定义
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。
函数可以嵌套
程序运行时,函数会先编译,调用时才执行
重名函数会使用最近的
定义函数
def 函数名(参数列表):
函数体
函数即变量的思想?
def cal():
print(cal)
print('this is in cal()')
return cal
# 这里将返回cal函数的内存地址
print(cal())
print(cal()())
输出结果如下
<function cal at 0x033807C8> this is in cal() <function cal at 0x033807C8> <function cal at 0x033807C8> this is in cal() <function cal at 0x033807C8> this is in cal() <function cal at 0x033807C8> [Finished in 0.1s]
参数传递
形参
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
位置实参
一一对应,多一不行缺一不行
关键字参数
无须一一对应,多一不行缺一不行。关键字参数必须在位置参数后面
默认参数
可变长参数
**字典 *列表
def test(x, *args):
print(args)
test(2, ['a','b','c'])
# (['a', 'b', 'c'],)
# [Finished in 0.9s]
test(2, *['a','b','c'])
# ('a', 'b', 'c')
# [Finished in 0.1s]
返回值
返回值数=0,返回None
返回值数=1,返回object
返回值数>1,返回tupel
局部变量和全局变量
global可以操作全局变量
nonlocal可以声明上一级同名变量
全局变量作用域是整个程序,局部变量作用域是定义该变量的子程序。
当全局变量与局部变量同名时:
在定义局部变量的子程序内,局部变量起作用;在其它地方全局变量起作用。
递归
递归特性:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
堆栈补充:https://www.cnblogs.com/lln7777/archive/2012/03/14/2396164.html
def cal(n):
print(n)
if int(n / 2) == 0:
return n
return cal(int(n/2))
print(cal(10))
def askway(name_list):
if len(name_list)==0:
return 'nobody know'
askname = name_list.pop()
if askname == 'c':
return 'c answer:在china'
print('%s do not konw, i will help you ask %s' % (askname,name_list))
return askway(name_list)
print(askway(name_list))
# 递归可以实现的,用for也可以实现
def func(start, end):
sum = 0
for i in range(start, end):
if i%3==0 and i%7==0:
sum += i
return sum
print(func(1,22))
# 递归实现
def func(start, end, a=0, sum=0):
"""根据指定范围获取其中 3 和 7 整除的所有数的和,并返回符合条件的数字个数和数字综合"""
if start == end:
return a,sum
if start%3==0 and start%7==0:
a += 1
sum += start
rec = func(start+1, end, a, sum)
return rec
print(func(1,22))
匿名函数
当我们在传入函数时,有些时候,不需要显式地定义函数,直接传入匿名函数更方便。
lambda 参数列表:返回值
匿名函数
lambda x:x+1
# 上方的匿名函数等价于下方的add_one()函数
def add_one(x):
return x+1
函数式编程
编程方式:面向过程、函数式编程、面向对象
函数式编程:函数式=编程语言定义的函数+数学意义的函数
函数式就是用编程语言去实现数学函数,这种函数内对象是永恒不变的,要么参数是函数,要么返回值是函数,没有for和while循环,所有的循环都由递归去实现,无变量的赋值(即不用变量去保存状态),无赋值即不改变
函数式编程的语言有:Hashell、clean、erlang
特点:
不可变数据:不使用变量保存状态,不修改变量
第一类对象:函数即变量。函数名可以当作参数传递;返回值也可以是函数名
尾调用:在函数的最后一步(不是最后一行)调用另一个函数
函数即变量
def cal():
print('this is in cal()')
return cal
# 这里将返回cal函数的内存地址
print(cal())
print(cal()())
# this is in cal()
# <function cal at 0x015A07C8>
# this is in cal()
# this is in cal()
# <function cal at 0x015A07C8>
# [Finished in 0.1s]
高阶函数
函数的参数是一个函数名或者返回值中包含参数
例如 map() filter() reduce()
# 把函数当作参数传递给另一个函数
def plant(name):
print(name)
def fruit(name):
print('my name is %s' % name)
plant(fruit('apple'))
# 返回值中包含函数名
def earth():
print('from earth')
return earth
earth()
earth()()
earth()()()
尾调用
尾调用的关键就是在函数的最后一步调用了函数,好处呢?根据函数即‘变量’的定义,定义a函数,a内调用函数b,b内调用函数c,在内存中会形成一个调用记录(又称为‘调用帧’ call frame),用于保存调用位置和内部变量等信息,即a→b→c,直到c返回结果给b,c的调用记录才会消失,b返回给a,b的调用记录消失,a返回结果,a的调用记录消失,所有的调用记录都是先进后出,形成了一个‘调用帧'
在函数a中对其他函数的调用不是a函数的最后一步,则会占用很大的内存,如果是最后一步,则不会占用过多内存
# 函数b在a内为尾调用
def b(n):
return n
def a(n):
return b(n)
# 函数b和c在a内均为尾调用,二者在if下具有可能成为函数a的最后一步
def c(n):
return n
def b(n):
return n+1
def a(n):
if type(n) is int:
return c(n)
else:
return b(n)
# 函数b在a内为非尾调用
def b(n):
return n
def a(n):
x = b(n)
return x
# 函数c在a内为非尾调用
def c(n):
return n
def a(n):
return c(n)+1
偏函数
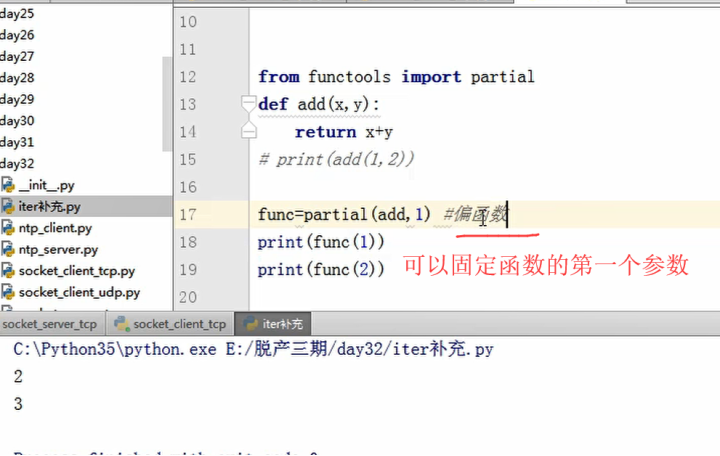
内置函数
bin()
print(bin(10)) #10进制->2进制 print(hex(12)) #10进制->16进制 print(oct(12)) #10进制->8进制 # 0b1010 # 0xc # 0o14
bool()
bool() 函数用于将给定参数转换为布尔类型,如果没有参数,返回 False。
bool 是 int 的子类。
bytes()
name = '你好'
print(bytes(name, encoding='utf-8'))
print(bytes(name, encoding='utf-8').decode('utf-8'))
# ascii不能编码中文
# print(bytes(name,encoding=ascii))
chr()
chr() 用一个范围在 range(256)内的(就是0~255)整数作参数,返回一个对应的字符。
返回值是当前整数对应的 ASCII 字符。
eval()
eval()可以提取字符串中的数据结果和表达式
dic = {'name':'alex'}
dic_str = str(dic)
print(type(dic_str))
print((eval(dic_str)))
print(type(eval(dic_str)))
print(eval('1+1*2'))
# <class 'str'>
# {'name': 'alex'}
# <class 'dict'>
# 3
filter()
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换
li_name = ['aliex', 'cn_liming', 'cn_xiaohong', 'ea_zhangsan']
def start_cn(name):
return name.startswith('cn')
def filter_test(fun, array):
list_test = []
for i in array:
if fun(i):
list_test.append(i)
return list_test
print(filter_test(start_cn, li_name))
print(filter_test(lambda a:a.startswith('ea'), li_name))
print('使用内置函数filter', filter(lambda x:x.startswith('cn'),li_name))
print('使用内置函数filter', list(filter(lambda x:x.startswith('cn'),li_name)))
hash()
hash() 用于获取取一个对象(字符串或者数值等)的哈希值。
可hash的数据类型即不可变数据类型,不可hash的数据类型即可变数据类型
hash() 函数的对象字符不管有多长,返回的 hash 值都是固定长度的,也用于校验程序在传输过程中是否被第三方(木马)修改,如果程序(字符)在传输过程中被修改hash值即发生变化,如果没有被修改,则 hash 值和原始的 hash 值吻合,只要验证 hash 值是否匹配即可验证程序是否带木马(病毒)。
在 hash() 对对象使用时,所得的结果不仅和对象的内容有关,还和对象的 id(),也就是内存地址有关。
print(hash('hello'))
print(hash('hello world'))
# -1495515718
# 973284469
help()
help() 函数用于查看函数或模块用途的详细说明
返回对象帮助信息
id()
id() 函数用于获取对象的内存地址
input()
Python3.x 中 input() 函数接受一个标准输入数据,返回为 string 类型。
int()
int() 函数用于将一个字符串或数字转换为整型。
返回整型数据。
type()
返回对象的类型
len()
返回对象(字符、列表、元组等)长度或项目个数
list()
list() 方法用于将元组转换为列表。
返回列表。
max()
max() 方法返回给定参数的最大值,参数可以为序列。
dic = {'alex':200, 'liming':400, 'bluce':100}
print(max(dic.values()))
# max处理的是可迭代对象,相当于一个for循环取出每个元素进行比较,注意,不同类型之间不能比较
#运行结果
#400
map()
map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
利用参数中提供的函数对每一个序列中的元素进行操作
语法
map(function, iterable, ...) function -- 函数 iterable -- 一个或多个序列 Python 2.x 返回列表。 Python 3.x 返回迭代器。
作用
def increase_one(num):
return num+1
def map_test(fuc, array):
'''自定义map函数'''
res = []
for i in array:
res.append(fuc(i))
return res
li_test = [1, 2, 3, 4, 5,]
print(map_test(increase_one, li_test))
print(map_test(lambda x:x**2, li_test))
print('使用内置函数map()', map(lambda x:x*82,li_test))
print('使用内置函数map()', list(map(lambda x:x*82,li_test)))
min()
min() 方法返回给定参数的最小值,参数可以为序列。
print()
print() 方法用于打印输出,最常见的一个函数。
无返回值
python3.x中实现print不换行:
print('contents', end=' ')
end就表示print将如何结束,默认为end=" "(换行)
# 在每个字符间插入相同的符号
print('root','0','0',sep=':')
# 运行结果如下:
# root:0:0
常用占位符
name= "张三"
age = 19
height = 180
print("我叫%s,今年%s岁,身高是%s" % (name,age,height))
print("我叫{},今年{}岁,身高是{}".format(name,age,height))
"""
占位符 整数占位 用%d
小数占位符 用 %.6d 保留几位为整数,位数不够 用0补齐,往前补
"""
a = "我的钱包余额是%.5d" % age
print(a)
#打印结果是:我的钱包余额是00019
a = "我的身高是%f米" % height
# print(a )
#打印结果是:我的身高是180.000000米(默认保留的小数)
#打印结果是b = "我的身高是%.2f米" % height
print(b)
#打印结果是:我的身高是180.00米
range()
range() 函数可创建一个整数列表,一般用在 for 循环中
python2
range立即创建
xrange for循环时创建
python3
range for循环时创建
reduce()
reduce() 函数会对参数序列中元素进行累积
nums = [1, 3, 100]
def reduce_test(func, nums, init=1):
if init is None:
res = nums.pop(0)
else:
res = init
for num in nums:
res = func(res, num)
return res
print(reduce_test(lambda x,y:x*y,nums))
print(reduce_test(lambda x,y:x*y,nums,init=2))
from functools import reduce
print('使用函数reduce', reduce(lambda x,y:x+y,nums,100))
sum()
sum() 方法对系列进行求和计算。
sotred()
dic = {'alex':200, 'liming':400, 'bluce':100}
# 默认对key进行排序
print(sorted(dic))
# 对values进行排序
print(sorted(dic.values()))
# 对values进行排序,并取出key
print(sorted(dic, key=lambda n:dic[n]))
print(sorted(zip(dic.values(), dic.keys())))
type()
type() 函数如果你只有第一个参数则返回对象的类型,三个参数返回新的类型对象
tuple()
tuple() 函数将列表转换为元组
zip()
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表
dic = {'alex':200, 'liming':400, 'bluce':100}
print(list(zip(dic.values(), dic.keys())))
l = list(zip(dic.values(), dic.keys()))
# zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
# 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
# 运行结果
# [(200, 'alex'), (400, 'liming'), (100, 'bluce')]
参考
菜鸟教程python3内置函数https://www.runoob.com/python3/python3-built-in-functions.html
https://www.cnblogs.com/linhaifeng/articles/6113086.html#_label2