本地运行模式
1.将压缩包spark-3.0.0-bin-hadoop3.2.tgz上传到虚拟机中

2.上传完成后,解压缩到无中文无空格的目录当中
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz

3.解压完之后,重命名文件夹mv spark-3.0.0-bin-hadoop3.2/ spark-local

4.进入spark-local文件夹目录下使用命令bin/spark-shell进入命令行工具
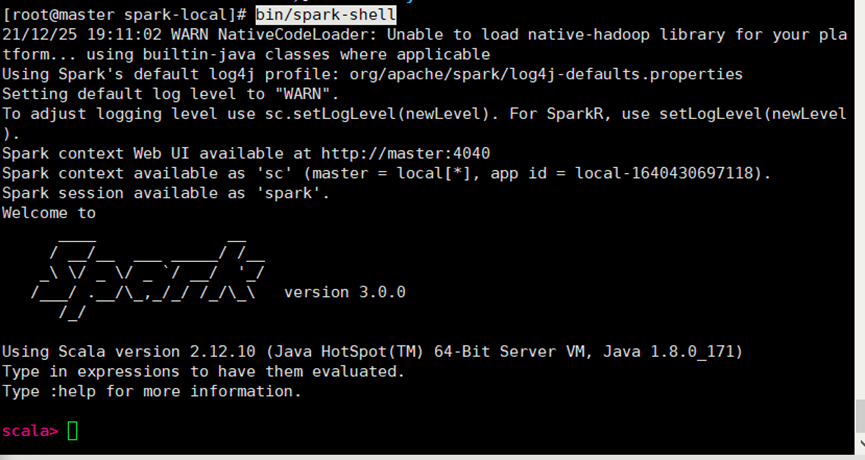
启动成功
5.此时就可以写spark的基本语法了
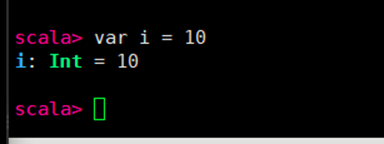
6.spark中预先准备了上下文环境对象‘sc’
7.在spark-local/data目录下创建一个新文件word.txt
Vim word.txt
写入
Hello Scala
Hello Spark
Hello Scala
保存并且退出
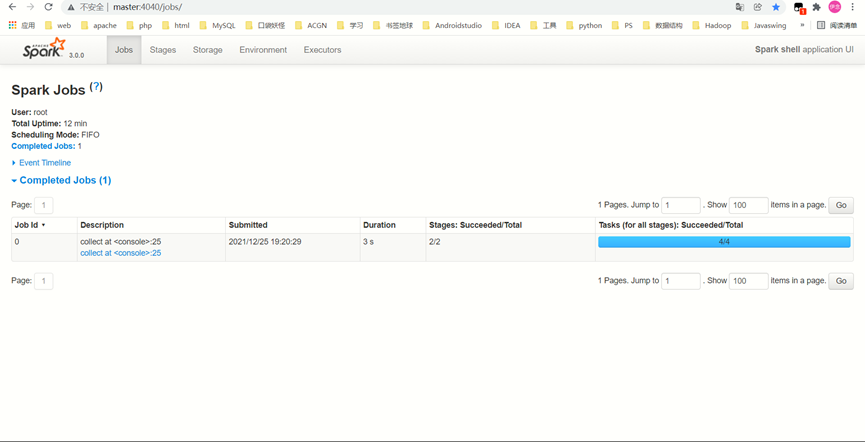
8.在spark命令行中输入
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
执行
结果

统计完成
当前本地环境配置OK
9.Spark中有一个监控页面

此处有提示,复制粘贴在网页中打开
10.退出本地模式
按键CTRL+C或者输入Scala指令:quit
注:开发环境中一般不适用本地模式
Standalone 模式
集群模式配置
local 本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的集群中去执行,这里我们来看看只使用 Spark 自身节点运行的集群模式,也就是我们所谓的 独立部署(Standalone)模式。Spark 的 Standalone 模式体现了经典的 master-slave 模式。 集群规划local 本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的 集群中去执行,这里我们来看看只使用 Spark 自身节点运行的集群模式,也就是我们所谓的 独立部署(Standalone)模式。Spark 的 Standalone 模式体现了经典的 master-slave 模式
1.解压缩
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz
2.重命名
mv spark-3.0.0-bin-hadoop3.2 spark-standalone

3.修改配置文件
进入解压缩后路径的 conf 目录,修改 slaves.template 文件名为 slaves
mv slaves.template slaves
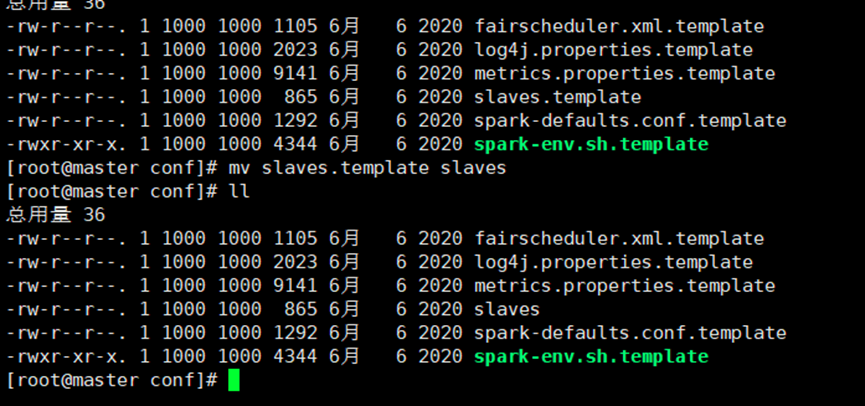
修改 slaves 文件,添加 work 节点 vim slaves
Master
C2
C3
修改 spark-env.sh.template 文件名为 spark-env.sh
mv spark-env.sh.template spark-env.sh

修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点
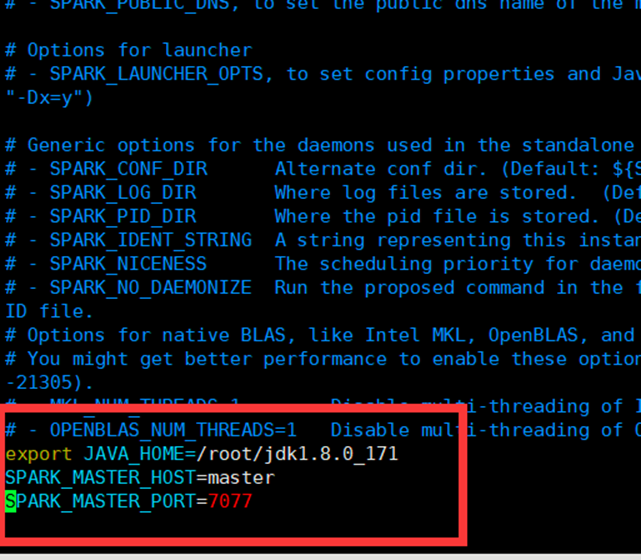
Java存放位置
主机名称
端口号,默认7077
注意:7077 端口,相当于 hadoop3 内部通信的 8020 端口,此处的端口需要确认自己的 Hadoop 配置
分发 spark-standalone 目录
xsync spark-standalone
(没有xsync需要自己配脚本)
4.启动集群
sbin/start-all.sh
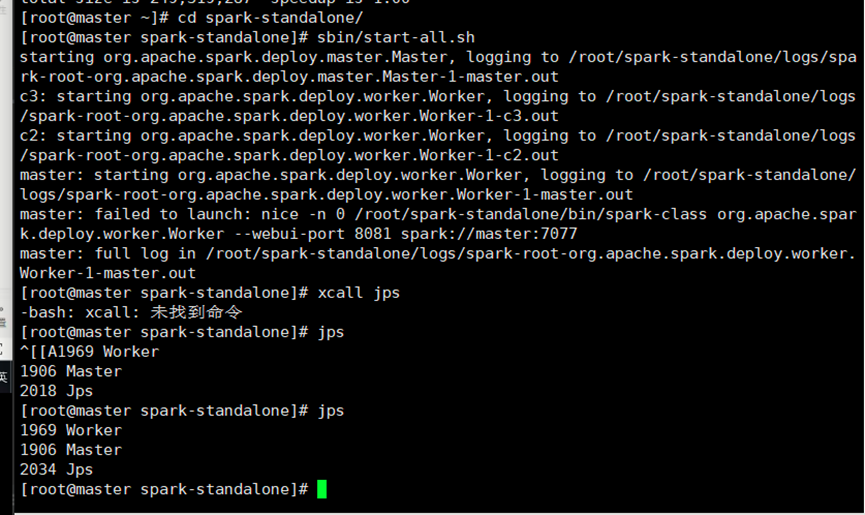
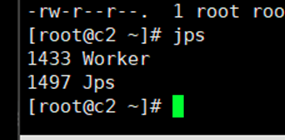
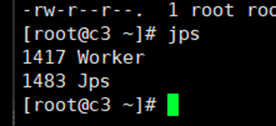
启动成功
5. 查看 Master 资源监控 Web UI 界面: http://master:8080

成功
6.提交应用程序
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10

集群环境OK
7.配置历史服务
1) 修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf
2) 修改 spark-default.conf 文件,配置日志存储路径
Vim
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:8020/directory

(需要提前打开Hadoop并且在hdfs中创建directory文件)
3) 修改 spark-env.sh 文件, 添加日志配
export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://master:8020/directory -Dspark.history.retainedApplications=30"


4) 分发配置文件 xsync conf
5) 重新启动集群和历史服务 sbin/start-all.sh sbin/start-history-server.sh
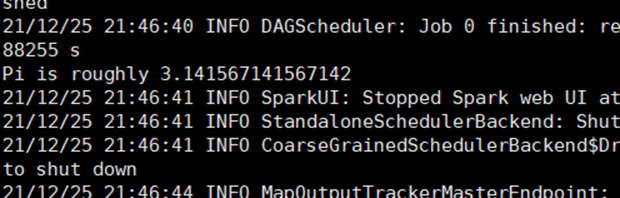
6) 重新执行任务
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
(我报错了,应该是端口号的原因我的是9000,但是没有改,这里的教程是8020所以出错了,在第一个配置中少打了一个/也报了错)
(修改之后还是有错误,查看了一下其它两个的conf发现多了一个文件,把多出来的重复文件删除掉,重新启动之后OK)
7) 查看历史服务:http://master:18080
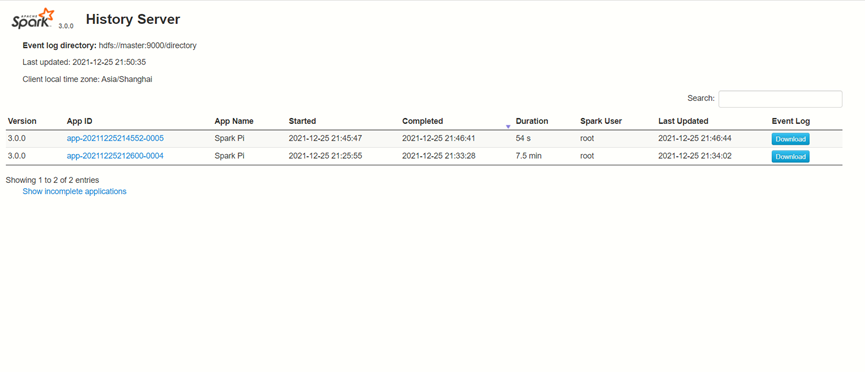
ok