首先要了解database与instance区别,见《MySQL中的实例、数据库关系简介》
跨库分为同一个instance下的跨库和不同instance下的跨库。
一、同一个MySQL实例下的跨库
先看一个示例,某个微服务下的应用要关联查询account_data.account和member_data.login_data,可以通过带数据库名进行关联查询。
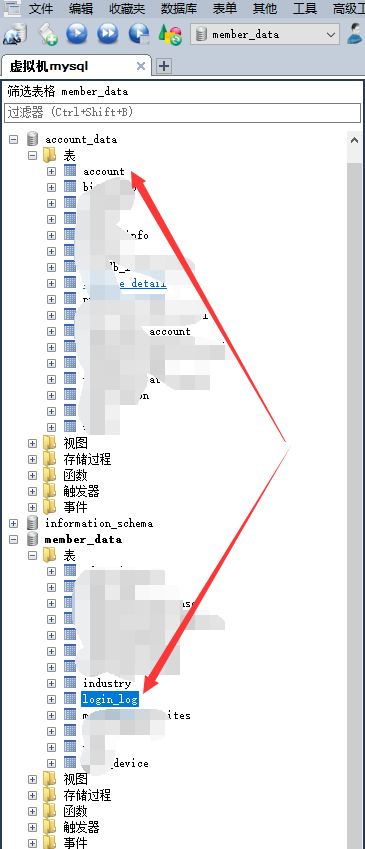
SQL脚本:
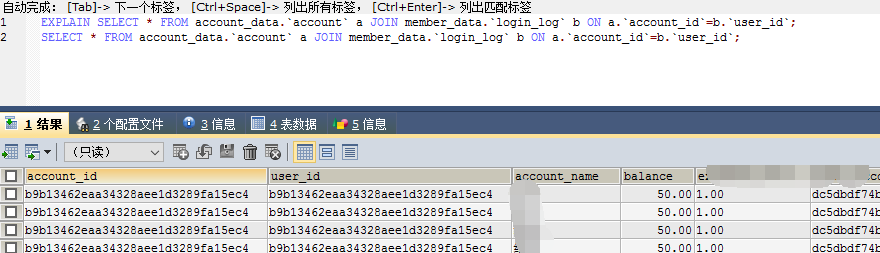
EXPLAIN SELECT * FROM account_data.`account` a JOIN member_data.`login_log` b ON a.`account_id`=b.`user_id`; SELECT * FROM account_data.`account` a JOIN member_data.`login_log` b ON a.`account_id`=b.`user_id`;
结果:
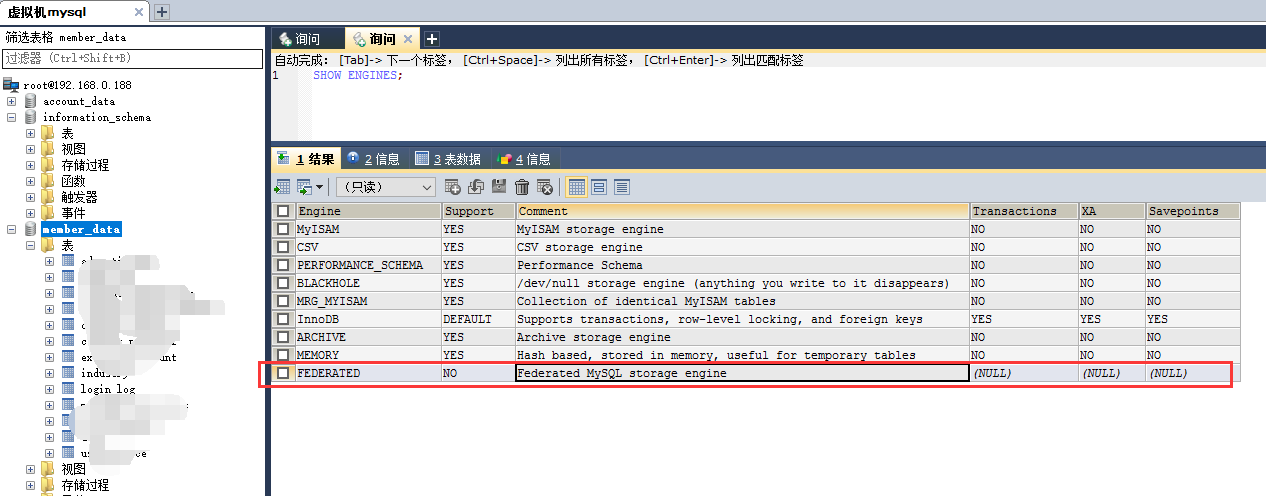
看下此时的引擎设置:
二、不同MySQL实例下的跨库
业务场景:关联不同数据库中的表的查询
比如说,要关联的表是:机器A上的数据库A中的表A && 机器B上的数据库B中的表B。
这种情况下,想执行“select A.id,B.id from A left join B on ~~~;“那是不可能的,但业务需求不可变,数据库设计不可变,这就蛋疼了。。
解决方案:在机器A上的数据库A中建一个表B。。。
这当然不是跟你开玩笑啦,我们采用的是基于MySQL的federated引擎的建表方式。
建表语句示例:CREATE TABLE `table_name`(......) ENGINE =FEDERATED CONNECTION='mysql://[username]:[password]@[location]:[port]/[db-name]/[table-name]'
前提条件:你的mysql得支持federated引擎(执行show engines;可以看到是否支持)。
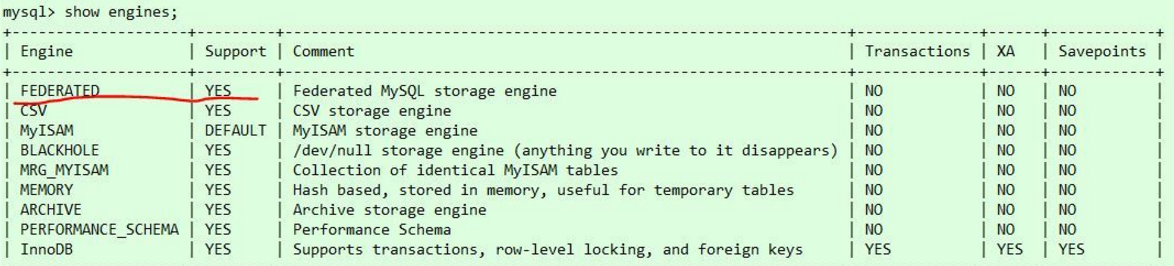
如果有FEDERATED引擎,但Support是NO,说明你的mysql安装了这个引擎,但没启用,去my.cnf文件末添加一行 federated ,重启mysql即可;
如果压根就没有FEDERATED这一行,说明你的mysql就没有安装这个引擎,这就不能愉快的玩耍了,最好去找你们家运维搞定吧,因为接下来的动作比较大,而且我也不知道怎么搞;
解释:通过FEDERATED引擎创建的表只是在本地有表定义文件,数据文件则存在于远程数据库中,通过这个引擎可以实现类似Oracle 下DBLINK的远程数据访问功能。就是说,这种建表方式只会在数据库A中创建一个表B的表结构文件,表的索引、数据等文件还是在机器B上的数据库B中,相当于只是在数据库A中创建了表B的一个快捷方式。
需要注意的几点:
1. 本地的表结构必须与远程的完全一样。
2.远程数据库目前仅限MySQL
3.不支持事务
4.不支持表结构修改