一:三级菜单
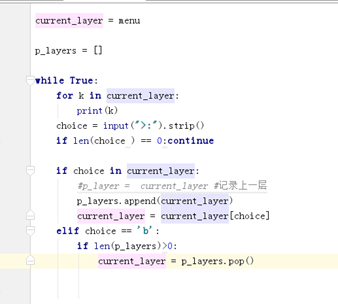
If len(choice) == continue # 判断输入的是否为空,为空就跳出这次循环进行下次循环, exit(“bye”) :退出程序显示,bye
二:编码
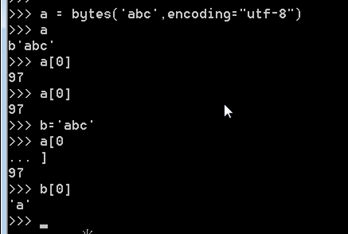
最早的编码是assic码,其次是gb2312,6700个汉字,gbk 1995年支持21000个汉字
1991年出现unicode 32 = 4字节,优化为unicode 16 = 4字节 再次优化,UTF-8
Python2.x 支持是assic码,因为Python是 1989年出现的,所以在python2.x中需要输入
#-*- conding:utf-8 -*- :意思是告诉py解释器,我后面的代码使用UTF-8解释
在python3.x中,默认使用utf-8解读

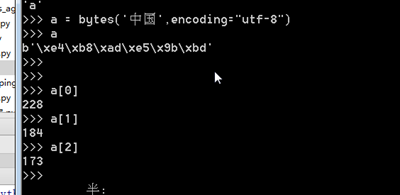
因为各个国家都有自己的编码格式,各个国家都是用自己的编码,导致其他国家无法使用他国的编码,所以需要一个转码器,如日本编码,与中国的GBK编码,解释器就是找一个我们两个编码都可以实现的编码 unicode ,先将日本编码转换为unicode,在到中国系统中,将转换成unicode的编码,在次转换成GHK即可
日本编码 到 Unicode 到 GBK

解码,python2.x:

Gb2314向下兼容gbk,gbk不向上兼容
Windows默认编码GBK,windows支持unicode 和gbk
解码,python3.x:
Python3解释器,默认就是unicode的,也就是,每次进入内存后会将utf-8 编回unicode,
就是,python3 文件格式是utf-8,但是使用 unicode 在内存中跑的,
Python3.x 默认文件编码就是 UTF-8
解释器编码是,unicode,文件加载到内存后会自动转换成Unicode ,同时,把字符转换成bytes
Bytes = 8bits ,他就是二进制格式
因此,看的时候不需要转换格式,但是保存时需要注意保存格式,否则会出现乱码
Python2 str == python3 bytes # python2 的bytes就是 字符串
Python3 str == Unicode # python3 的bytes就是Unicode
Python3 多出来的那个bytes格式就是一个单独的数据类型
(str意思是字符串)
Python2 在windows上解码是必须的,但是编码成gbk不是必须的
Python2 在Linux(默认是utf-8),如果是 gbk –> utf-8 解码是必须的,但是编码成gbk不是必须的
所有程序在内存中默认都是 Unicode ,只有在保存数据时需要进行编码
2):编码的使用
(1):爬虫
使用爬虫爬网站的话,因为编码格式不同,所以需要进行编码
三:文件处理
1:打开文件的模式有:
r,只读模式(默认)。
w,只写模式。【不可读;不存在则创建;存在则删除内容;】
a,追加模式。【可读;不存在则创建;存在则只追加内容;】
2:"+" 表示可以同时读写某个文件
r+,可读写文件。【可读;可写;可追加】
w+,写读
a+,同a
2.1:"U"表示在读取时,可以将 自动转换成 (与 r 或 r+ 模式同使用)
rU
r+U
2.2:"b"(就是前面的bytes)表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
rb :以二进制打开文件,不能声明encoding
wb :以二进制写文件,必须写入bytes格式
ab
//* 使用时不需要 encoding改格式,因为他根本不会进行解码与编码
一般用于网络传输
3:文件处理
Open() # encoding 不声明的话,默认使用系统的编码格式
r+ # 追加 + 读 + 定长修该,从开头加,但是覆盖源文件字符
a+ #追加 + 读,从结尾加
4:命令
read():读取文件所有内容
open():打开问文件
print(”cursor”,f.tell())光标所在位置
f.seek(10):代表移动10个字节
f.read(6):带便读取6个字节

f.write() #从贯标所在写入字符,在使用wb时就必须加上制定编码

f.truncate(100) # 从开头开始截取100个
f.flush() # 强制将内存中的要写入的数据,写入硬盘 //* 一般用于日志的实时写入
四:集合:
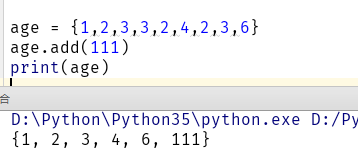
1:集合的第一个作用:天生去重,不排序,通过哈希算法实现的

命令:
2:集合的第二个作用:关系运算

a = {1,3,5,7,10}
b = {2,3,4,5,6}
# 1,取交集
print(a&b)
print(a.intersection(b))
print(a.intersection_update(b)) # 相当于:a = a.intersection(b)
print("1:==========")
# 2,取差集
print(b-a)
print(b.difference(a))
print(a-b)
print(a.difference(b))
print("2:==========")
# 3,取并集
print(a|b)
print(a.union(b))
print("3:==========")
# 4,对称差集(项在a或b中,但不会同时出现在二者中)
print(a^b)
print(a.symmetric_difference(b))
print("4:==========")
print(a.isdisjoint(b))
print(a.issubset(b))
结果:
{3, 5}
{3, 5}
None
1:==========
{2, 4, 6}
{2, 4, 6}
set()
set()
2:==========
{2, 3, 4, 5, 6}
{2, 3, 4, 5, 6}
3:==========
{2, 4, 6}
{2, 4, 6}
4:==========
False
True
五:函数

函数就是,将重复的代码,提取出来定义一个名字,以供后面调用
2):特点
1:较少减少重复代码
2:使程序变的可扩展
3:使程序变得易维护
3):基础函数模式

4):语法
Return #1:将函数得返回结果返回给函数外面
2:return:的作用是,结束函数,遇到就不想下走了,
3:代表海曙的结束,返回值

5):函数参数与局部变量
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参:有确定的值的参数,所有的数据类型都可以当做实参
形参:只有在被函数调用时,才分配内存,调用结束后立刻解放内存,值仅在函数内部使用(局部变量,形参的作用域只在当前函数内部有效)

局部变量:作用域只在当前函数内部,外部变量默认不能被函数内部修改,只能引用
//* 在函数变量中修改全局变量,必须使用 global 函数,但是强烈不建议这么干
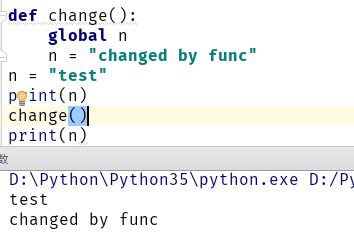
=======================================
函数内部是可以需改,列表,字典,集合,实例

列表的id 是不会变得,只有列表中的 id 值可以改变
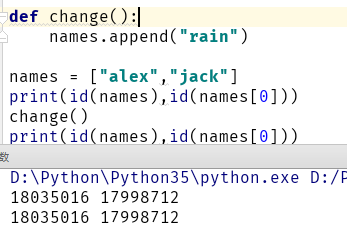
6):默认参数
1:设置默认参数
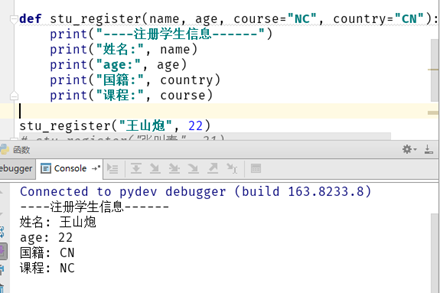
2:关键参数
正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可,但记住一个要求就是,关键参数必须放在位置参数之后。
stu_register(age=22,name='alex',course="python",)
//* courcse就是关键参数
3: 非固定参数
若你的函数在定义时不确定用户想传入多少个参数,就可以使用非固定参数
|
def stu_register(name,age,*args): # *args 会把多传入的参数变成一个元组形式 print(name,age,args)
stu_register("Alex",22) #输出 #Alex 22 () #后面这个()就是args,只是因为没传值,所以为空
stu_register("Jack",32,"CN","Python") #输出 # Jack 32 ('CN', 'Python') |
|
还可以有一个**kwargs |
|
def stu_register(name,age,*args,**kwargs): # *kwargs 会把多传入的参数变成一个dict形式 print(name,age,args,kwargs)
stu_register("Alex",22) #输出 #Alex 22 () {}#后面这个{}就是kwargs,只是因为没传值,所以为空
stu_register("Jack",32,"CN","Python",sex="Male",province="ShanDong") #输出 # Jack 32 ('CN', 'Python') {'province': 'ShanDong', 'sex': 'Male'}
|
4:参数总结:
位置参数,按顺序
默认参数,必须放在位置参数的后面
关键参数,同上
非固定参数,*args = () 以位置参数的形式传入,**kwargs = {} 以关键参数的形式传入
def函数支持所有函数,包括他自己,所调用函数是指,把一个函数的内存地址传给另一个函数,函数中夹杂函数就叫做高阶函数
六:递归
递归层数最多到达999层,因为进入函数,每次进入一个def 中的嵌套函数,上层函数都没有退出,所以开的def 函数层数越多那么占用内存就越大,所以需要,限制函数的嵌套层数
//* data = range(1,50):显示1,50
七:匿名函数
匿名函数最复杂的运算就是三元运算。
八:高阶函数
def函数支持所有函数,包括他自己,所调用函数是指,把一个函数的内存地址传给另一个函数,函数中夹杂函数就叫做高阶函数

//* abs() :就是将数的绝对值
高阶函数:特点
1:把一个函数的内存地址当做参数传给另一个函数
2:一个函数 把另外的一个函数当做返回值返回