CDH集群添加Kerberos并使用Java代码调用HDFS和Spark on YARN
0x0 背景
由于CDH默认的权限管理机制过于简单,不能够保证HADOOP集群的安全性,因此,引入了Kerberos作为安全管理服务。
0x1 安装kerberos服务
CDH提供了关于整合kerberos服务的向导,在整合kerberos之前,必须要有kerberos服务。下面,介绍一下如何安装kerberos服务。
1. 安装kerberos server和kdc(Key Distribution Center)
$ sudo apt-get install krb5-kdc krb5-admin-server
$ sudo dpkg-reconfigure krb5-kdc安装过程中会问你设置默认realm,一般设置域名大写,例如:
EXAMPL.COM2. 安装完成后,会生成一些配置文件,常用的如下:
默认的KDC配置文件路径: /etc/krb5kdc/kdc.conf
用户权限控制列表(ACL)路径:/etc/krb5kdc/kadm5.acl
还有krb配置:/etc/krb5.conf修改krb5.conf,添加刚才设置的realm对应的kdc和server的ip:
[realms]
HDSC.COM = {
kdc = 192.168.0.1
admin_server = 192.168.0.1
}然后修改kadm5.acl 文件,将acl列表设置如下:
# This file Is the access control list for krb5 administration.
# When this file is edited run /etc/init.d/krb5-admin-server restart to activate
# One common way to set up Kerberos administration is to allow any principal
# ending in /admin is given full administrative rights.
# To enable this, uncomment the following line:
*/admin *然后重启kerberos服务:
/etc/init.d/krb5-admin-server restart3. 接下来创建kerberos数据库:
sudo krb5_newrealm期间会让你输入密码,这个密码要记住。
当Kerberos database创建好后,可以看到目录 /var/kerberos/krb5kdc 下生成了许多新文件。如果想要删除重建,执行以下命令:
rm -rf /var/lib/krb5kdc/principal*
sudo krb5_newrealm4. 在maste服务器上创建admin/admin用户:
kadmin.local -q "addprinc admin/admin"然后就可以登录了:
kadmin -p admin/admin刚才在acl中设置了所有*/admin用户有管理员权限,该用户将来可以给CDH使用,Cloudera Manager将使用该管理员用户来创建其他相关的principal。
5. 常用的命令
#Add a user:
kadmin: addprinc user
#The default realm name is appended to the principal's name by default
#Delete a user:
kadmin: delprinc user
#List principals:
kadmin: listprincs
#Add a service:
kadmin: addprinc service/server.fqdn
#The default realm name is appended to the principal's name by default
#Delete a user:
kadmin: delprinc service/server.fqdn至此,Kerberos安装完毕。
0x2 CDH整合Kerberos
1. 首先,集群中各个节点还是需要一些必备的软件,官网给出下图:
笔者在ubuntu16.04下进行安装,执行以下命令:
在Cloudera Manager Server节点上:
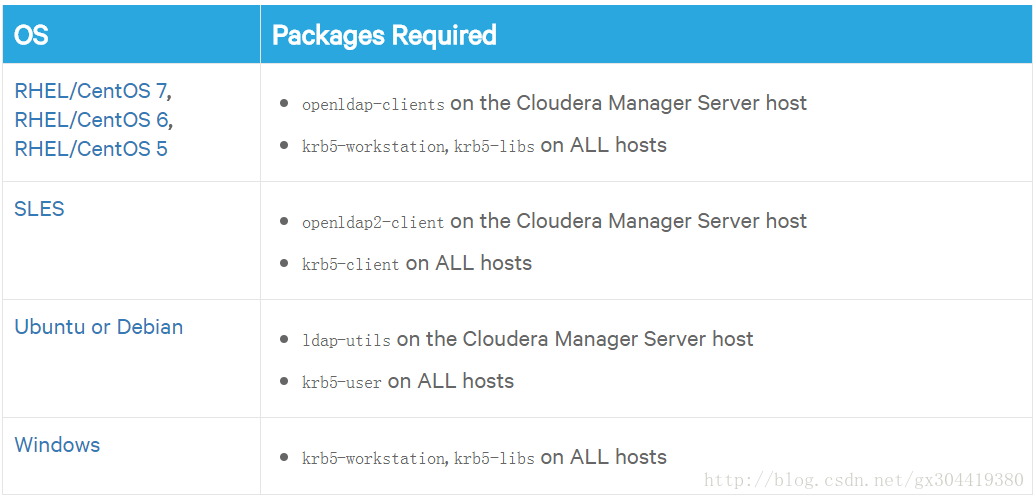
sudo apt-get install ldap-utils
sudo apt-get install krb5-user在Agent节点上:
sudo apt-get install krb5-user记得要修改/etc/krb5.conf,添加kerberos服务器的realm地址,例如:
[realms]
HDSC.COM = {
kdc = 192.168.0.1
admin_server = 192.168.0.1
}然后测试是否成功:
$ kinit admin/admin
Password for admin/admin@HDSC.COM:
$ klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: admin/admin@HDSC.COM
Valid starting Expires Service principal
04/12/2018 21:57:08 04/13/2018 07:57:08 krbtgt/HDSC.COM@HDSC.COM
renew until 04/13/2018 21:57:062. 关于AES-256加密
由于jdk8_161以下版本不支持aes-256加密,所以需要安装拓展包,或者干脆把aes-256加密给关闭掉。
关于安装扩展包,参看官方文档:
https://www.cloudera.com/documentation/enterprise/5-12-x/topics/cm_sg_s2_jce_policy.html
笔者采用另一种方式:关闭kerberos的aes-256加密。
打开kdc.conf配置文件:
vim /etc/krb5kdc/kdc.conf看到以下内容,修改其中的supported_enctypes,将aes256-cts:normal删除掉:
[kdcdefaults]
kdc_ports = 750,88
[realms]
HDSC.COM = {
database_name = /var/lib/krb5kdc/principal
admin_keytab = FILE:/etc/krb5kdc/kadm5.keytab
acl_file = /etc/krb5kdc/kadm5.acl
key_stash_file = /etc/krb5kdc/stash
kdc_ports = 750,88
max_life = 10h 0m 0s
max_renewable_life = 7d 0h 0m 0s
master_key_type = des3-hmac-sha1
supported_enctypes = aes256-cts:normal arcfour-hmac:normal des3-hmac-sha1:normal des-cbc-crc:normal des:normal des:v4 des:norealm des:onlyrealm des:afs3
default_principal_flags = +preauth
}然后重启kdc可kerberos-admin-server
/etc/init.d/krb5-kdc restart
/etc/init.d/krb5-admin-server restart但是,这时候出现了一些问题,客户端连不上了…
按照官方文档,需要重建kerberos数据库(参照上文所述),然后重启kdc和kerberos-admin-server,问题解决!
检查一下加密方式是否改变,可以在客户端主机上重新kinit以下,然后klist -e查看信息:
$ kinit admin/admin
$ klist -e如果输出如下,则说明aes-256关闭了:
Ticket cache: FILE:/tmp/krb5cc_800
Default principal: admin/admin@HDSC.COM
Valid starting Expires Service principal
04/13/2018 09:31:53 04/13/2018 19:31:53 krbtgt/HDSC.COM@HDSC.COM
renew until 04/14/2018 09:31:52, Etype (skey, tkt): des3-cbc-sha1, arcfour-hmac 如果没有关闭,输出类似下面,可见Etype中报刊AES-256:
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: test@Cloudera Manager
Valid starting Expires Service principal
05/19/11 13:25:04 05/20/11 13:25:04 krbtgt/Cloudera Manager@Cloudera Manager
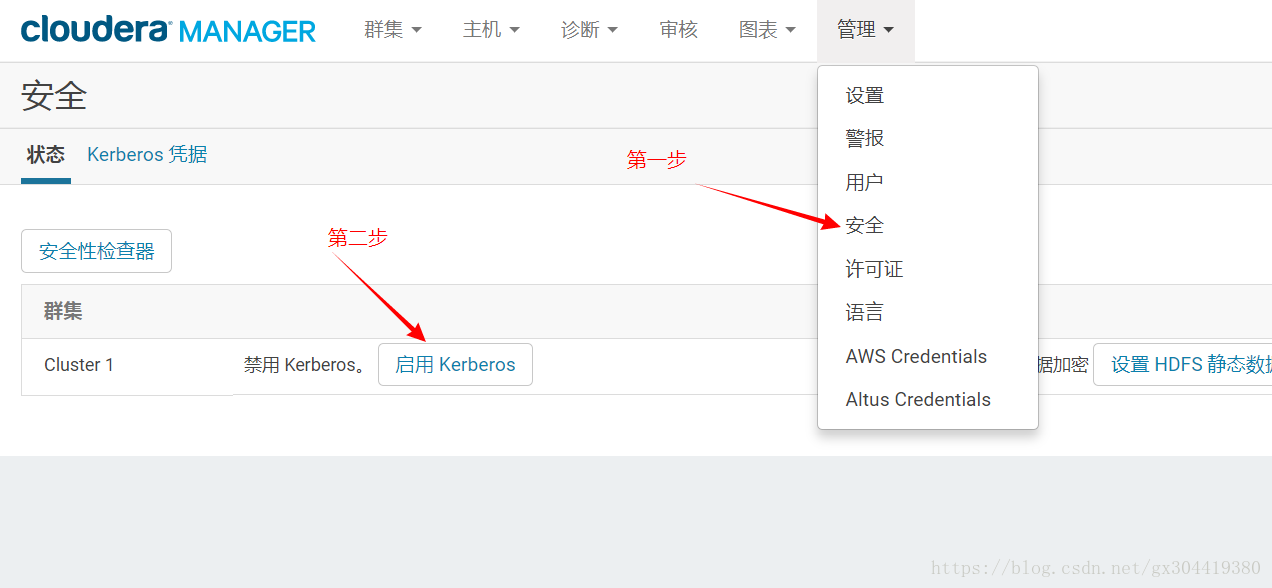
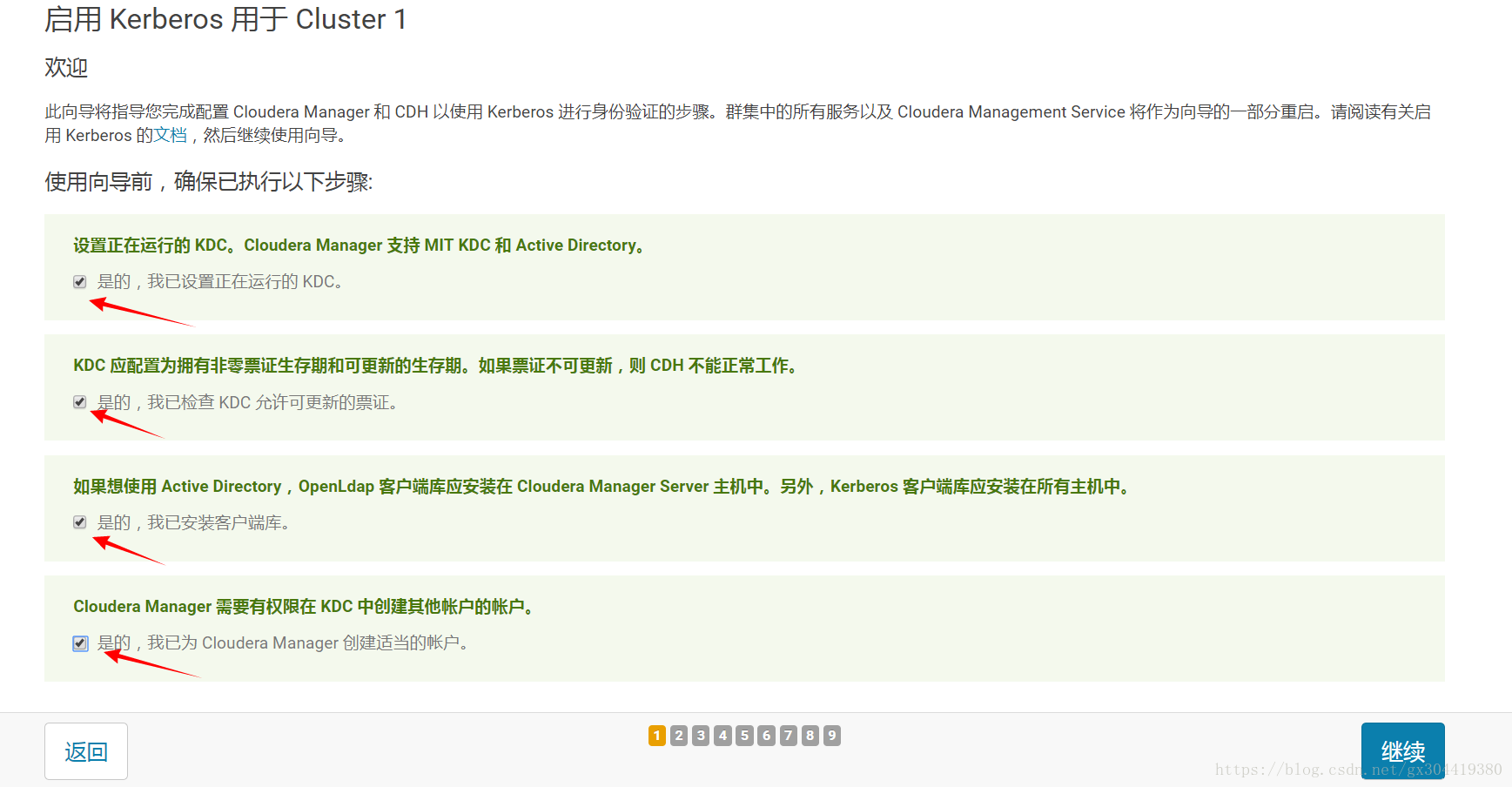
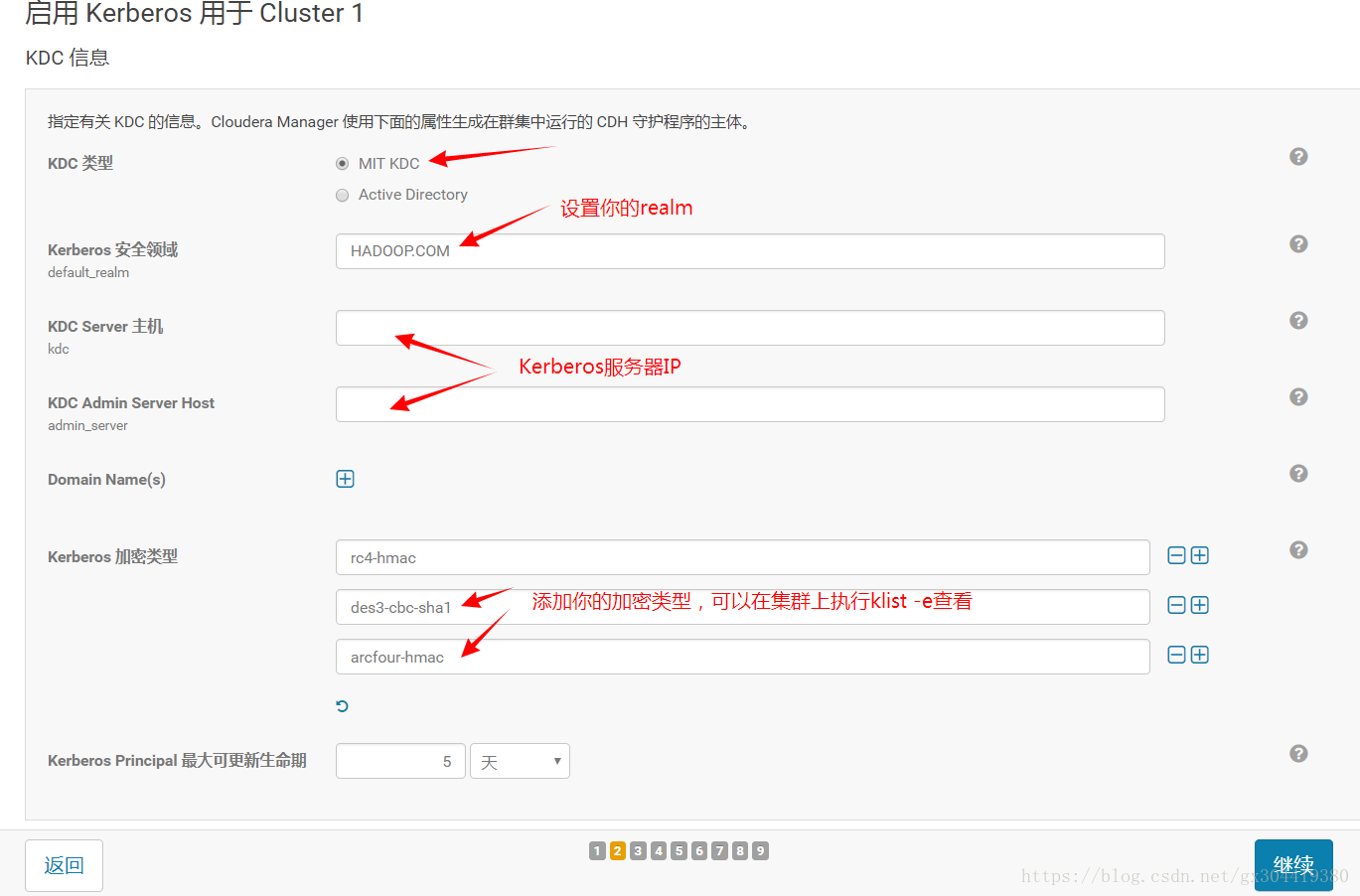
Etype (skey, tkt): AES-256 CTS mode with 96-bit SHA-1 HMAC, AES-256 CTS mode with 96-bit SHA-1 HMAC 3. 可以登录cloudera manager进行配置了
按下图顺序进行配置:
1.启用Kerberos
2.都打对勾
3.设置kdc相关属性
4.搞不懂,不点
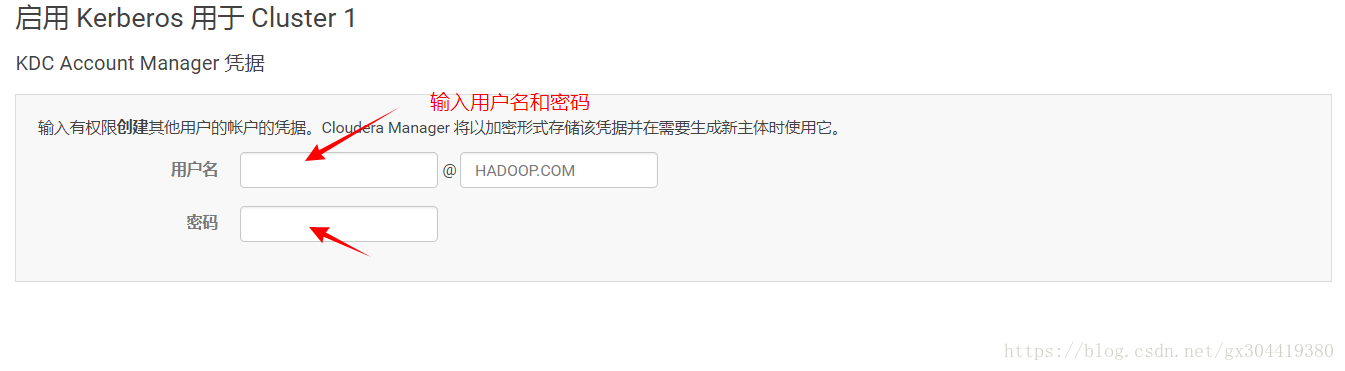
5.填写用户名密码
点击继续,就开始安装了。

0x3 开始使用
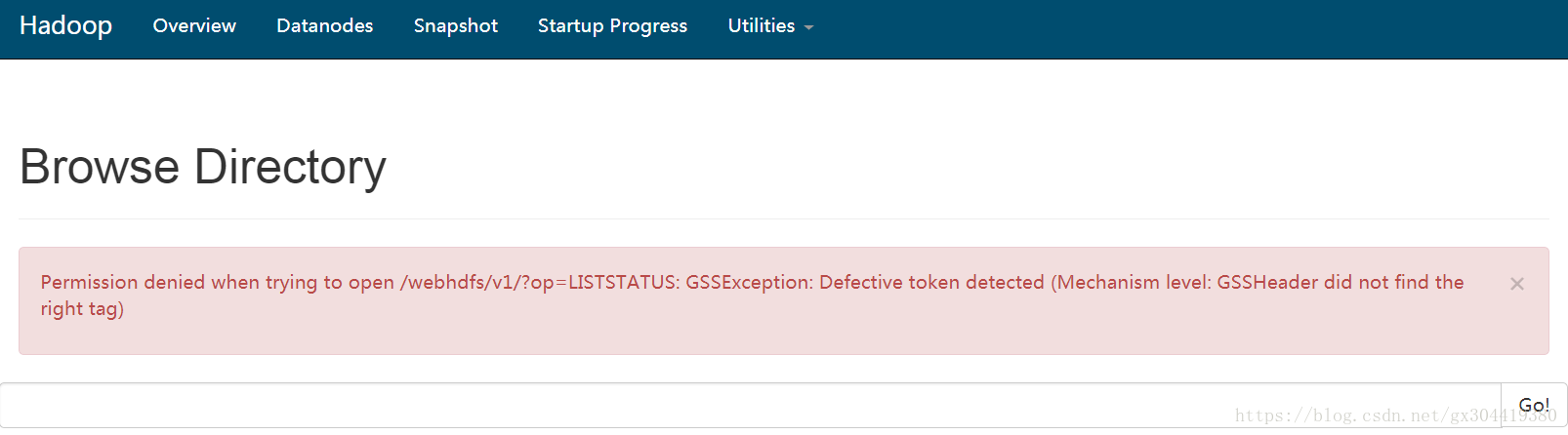
首先验证一下,我们的kerberos是否起作用。
最简单的方式就是登陆hdfs的web页面查看文件夹,你会发现无法访问了:
然后,我们在hadoop集群上,执行如下hadoop命令:
#先登陆Kerberos服务器,添加一个hdfs用户:
$ kadmin
Authenticating as principal admin/admin@HDSC.COM with password.
Password for admin/admin@HDSC.COM:
#添加一个叫做hdfs的用户(principal应该是hdfs@HDSC.COM)
kadmin: addprinc hdfs
#列出所有
kadmin: listprincs
#会看到,hdfs用户已经添加:
admin/admin@HDSC.COM
cloudera-scm/admin@HDSC.COM
hdfs/csut2hdfs115vl@HDSC.COM
hdfs/csut2hdfs116vl@HDSC.COM
hdfs/csut2hdfs117vl@HDSC.COM
hdfs/csut2hdfs118vl@HDSC.COM
hdfs@HDSC.COM
hive/csut2hdfs115vl@HDSC.COM
hue/csut2hdfs115vl@HDSC.COM
kadmin/admin@HDSC.COM
kadmin/changepw@HDSC.COM
kadmin/csut2hdfs115vl@HDSC.COM
kiprop/csut2hdfs115vl@HDSC.COM
krbtgt/HDSC.COM@HDSC.COM
mapred/csut2hdfs115vl@HDSC.COM
...
#退出kadmin
kadmin: exit
#然后设置hdfs为默认principal
$ kinit hdfs
Ticket cache: FILE:/tmp/krb5cc_800
Default principal: hdfs@HDSC.COM
Valid starting Expires Service principal
04/13/2018 15:50:31 04/14/2018 01:50:31 krbtgt/HDSC.COM@HDSC.COM
renew until 04/14/2018 15:50:29
#接下来我们就可以以hdfs用户来操作hadoop了
$ hadoop fs -ls /
Found 3 items
drwxr-xr-x - hdfs supergroup 0 2018-03-09 08:46 /opt
drwxrwxrwt - hdfs supergroup 0 2018-04-13 11:25 /tmp
drwxr-xr-x - hdfs supergroup 0 2018-04-13 15:15 /user
$ hadoop fs -mkdir /tmp/test01
$ hadoop fs -ls /tmp
Found 5 items
drwxrwxrwx - hdfs supergroup 0 2018-04-13 15:51 /tmp/.cloudera_health_monitoring_canary_files
drwxr-xr-x - yarn supergroup 0 2018-04-13 11:25 /tmp/hadoop-yarn
drwx-wx-wx - hive supergroup 0 2018-03-09 10:20 /tmp/hive
drwxrwxrwt - mapred hadoop 0 2018-04-13 11:25 /tmp/logs
drwxr-xr-x - hdfs supergroup 0 2018-04-13 15:52 /tmp/test01
#看来读写权限都有了0x4 JAVA代码调用HDFS
接下来看下在java中如何使用hdfs:
经过一番折腾,总结如下:
1. 要有keytab文件,也就类似于证书,下载到你本地。
生成方式是在kdc-server上执行命令:
kadmin: ktadd -k /opt/hdfs.keytab hdfs其中-k指定生成的keytab路径,hdfs是principal用户名。执行完成后,/opt目录会产生一个hdfs.keytab文件。值得注意的是,经测试,生成keytab文件后,hdfs就无法用密码登陆了!在客户端如果想登录,需要用以下命令:
$ kinit -kt /opt/hdfs.keytab hdfs2. 要有kerberos配置文件:/etc/krb5.conf,下载到你本地。
3. 要把hdfs-site.xml和core-site.xml下载到本地(/etc/hadoop/conf目录下)。
4. 我将以上四个文件放在D盘下,添加如下java代码:
(PS:其实,最好把hive-site、yarn-site、mapred-site…全放到本地resource目录下,最保险,而且代码也不用写太多)
//设置krb的配置文件路径到环境变量
System. setProperty("java.security.krb5.conf", "D:/krb5.conf" );
Configuration conf = new Configuration();
//添加hdfs-site.xml到conf
conf.addResource(new Path("D:/hdfs-site.xml"));
//添加core-site.xml到conf
conf.addResource(new Path("D:/core-site.xml"));
//设置hdfs的url
conf.set("fs.defaultFS", "hdfs://192.168.0.115:8020");
//登录
UserGroupInformation.setConfiguration(conf);
UserGroupInformation.loginUserFromKeytab("hdfs@HDSC.COM", "D:/krb5.keytab");
//获取FileSystem
FileSystem fs = FileSystem.get(conf);0x5 JAVA代码使用Spark访问HDFS
1. 同上一节所示,需要各种配置文件:
kerberos的证书文件和配置文件:keytab、krb5.conf
hadoop的全套配置:hive-site.xml、yarn-site.xml、mapred-site.xml、core-site.xml
2. maven依赖一定要和你的hadoop版本以及spark版本一致!
因为这个bug,找了3天没找到:
我是用的spark-yarn 2.1.0中依赖的hadoop-yarn-api版本为2.2.0,而我使用的hadoop版本是2.6.0,结果调用spark on yarn时总是出错,还没有相关日志输出,烦。
3. 上代码吧
记得要把spark目录下的/jars文件放到hdfs上,然后添加配置: .config("spark.yarn.archive", "hdfs://hdfs-host:port/user/spark/jars")
省的每次提交job都要把spark依赖的jar包上传到hdfs,可以提升效率。
//登录kerberos
System. setProperty("java.security.krb5.conf", "D:/krb5.conf");
UserGroupInformation.loginUserFromKeytab("hdfs@HDSC.COM", "D:/hdfs.keytab");
System.out.println(UserGroupInformation.getLoginUser());
//启动spark on yarn client模式
SparkSession spark = SparkSession.builder()
.master("yarn")
.config("spark.yarn.archive", "hdfs://192.168.0.115:8020/user/spark/jars")
// .master("local")
.appName("CarbonData")
.getOrCreate();
System.out.println("------------------------启动spark on yarn---------------------");
spark.read()
.textFile("hdfs://192.168.0.115:8020/opt/guoxiang/event_log_01.csv")
.show();0x6 Trouble Shoting
1. 用户id小于1000
异常信息:
main : run as user is hdfs
main : requested yarn user is hdfs
Requested user hdfs is not whitelisted and has id 986,which is below the minimum allowed 1000解决方法:
打开Cloudera Manager,选择Yarn->配置->min.user.id,将1000改为0。
2. Requested user hdfs is banned
main : run as user is hdfs
main : requested yarn user is hdfs
Requested user hdfs is banned解决方法:
打开Cloudera Manager,选择Yarn->配置->banned.users,将hdfs从黑名单删除。
3. 找不到文件/etc/hadoop/conf.cloudera.yarn/topology.py
错误信息:
WARN net.ScriptBasedMapping: Exception running /etc/hadoop/conf.cloudera.yarn/topology.py csut2hdfs117vl
java.io.IOException: Cannot run program "/etc/hadoop/conf.cloudera.yarn/topology.py" (in directory "D:workspacesparkapi"): CreateProcess error=2, 系统找不到指定的文件。
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1048)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:482)
at org.apache.hadoop.util.Shell.run(Shell.java:455)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:715)
at org.apache.hadoop.net.ScriptBasedMapping$RawScriptBasedMapping.runResolveCommand(ScriptBasedMapping.java:251)
at org.apache.hadoop.net.ScriptBasedMapping$RawScriptBasedMapping.resolve(ScriptBasedMapping.java:188)
at org.apache.hadoop.net.CachedDNSToSwitchMapping.resolve(CachedDNSToSwitchMapping.java:119)解决方法:
将core-site.xml中的
<property>
<name>net.topology.script.file.name</name>
<value>/etc/hadoop/conf.cloudera.yarn/topology.py</value>
</property>注释掉。
4. 无法实例化hive
错误信息:
Exception in thread "main" java.lang.IllegalArgumentException: Error while instantiating 'org.apache.spark.sql.hive.HiveExternalCatalog':
at org.apache.spark.sql.internal.SharedState$.org$apache$spark$sql$internal$SharedState$$reflect(SharedState.scala:169)
at org.apache.spark.sql.internal.SharedState.<init>(SharedState.scala:86)
at org.apache.spark.sql.CarbonSession$$anonfun$sharedState$1.apply(CarbonSession.scala:54)
at org.apache.spark.sql.CarbonSession$$anonfun$sharedState$1.apply(CarbonSession.scala:54)
......
Caused by: java.io.IOException: 拒绝访问。
at java.io.WinNTFileSystem.createFileExclusively(Native Method)
at java.io.File.createTempFile(File.java:2024)
at org.apache.hadoop.hive.ql.session.SessionState.createTempFile(SessionState.java:818)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:513)
... 35 more解决方法:
#执行本地hadoop下bin目录(window客户端):
winutil chmod -R 777 /tmp
#然后java代码中添加:
System.setProperty("HADOOP_USER_NAME", "hdfs");
System.setProperty("user.name", "hdfs");5. 集成carbondata注意事项
要把carbondata的jar包上传到hdfs://hdfs-host:port/user/spark/jars,这里路径自己设置,然后注意实例化spark-session的时候要配置:
.config("spark.yarn.archive", "hdfs://hdfs-host:port/user/spark/jars")6. 服务器端有无效的principal
异常信息
Server has invalid Kerberos principal: hdfs/cdevhdfs181vl@HDSC.COM其实这个异常是由于本地的dns解析导致的错误,把hosts文件中主机名和ip一一对应就好了。
7.
异常信息:
先报Netty连接异常:
Error sending result RpcResponse{requestId=5249573718471368854, body=NioManagedBuffer{buf=java.nio.HeapByteBuffer[pos=0 lim=47 cap=64]}} to /192.168.0.184:23386; closing connection
java.lang.AbstractMethodError: null
at io.netty.util.ReferenceCountUtil.touch(ReferenceCountUtil.java:77) ~[netty-all-4.1.23.Final.jar:4.1.23.Final]
at io.netty.channel.DefaultChannelPipeline.touch(DefaultChannelPipeline.java:116) ~[netty-all-4.1.23.Final.jar:4.1.23.Final]
at io.netty.channel.AbstractChannelHandlerContext.write(AbstractChannelHandlerContext.java:810) [netty-all-4.1.23.Final.jar:4.1.23.Final]
at io.netty.channel.AbstractChannelHandlerContext.write(AbstractChannelHandlerContext.java:723) [netty-all-4.1.23.Final.jar:4.1.23.Final]然后又报以下异常:
Diagnostics: Exception from container-launch.
Container id: container_1524019039260_0028_02_000001
Exit code: 10
Stack trace: ExitCodeException exitCode=10:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:601)
at org.apache.hadoop.util.Shell.run(Shell.java:504)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:786)
at org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor.launchContainer(LinuxContainerExecutor.java:373)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)进测试,发现是由于springboot项目中的netty-all和hadoop的netty-all版本有冲突导致的,在maven中锁定netty-all版本,使其同hadoop自带的netty-all版本一致即可。
找到一个很好的博文,推荐看这篇:
https://blog.csdn.net/u011026329/article/details/79167884
CDH安装kerberos官方文档:
https://www.cloudera.com/documentation/enterprise/5-12-x/topics/cm_sg_intro_kerb.html
Ubuntu安装kerberos官方文档:
https://help.ubuntu.com/community/Kerberos