There is a common principle that underlies all supervised machine learning algorithms for predictive modeling.
In this post you will discover how machine learning algorithms actually work by understanding the common principle that underlies all algorithms.
Let’s get started.
Learning a Function
Machine learning algorithms are described as learning a target function (f) that best maps input variables (X) to an output variable (Y).
Y = f(X)
This is a general learning task where we would like to make predictions in the future (Y) given new examples of input variables (X).
We don’t know what the function (f) looks like or it’s form. If we did, we would use it directly and we would not need to learn it from data using machine learning algorithms.
It is harder than you think. There is also error (e) that is independent of the input data (X).
Y = f(X) + e
This error might be error such as not having enough attributes to sufficiently characterize the best mapping from X to Y. This error is called irreducible error because no matter how good we get at estimating the target function (f), we cannot reduce this error.
This is to say, that the problem of learning a function from data is a difficult problem and this is the reason why the field of machine learning and machine learning algorithms exist.
Get your FREE Algorithms Mind Map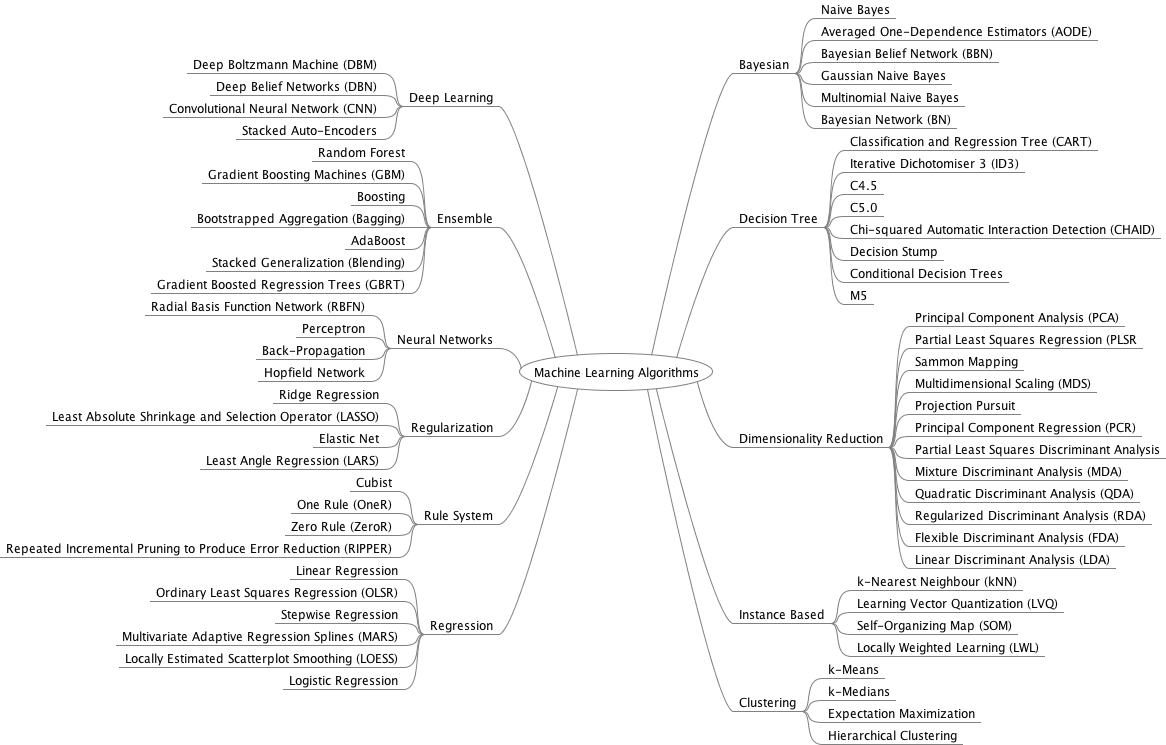
Learning a Function To Make Predictions
The most common type of machine learning is to learn the mapping Y=f(X) to make predictions of Y for new X.
This is called predictive modeling or predictive analytics and our goal is to make the most accurate predictions possible.
As such, we are not really interested in the shape and form of the function (f) that we are learning, only that it makes accurate predictions.
We could learn the mapping of Y=f(X) to learn more about the relationship in the data and this is called statistical inference. If this were the goal, we would use simpler methods and value understanding the learned model and form of (f) above making accurate predictions.
When we learn a function (f) we are estimating its form from the data that we have available. As such, this estimate will have error. It will not be a perfect estimate for the underlying hypothetical best mapping from Y given X.
Much time in applied machine learning is spent attempting to improve the estimate of the underlying function and in term improve the performance of the predictions made by the model.
Techniques For Learning a Function
Machine learning algorithms are techniques for estimating the target function (f) to predict the output variable (Y) given input variables (X).
Different representations make different assumptions about the form of the function being learned, such as whether it is linear or nonlinear.
Different machine learning algorithms make different assumptions about the shape and structure of the function and how best to optimize a representation to approximate it.
This is why it is so important to try a suite of different algorithms on a machine learning problem, because we cannot know before hand which approach will be best at estimating the structure of the underlying function we are trying to approximate.
Summary
In this post you discovered the underlying principle that explains the objective of all machine learning algorithms for predictive modeling.
You learned that machine learning algorithms work to estimate the mapping function (f) of output variables (Y) given input variables (X), or Y=f(X).
You also learned that different machine learning algorithms make different assumptions about the form of the underlying function. And that when we don’t know much about the form of the target function we must try a suite of different algorithms to see what works best.