需求缘起
产品第一版:用户有用户名、密码、昵称等三个属性,对应表设计:
user(uid, name, passwd, nick)
第二版,产品经理增加了年龄,性别两个属性,表结构可能要变成:
user(uid, name, passwd, nick, age, sex)
假设数据量和并发量比较大,怎么变?
(1)alter table add column?不太可行,锁表时间长
(2)新表+触发器?如果数据量太大,新表不一定装得下,何况触发器对数据库性能的影响比较高
(3)让dba来搞?新表,迁移数据,一致性校验,rename?dba真苦逼
今天分享2个列扩展性设计上几个小技巧,只占大伙1分钟(下班太晚的话,只能写一分钟系列=_=)
方案一:版本号+通用列
以上面的用户表为例,假设只有uid和name上有查询需求,表可以设计为
user(uid, name, version, ext)
(1)uid和name有查询需求,必须设计为单独的列并建立索引
(2)version是版本号字段,它对ext进行了版本解释
(3)ext采用可扩展的字符串协议载体,承载被查询的属性
例如,最开始上线的时候,版本为0,此时只有passwd和nick两个属性,那么数据为:

当产品经理需要扩展属性时,新数据将版本变为1,此时新增了age和sex两个数据,数据变为:

优点:
(1)可以随时动态扩展属性
(2)新旧两种数据可以同时存在
(3)迁移数据方便,写个小程序将旧版本ext的改为新版本的ext,并修改version
不足:
(1)ext里的字段无法建立索引
(2)ext里的key值有大量冗余,建议key短一些
改进:
(1)如果ext里的属性有索引需求,可能Nosql的如MongoDB会更适合
方案二:通过扩展行的方式来扩展属性
以上面的用户表为例,可以设计为
user(uid, key, value)
初期有name, passwd, nick三个属性,那么数据为:
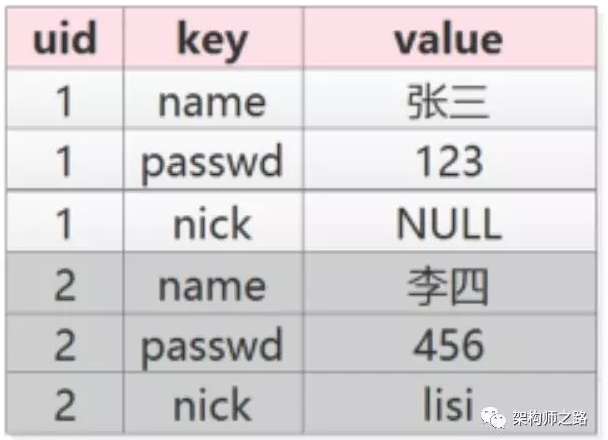
未来扩展了age和sex两个属性,数据变为:
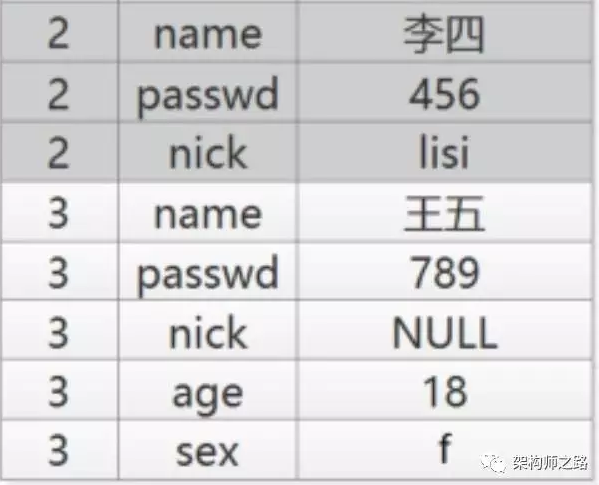
优点:
(1)可以随时动态扩展属性
(2)新旧两种数据可以同时存在
(3)迁移数据方便,写个小程序可以将新增的属性加上
(4)各个属性上都可以查询
不足:
(1)key值有大量冗余,建议key短一些
(2)本来一条记录很多属性,会变成多条记录,行数会增加很多
方案三:设计初期就为表预留自定义列
总结
可以通过“version+ext”或者“key+value”的方式来满足产品新增列的需求
转自: