pd.qcut, pd.cut, df.groupby()等在分组和聚合方面的应用
量化交易里, 需要进行大量的分组和统计, 以方便自己处优势的位置/机会.
比如对股价进行趋势分析, 波动性分析, 量化之后, 进行归类统计, 再进行胜算概率的统计.
依据D8和T8的区间, 能够组合出来16种情形, 每一种case都是人们搭建起来的一幅美丽的场景.
研究和观察每一幅场景出现以后, 随后的几天里的表现, 那是非常令人期待的事情.
TD图的统计展示, 还没有做完, 先留下部分结果:
代码:
def study_t_d_map():
stk=load_symbol('000895.sz', start='2016-01-01')
c=stk.ohlc.close
dft=pd.DataFrame()
n=32
dft['c']=c
#dft['std'] = ttr.stddev(c,32)
#dft['std_'] = c.rolling(32).std()
#dft['lr'] = ttr.linreg(c,n)
#slope = ta.LINEARREG_SLOPE(c,n)
dft['trendNorm'] = trendNorm(c,32)
dft['trend16'] = trendNorm(c,16)
dft['trend8'] = trendNorm(c,8)
beta = ttr.estimateBeta(dft.trend16+15, dft.trend8+15)
print('beta(T16, T8): ', beta) # 0.10
fig,ax = plt.subplots(1,1)
ax.scatter(dft.trend8, dft.trend16)
dft['v32'] = ttr.stddev(c,32)/ ta.LINEARREG(c,32)
dft['v16'] = ttr.stddev(c,16)/ ta.LINEARREG(c,16)
dft['v8'] = ttr.stddev(c,8)/ ta.LINEARREG(c,8)
dft['D'] = (c-ttr.linreg(c,n) )/ ta.STDDEV(c,n)
n=16; dft['D16'] = (c-ttr.linreg(c,n) )/ ta.STDDEV(c,n)
n=8; dft['D8'] = (c-ttr.linreg(c,n) )/ ta.STDDEV(c,n)
print('==>数据的长度是: {}'.format(len(c)))
beta2 = ttr.estimateBeta(dft.D16+5, dft.D8+5)
print('beta(D16, D8): ', beta2) # 0.67
fig,(ax1,ax2) = plt.subplots(1,2)
ax1.scatter(dft.D8, dft.D16)
ax2.scatter(dft.D8, dft.trend8)
ax2.set_title('D8 - T8 map')
beta3 = ttr.estimateBeta(dft.D8+15, dft.trend8+15)
print('beta(D8, T8): ', beta3) # 0.23
roc2 = ttr.roc(c,2).shift(-2)
D8 = dft['D8']
T8 = dft['trend8']
#whichCut=value_cut # quantile_cut
whichCut= 'cut'
if whichCut== 'qcut':
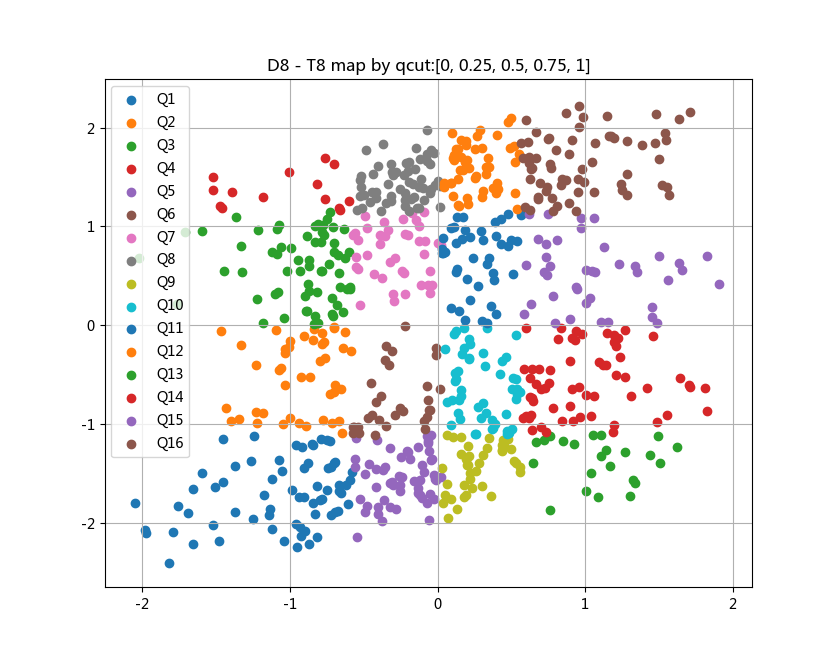
cut=quantile=[0,0.25,0.5,0.75,1]
d_key = pd.qcut(D8, q=quantile,
labels=['BDL', 'NDL','NDR','BDR'])
t_key = pd.qcut(T8, q=quantile,
labels=['BTD', 'NTD','NTU','BTU'])
else:
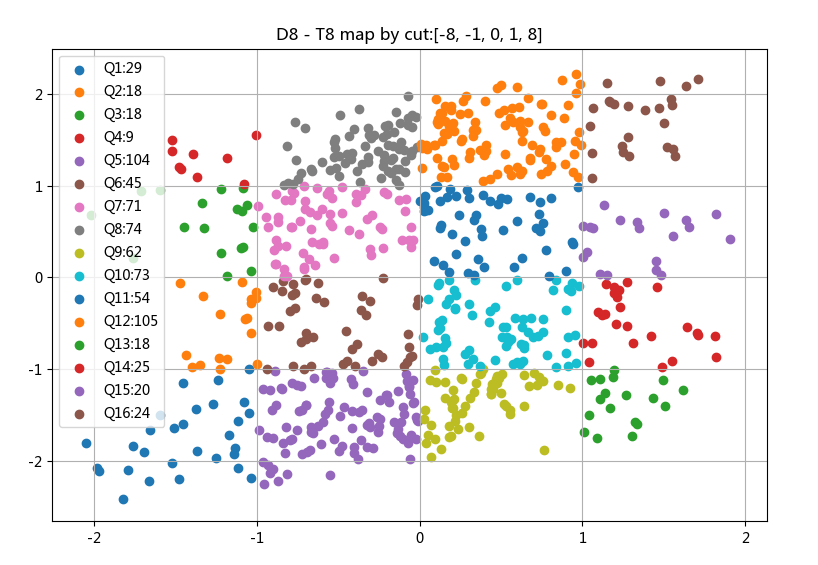
cut=[-8,-1,0 ,1,8]
d_key = pd.cut(D8, bins=cut)
t_key = pd.cut(T8, bins=cut)
r=pd.DataFrame()
#r['c'] = c
r['roc2'] = roc2.dropna()
r['d_key'] = d_key
r['t_key'] = t_key
def count_positive_returns(x):
count,countp,countn=0,0,0
cumr=1.0
for e in x:
cumr *= (1.+e)
count += 1
if e>=0:
countp += 1
else:
countn += 1
return ( count, countp, countn ,round(cumr,3) )
groupby = r['roc2'].groupby([r['d_key'], r['t_key']])
tot_count = groupby.count()
p_count = groupby.apply(count_positive_returns)
p_count
#把一片一片的分组数据做成 字典
pian = OrderedDict(list(groupby))
D8T8, count_list= [],[]
for k in pian.keys():
# pian[('BDL','BTD')]
len_=len(pian[k])
print(len_)
count_list.append(len_)
D8T8.append( pd.DataFrame({'T8':T8,'D8':D8}, index=pian[k].index))
fig,ax=plt.subplots(1,1)
y=x=[-1.5,-0.5,0, 1.5,2.5]
for i,_df in enumerate(D8T8):
ax.scatter(_df.D8, _df.T8, label='Q' + str(i+1)+
':'+str(count_list[i]))
# for row in range(4):
# for col in range(4):
# print (x[row], y[col])
# pos=row*col
# print(count_list[pos])
# ax.text(x,y, count_list[i])
ax.set_title('D8 - T8 map by cut:'+str(cut))
ax.legend()
xticks = [-2,-1. , 0. , 1. ,2]
ax.set_xticks(xticks)
ax.set_yticks(xticks)
ax.grid()