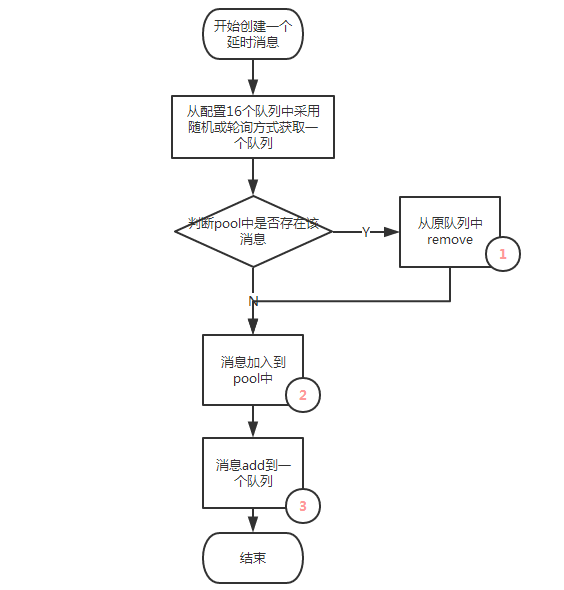
注:上图1、2、3或者2、3是一个事务操作
取出过期消息过程是通过一个外部定时任务每隔1min分钟去查询队列中过期的消息,然后发送mq && remove
2.0版本
1.0上有一个可改进的地方就是队列中过期的消息是通过定时任务触发查询。所有有了2.0
2.0版本在1.0上做了一个优化,废弃掉了1min定时任务触发过期消息发送,采用了java Lock await/singlal方式实现过期消息的实时发送低延时
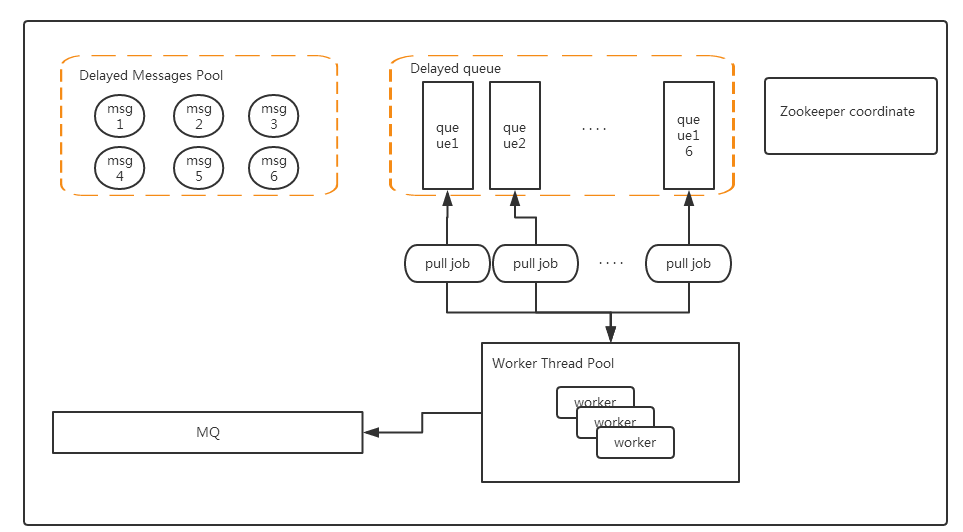
多节点部署结构:
- pull job:这里分别为每一个队列创建了一个pull job thread,功能很简单,就是负责去队列中拉取过期的消息数据(这里保证一个队列有且只有一个pull job)
- worker:pull job拉取到的过期消息会交给一个worker thread去处理,这样的好处是处理过期的消息实时性更高(pull job不必等去除过期消息全部处理完成在继续去拉取新的过期数据)
- zookeeper coordinate:通过zk的操作来完成对队列的重新分配工作,daemon thread监听zk节点的创建和删除
主要流程:
服务启动会注册zk,获取分配处理的queues,启动后台线程监听zk
为每个分配queue创建一个pull job
pull job首先会去queue中查询是否有过期消息:
Y:将取出消息交给worker处理
N:查询queue中最后一个成员(zset结构默认按score递增排序),如果为空,则await;不为空则await(成员score-System.currentTimeMillis())
由于过期消息发送成功才会从队列中remove,所以pull job会记录上一次查询队列的一个offset,每次获取到过期消息会将offset向前偏移,过期消息交给worker处理,当worker由于某些异常原因处理失败会重置pull job中offset,这样可以避免消息发送一次失败之后没办法在继续处理(除了新节点add || remove时候)
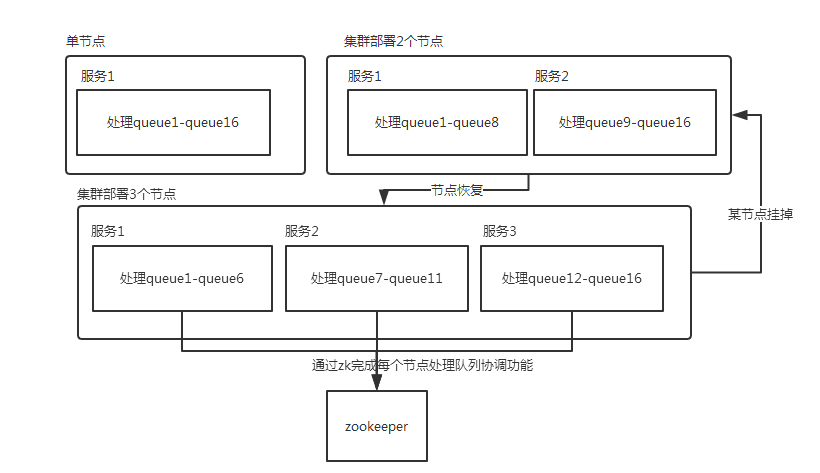
当部署服务有新增,延时队列服务会重新计算得到当前处理队列,并将之前创建pull job cancel,为新处理队列重新创建pull job。删除同理。
</ol>
作者:杨文杰
链接:https://www.jianshu.com/p/e958e8590020
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。