C++原子库中仅保证atomic_flag是保证无锁的,而atomic< int>,atomic< bool>不是
#ifndef _SPINLOCK_H_20170410_ #define _SPINLOCK_H_20170410_ #include <atomic> class spinlock { public: spinlock() { m_lock.clear(); } spinlock(const spinlock&) = delete; ~spinlock() = default; void lock() { while (m_lock.test_and_set(std::memory_order_acquire)); } bool try_lock() { return !m_lock.test_and_set(std::memory_order_acquire); } void unlock() { m_lock.clear(std::memory_order_release); } private: std::atomic_flag m_lock; }; #endif//_SPINLOCK_H_20170410_
root@ubuntu:~/c++# cat spinlock.cpp #include "spinlock.h" #include <mutex> #include <future> #include <iostream> #include <map> spinlock lock; int value = 0; int loop(bool inc, int limit) { std::cout << "Started " << inc << " " << limit << std::endl; for (int i = 0; i < limit; ++i) { std::unique_lock<spinlock> _lock(lock); if (inc) ++value; else --value; } return 0; } int main() { auto f = std::async(std::launch::async, std::bind(loop, true, 20000000)); loop(false, 10000000); f.wait(); std::cout << value << std::endl; }
root@ubuntu:~/c++# g++ -std=c++11 -pthread spinlock.cpp -o spin root@ubuntu:~/c++# ./spin Started Started 0 100000001 20000000 10000000
原子数据类型/atomic类型
让我们先来看一下atomic模板类:
template <class T> struct atomic //example #include<atomic> void test() { std::atomic_int nThreadData; // std::atomic_int <----> std::atomic<int> nThreadData = 10; nThreadData.store(10); //TODO: use nThreadData here; }
对于内置型数据类型,C11和C++11标准中都已经提供了实例化原子类型,如下表所示:
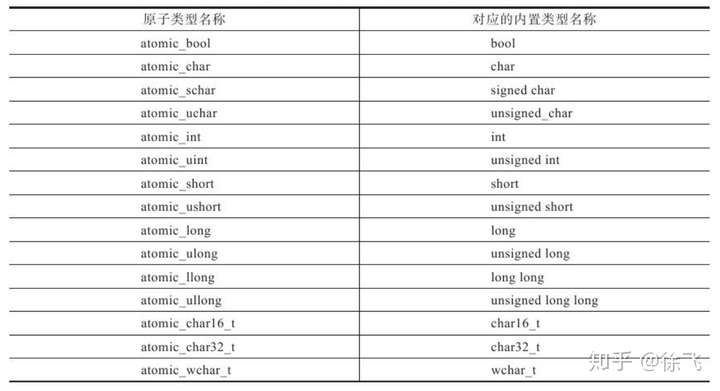 表#1
表#1
atomic类型原子操作接口如下:

内存模型
通常情况下,内存模型是一个硬件上的概念,表示的是机器指令(或者将其视为汇编指令也可以)是以什么样的顺序被处理器执行的。现代的处理器并不是逐条处理机器指令的。
#include <thread> #include <atomic> #include <iostream> using namespace std; atomic<int> a{0}; atomic<int> b{0}; int ValueSet(int) { int t=1; a=t; b=2; return 0; }
平淡无奇的代码。指令“t=1;a=t;b=2”,其伪汇编代码如下:

按照通常的理解,指令总是按照1->2->3->4->5顺序执行的,如果处理器是按照这个顺序执行的,我们称这样的内存模型为强顺序的(strong ordered)。 这种执行方式下,指令3总是先于指令5执行,即a赋值在前,b赋值在后。
但是指令1、2、3(a赋值)和指令4、5(b赋值)毫不相干。一些处理器可能将指令乱序执行,比如按照1->4->2->5->3这样的顺序(超标量流水线,即一个时钟周期里发射多条指令)。如果指令是“乱序”执行的,我们称这样的内存模型为弱顺序的(weak ordered)。这种执行方式下,指令5可能先于指令3被执行,即可能b赋值在前,a赋值在后。
弱顺序的内存模型的好处在哪里?可以进一步挖掘指令中的并行性,提高指令执行的性能。
在单线程程序中,我管你内存模型是强顺序的还是弱顺序的,管你是顺序执行还是乱序执行的,反正最终结果是a等于1,b等于2。
但是在多线程情况下,“乱序”执行可能就会造成问题。
书1 - 203页,代码清单 6-21
root@ubuntu:~/c++# cat atomic9.cpp #include <thread> #include <atomic> #include <iostream> using namespace std; atomic<int> a{0}; atomic<int> b{0}; int ValueSet(int) { int t=1; a=t; b=2; } int Observer(int) { cout<<"("<<a<<","<<b<<")"<<endl;//可能有多种输出 } int main() { thread t1(ValueSet,0); thread t2(Observer,0); t1.join(); t2.join(); cout<<"Got("<<a<<","<<b<<")"<<endl;//Got(1,2) }
root@ubuntu:~/c++# g++ -std=c++11 atomic9.cpp -o atom -pthread root@ubuntu:~/c++# ./atom (1,2) Got(1,2)
线程Observer只是试图一窥线程ValueSet的执行情况,就看看而已,所以无论ValueSet的代码是顺序执行的还是乱序执行的,都无所谓,无非就是a,b输出值的顺序可能是(0,0),或者(1,2),或者(1,0),甚至(0,2),但是最终的输出结果都是(1,2)。
通常情况下,如果编译器认定a、b的赋值语句的执行先后顺序对输出结果没有任何的影响的话,则可以依情况将指令重排序(reorder)以提高性能。而如果a、b赋值语句的执行顺序必须是a先b后,则编译器则不会执行这样的优化。
试想一下,如果Observer里的操作结果严重依赖于ValueSet中指令的执行顺序,会怎么样?代码字面上的执行顺序都可能被打乱了,Observer不出问题才怪!
你一会想顺序执行,一会又想“乱序”执行,更有甚者,还想对“乱”的程度分等级……如何提供这种灵活性呢?
在C++11标准中,设计者给出的解决方式是让程序员为原子操作指定所谓的内存顺序:memory_order。
root@ubuntu:~/c++# g++ -std=c++11 atomic9.cpp -o atom -pthread root@ubuntu:~/c++# ./atom (1,2) Got(1,2) root@ubuntu:~/c++# cat atomic9.cpp #include <thread> #include <atomic> #include <iostream> using namespace std; atomic<int> a{0}; atomic<int> b{0}; int ValueSet(int) { int t=1; a.store(t,memory_order_relaxed); b.store(2,memory_order_relaxed); } int Observer(int) { cout<<"("<<a<<","<<b<<")"<<endl;//可能有多种输出 } int main() { thread t1(ValueSet,0); thread t2(Observer,0); t1.join(); t2.join(); cout<<"Got("<<a<<","<<b<<")"<<endl;//Got(1,2) }
注意memory_order_relaxed的使用,其实际意义后面再解释。对原子类型而言,赋值“=”和调用store接口函数,作用都是一样的,只不过,除了要写入的值外,store还接受另外一个名为memory_order的枚举值。来看下std::atomic<T>::store接口的定义:
void atomic<T>::store( T desired, std::memory_order order = std::memory_order_seq_cst ) volatile noexcept;
memory_order参数的默认值是std::memory_order_seq_cst。实际上,atomic类型的其他原子操作接口都有memory_order这个参数,而且默认值都是std::memory_order_seq_cst。
枚举memory_order如下:
typedef enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
} memory_order;memory_order的各个枚举值的定义规则如下:
 表#3
表#3
让我们来逐一检视这些枚举值的意义。
顺序一致内存顺序/memory_order_seq_cst
定义规则:全部存取都按照顺序执行。
memory_order_seq_cst 表示该原子操作必须顺序一致的,这是C++11中所有atomic原子操作的默认值。这样来理解“顺序一致”:即代码在线程中运行的顺序与程序员看到的代码顺序一致。也就是说,用此值提示编译器“不要给我重排序指令,不要整什么指令乱序执行,就按照我代码的先后顺序执行机器指令”。在示例代码中,a的赋值语句先于b的赋值语句执行,这种称之为”先于发生(happens-before)“关系。用memory_order_seq_cst 可以确保这种happens_before关系。
松散内存顺序/memory_order_relaxed
定义规则:不对执行顺序做任何保证。
表示该原子操作指令可以任由编译器重排或者由处理器乱序执行。就是说”想怎么乱就怎么乱吧,不管了,只要能提高指令执行效率“。代码清单6-23中使用的就是松散内存模型,在Observer中打印出(0,2)这样的结果也是合理的——把我代码中的顺序都彻底整反了!
root@ubuntu:~/c++# cat atomic9.cpp #include <thread> #include <atomic> #include <iostream> using namespace std; atomic<int> a{0}; atomic<int> b{0}; int ValueSet(int) { int t=1; a.store(t,memory_order_relaxed); b.store(2,memory_order_relaxed); } int Observer(int) { while(b.load(memory_order_relaxed)!=2);//自旋等待 cout<<a.load(memory_order_relaxed)<<endl; } int main() { thread t1(ValueSet,0); thread t2(Observer,0); t1.join(); t2.join(); cout<<"Got("<<a<<","<<b<<")"<<endl;//Got(1,2) } root@ubuntu:~/c++# g++ -std=c++11 atomic9.cpp -o atom -pthread root@ubuntu:~/c++# ./atom 1 Got(1,2) root@ubuntu:~/c++#
上述代码中,我们用memory_order_relaxed的初衷是不希望完全禁用原子类型的优化。”自旋等待“那行代码的真实用意是:先自旋等待b被赋值为2,随后再将a的值输出。但是按照松散内存顺序,a.store 和 b.store指令的先后顺序不能保证了,b.store可能先被执行,因此a的输出值可能是0,也可能是1。 这些不是代码作者想要的。
Release-acquire内存顺序
memory_order__acquire
规则定义:本线程中,所有后续的读操作,必须在本条原子操作完成后执行。(本线程中,我先读,你们后读……)
memory_order_release
规则定义:本线程中,所有之前的写操作完成后,才能执行本原子操作。(在本线程中,你们先写,我最后写……)
上面讲的顺序一致和松散方式对应着两个极端——一个是严格禁止”乱“,一个是允许随便”乱“。但是现实的问题是:严格禁止”乱“,指令执行不够快;允许随便”乱“,又得不到正确结果。
”能搞组合贷不?“
root@ubuntu:~/c++# g++ -std=c++11 atomic9.cpp -o atom -pthread root@ubuntu:~/c++# ./atom 1 Got(1,2) root@ubuntu:~/c++# cat atomic9.cpp #include <thread> #include <atomic> #include <iostream> using namespace std; atomic<int> a{0}; atomic<int> b{0}; int ValueSet(int) { int t=1; a.store(t,memory_order_relaxed); b.store(2,memory_order_release);//本原子操作前所有的写原子操作必须完成 } int Observer(int) { while(b.load(memory_order_acquire)!=2);////本原子操作必须完成才能执行之后所有的读原子操作 cout<<a.load(memory_order_relaxed)<<endl; } int main() { thread t1(ValueSet,0); thread t2(Observer,0); t1.join(); t2.join(); cout<<"Got("<<a<<","<<b<<")"<<endl;//Got(1,2) } root@ubuntu:~/c++#
注意:Thread1中,b.store采用了memory_order_release内存顺序,保证了本线程中,本算子操作前的所有写操作都必须完成,也即a.store必须发生于b.store之前。在Thread2中,b.load采用了memory_order__acquire内存顺序,保证了本线程中,本原子操作必须先完成,才能执行之后所有的读原子操作,即b.load必须先于a.load执行。
Release-consume内存顺序
memory_order_consume
规则定义:本线程中,所有后续的有关本数据的操作,必须在本条原子操作完成之后执行。(本线程中,我只关心我自己,当我用memory_order_consume时,后面所有对我的读写操作都不能被提前执行……)
相比于memory_order__acquire,memory_order_consume进一步放松了依赖关系。大家发现没有,前面讲的几种内存顺序都是在操控/安排多个atomic数据之间的读写顺序,而memory_order_consume仅仅考虑对一个atomic数据的读写顺序。
#include <thread> #include <atomic> #include <cassert> #include <string> using namespace std; atomic<string*>ptr; atomic<int> data; void Producer() { string*p=new string("Hello"); data.store(42,memory_order_relaxed); ptr.store(p,memory_order_release); } void Consumer() { string*p2; while(!(p2=ptr.load(memory_order_consume))) ; assert(*p2=="Hello");//总是相等 assert(data.load(memory_order_relaxed)==42);//可能断言失败 } int main() { thread t1(Producer); thread t2(Consumer); t1.join(); t2.join(); }
root@ubuntu:~/c++# g++ -std=c++11 atomic9.cpp -o atom -pthread root@ubuntu:~/c++# ./atom root@ubuntu:~/c++#
注意,Consumer函数中第一个assert语句:对指针p2进行解引用操作,其实质是在ptr上调用load。 我们可以保证第一个assert不会被触发,因为通过memory_order_consume的内存顺序,保证while语句中ptr.load必须发生在*p2这个解引用操作(实际上涉及读取指针ptr.load的操作)之前。第二个断言可能失败,原因自行分析下。