简介
本文介绍清华大学聂晓辉等作者发表在JSAC 2019, Artificial Intelligence and Machine Learning for Networking and Communications期刊的论文《Dynamic TCP Initial Windows and CongestionControl Schemes through Reinforcement Learning》。随着网络的飞速发展,网络环境变得复杂多样,传统网络传输协议存在的缺陷会导致传输效率低。针对短流主导的 Web 应用 (如搜索 引擎、新闻网站等),现有的传输协议中,普遍存在流启动慢的问题,导致流完成时间长。针对长流主导的 Web 应用(如视频网站、网盘、FTP 服务等),现有拥塞控制算法一般都是静态配置并且保持不变,而实际Web应用面临多样化的网络环境,不同的网络环境应该选择不同的拥塞控制算法,传统的方法无法保证网络的高效传输。针对短流传输效率低的问题,本文提出了一种基于分组强化学习的方法来动态选择合适的 TCP (Transmission Control Protocol) 初始窗口(InitialWindow, IW),加速短流数据传输。针对长流传输效率低的问题,本文提出了一种深度强化学习的方法来动态选择合适的拥塞控制算法 (Congestion Control, CC),加速长流数据传输。最终实现系统TCP-RL来动态选择TCP初始窗口和拥塞控制算法。通过大规模的线上和线下实验表明,跟现有的方法相比,TCP-RL能够减少约 23%∼29% 短流的网络传输延迟。在动态变化的网络环境下,TCP-RL 能够自动感知网络变化并且快速适应, 加速长流的数据传输。
背景
如今大多数线上的 Web 服务都是基于 TCP 传输数据,比如微软、百度等。TCP 是整个网络传输的重要组成部分,其性能好坏直接影响用户体验和公司收入。TCP 性能优化一直以来是热门的研究话题,基本每年都会有新的拥塞控制算法或者 TCP 优化方法被提出, 但是目前 TCP 的性能依旧无法完全让人满意。主要有两个问题:
本文介绍清华大学聂晓辉等作者发表在JSAC 2019, Artificial Intelligence and Machine Learning for Networking and Communications期刊的论文《Dynamic TCP Initial Windows and CongestionControl Schemes through Reinforcement Learning》。随着网络的飞速发展,网络环境变得复杂多样,传统网络传输协议存在的缺陷会导致传输效率低。针对短流主导的 Web 应用 (如搜索 引擎、新闻网站等),现有的传输协议中,普遍存在流启动慢的问题,导致流完成时间长。针对长流主导的 Web 应用(如视频网站、网盘、FTP 服务等),现有拥塞控制算法一般都是静态配置并且保持不变,而实际Web应用面临多样化的网络环境,不同的网络环境应该选择不同的拥塞控制算法,传统的方法无法保证网络的高效传输。针对短流传输效率低的问题,本文提出了一种基于分组强化学习的方法来动态选择合适的 TCP (Transmission Control Protocol) 初始窗口(InitialWindow, IW),加速短流数据传输。针对长流传输效率低的问题,本文提出了一种深度强化学习的方法来动态选择合适的拥塞控制算法 (Congestion Control, CC),加速长流数据传输。最终实现系统TCP-RL来动态选择TCP初始窗口和拥塞控制算法。通过大规模的线上和线下实验表明,跟现有的方法相比,TCP-RL能够减少约 23%∼29% 短流的网络传输延迟。在动态变化的网络环境下,TCP-RL 能够自动感知网络变化并且快速适应, 加速长流的数据传输。
背景
如今大多数线上的 Web 服务都是基于 TCP 传输数据,比如微软、百度等。TCP 是整个网络传输的重要组成部分,其性能好坏直接影响用户体验和公司收入。TCP 性能优化一直以来是热门的研究话题,基本每年都会有新的拥塞控制算法或者 TCP 优化方法被提出, 但是目前 TCP 的性能依旧无法完全让人满意。主要有两个问题:
- 针对短流的数据传输,TCP存在流启动慢的问题,导致传输效率低,没有充分利用带宽。
- 针对长流的数据传输,TCP 使用的拥塞控制算法版本的性能离理想情况依旧存在一定距离, 目前有很多工作依旧在优化 TCP 拥塞控制算法。
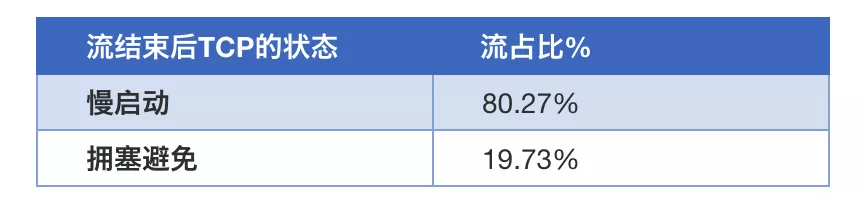
关于第一个问题,当TCP建立连接时,发送端对当前链路的网络情况一无所知,所以为了安全起见,TCP 启动传输时采用了一种静态保守的初始窗口,之后通过慢启动和拥塞避免策略来调整拥塞窗口(CWND)的大小,实时探测合适的发送速率。然而针对短流主导的 Web 服务,大部分流没有完成合适发送速率的探测就完成了数据传输。理想情况下,如果发送端直接用合适的带宽速度发送数据,可能只需要一个 RTT (Round-Trip Time,往返时间) 就能完成数据传输,但由于使用的是保守的初始窗口,则需要多个 RTT 完成传输,导致带宽利用率低,网络传输延迟高。本文在百度的前端服务器做了实际的测量,如表1中所示,使用目前标准初 始窗口等于 10 的方法,80% 的 TCP 流在完成数据传输后仍处于慢启动状态,没有充分利用带宽,这是导致延迟高的主要原因之一。
以上介绍的问题正是 RFC6077[1] 中提到的 TCP 流启动慢的问题(Flow Startup Problem), 被专业的研究机构定义为拥塞控制算法开放的研究问题。谷歌(Google) 曾建议将标准的初始窗口从 2~4 提升到 10[2],但这种做法没有从根本上解决流 启动慢的核心问题,窗口等于10对一些高速网络环境(比如100Mbps 光纤)可能 过小,而对于一些低速网络环境中(比如 GPRS 网络)可能过大。由于 Web服务 提供商服务的实际用户所处的位置不同,接入的网络方式也不同,导致它们网络 环境不一样,即便是同一个用户,其网络环境也会随着时间变化而变化,统一使用同一种初始窗口的做法不合理。
关于第二个问题,在过去几十年里,Web 服务的基础设施和网络技术不断蓬勃发展,比如机器的网卡速率越 来越高,用户接入的带宽越来越大,无线网络的快速崛起(2/3/4/5G)等,可用的网络带宽越来越高,使得当前的网络环境变得多样化。为了能够充分利用这些资 源,不断有人提出新的拥塞控制算法来提升网络传输的性能,比如 Tahoe、Reno、 Cubic、BBR、PCC Vivace、Copa、Indigo等。每种拥塞控制算法声称自己是当前性能最佳的算法,然而在2018 年 USENIX Annual Technical Conference (ATC) 会议上发表的一项研究 Pantheon[3]表明,目前在已有的众多拥塞控制算法版本中,没有一种算法的性能能够在所有的网络环境下击败所有其他算法。
本文的最后实验部分通过大量实验验证了 Pantheon的观点: 目前不存在一种拥塞控制算法能够在所有的网络环境下保持性能最佳。如今大部分 Web 服务提供商(比如微软、百度等)通常的做法是使用统一的拥塞控制算法,如果有 新版本的拥塞控制算法被提出,他们则简单地测试后决定是否使用,但实际Web 服务提供商面临的用户网络环境非常复杂多样,而且用户的网络环境会随着时间变化,统一使用一种协议会导致低效的传输性能。
为了解决上述两个问题,本文提出Web服务提供商可以通过利用强化学习的技术来实时动态调整发送端的初始窗口和拥塞控制算法,分别加速短流和长流的网络传输。
挑战
挑战一:如何在服务器端测量 TCP 的性能指标数据?
强化学习需要实时的性能指标数据来计算决策 (Action) 的奖励(Reward),然而传统的服务器端没有直接输出 TCP 性能指标相关的数据,比如流完成时间、TCP 超时率等,所以需要提出一种有效的数据测量和收集方法。
挑战二:用户网络环境多样化且变化频繁,如何正确地使用强化学习方法?
强化学习思路是基于最新数据和历史经验来调整当前的决策。决策的选择取决于奖励函数的分布,奖励函数的分布取决于环境上下文的(Environment Context) 的情况。在本文中强化学习的环境就是用户 TCP 流所处的网络环境 (比如链路的剩余的可用带宽、RTT、丢包率等等)。
针对短流的初始窗口设置问题,单条流传输时间短,没有足够的信息可供学习,不能确保每个用户都能使用强化学习来学习初始窗口的大小。通过给用户做分组可以获取更多的网络环境数据,但分组同样存在问题,如果用户分组粒度过细,比如一个 IP 为一个用户,可能导致没有足够多的数据采样来描述用户的网络环境,无法计算出合理的TCP 性能指标数据; 如果用户分组的粒度过粗,比如所有用户被分到一个用户组,会导致性能次优。
针对长流的拥塞控制选择,由于流传输时间长,在单条流内有足够的网络信息可学,理论上可以为每条流实时动态的选择合适的拥塞控制算法。
解决方案
本文本提出了动态学习并且设置 TCP 的初始窗口和拥塞控制算法的系统TCP-RL, 只需要在服务器端部署。图1 为 TCP-RL 的总体设计,针对短流的初始窗口优化问题,通过运行一种新的用户分组算法,将不同网络环境的用户分组,之后利用传统的强化学习的方法,动态调整每组用户 TCP 流的初始窗口。针对长流的拥塞控制算法选择问题, 利用深度强化学习技术,离线训练强化学习模型,在线利用模型实现单条流的拥塞控制算法选择。
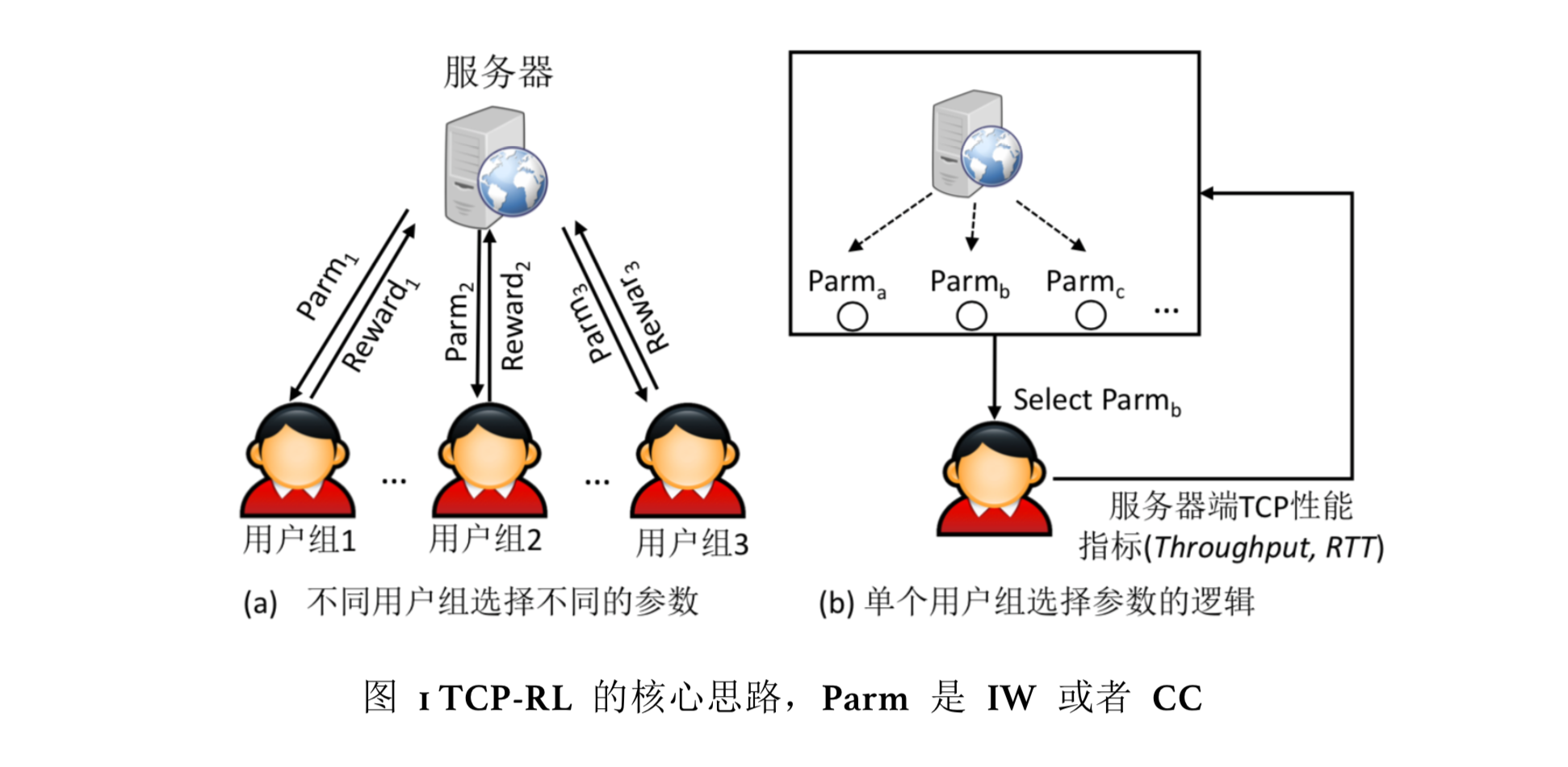
<图1>TCP-RL 的核心思路,Parm 是 IW 或者 CC
为了解决挑战一,TCP-RL 修改了前端服务器的 Linux 内核代码和 Web Server 应用 Nginx的代码,使得服务器能够测量并且实时输出每条用户请求的 TCP 流信息(比如网络传输延迟、丢包率、RTT 等)。整个过程在服务器端完 成,不需要客户端或者中间件做任何改动。该数据采集和测量的工具不仅仅可以用于初始窗口的调整,也可用于 Web 服务的网络性能指标管理、监控、 故障诊断。
为了解决挑战二,针对短流的初始窗口选择问题,TCP-RL认为拥有更多同样网络特征的用户更容易具有相似的网络环境, 比如属于同一个运营商下某特定网段的用户网络环境的似度,比该运营商下的所有用户们的网络环境相似度更高。因此,TCP-RL提出一种自底向上的用户分组方法,将所有的 TCP 流从最细粒度的用户组开始往上聚合,直到找到所有满足使用强化学习条件的最细粒度的用户分组,最后利用在线的强化学习方法动态学习初始窗口大小。针对长流的拥塞控制算法选择问题,通过线下模拟出各种真实网络环境,在模拟环境中学习得到一个离线的最佳拥塞控制算法选择的模型,该模型可以直接供真实线上的 TCP 流使用,帮助线上的流选择最佳的拥塞控制算法,加速流的传 输。为了适应网络变化,TCP-RL用深度学习训练了一个感知网络变化的模 型,帮助拥塞控制算法选择模型快速地适应网络环境的变化。
初始窗口选择算法
1、强化学习算法
TCP-RL将学习初始窗口的问题转变成非平稳环境下的多臂slot machine问题 (non- stationary multi-armed bandit problem),多臂slot machine问题是强化学习领域中典型的问题,它通过在“探索未知决策”和“利用当前最佳决策”之间取得平衡,实现自身利 益最大化。实际有很多的算法用于解决这一类问题。
对于解决稳定环境下的多臂slot machine问题(stationarymulti-armed bandit problem), 强化学习中的 UCB算法被证明是最优的解决方法,UCB 假设环境不变,即 不同决策的奖励分布是固定不变的,不会随着时间变化而变化。然而在学习初始窗口这一问题中,用户的网络环境会随着时间变化而变化,所以本文将学习初始窗 口的问题转变成非平稳环境下的多臂slot machine问题 (non-stationary multi-armed bandit problem)。本节采用了 Discounted UCB 算法,其核心思想是在估算决策的奖励时, 会给过去该决策的奖励做加权平均,离当前时间越近的权重越大,离当前时间越远的权重越小,所以当环境发生变化,Discounted UCB 算法会更多考虑当前时刻的奖励,所以它适用于解决非平稳环境下的多臂slot machine问题。
Discounted UCB 算法的基本过程如算法1 所示,在时刻 t, 玩家会选择 It ∈ 1,..., K 中具有最高信心上限(upper-confidence)的决策。具体计算如公式
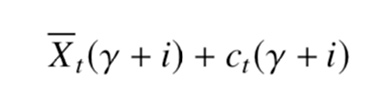
其中
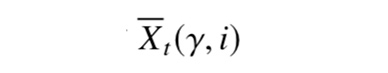
是决策估计出来的奖励值
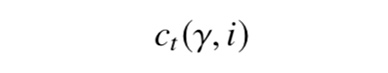
为折扣填充函数(The discounted padding function),如果一个决策在历史中被频繁地使用,那么它的
会比其他决策小,所以其它历史上看起来次优的决策在将来也会有一定概率被使用,从而实现决策探测和利用的平衡。

介绍完 Discounted UCB 的原理后,接下来介绍TCP-RL如何正确的使Discount UCB 算法,主要分为奖励函数的定义和决策空间的定义这两部分。
- 奖励函数定义:TCP-RL目标是通过设置合理的初始窗口来充分利用链路的带宽并且不会造成网络拥塞,减少网络传输时间。奖励函数定义如下公式,同时考虑吞吐率和RTT两个指标。其中 Goodputs(i) 是在 s 时刻使用决策 i 得到的吞吐率,RTTs(i) 是在s 时刻使用决策 i 得到的 RTT,Goodputmax 是在历史 TCP 吞吐率数据中的最大值, RTTmin 是在历史 RTT 数据的最小值, α 平衡吞吐率和 RTT 的参数,α 越小,奖励 函数越看重 RTT,最终算法会为了避免使得 RTT 增大,会选择比较保守的初始窗 口; 相反,α 越大,奖励函数越看重吞吐率,最终算法为了得到较大的吞吐率,会选择比较激进的初始窗口。

- 决策空间的定义:Discounted UCB 的决策空间需要提前定义,而且是一些固定的取值,然而初始窗口是一个连续的取值空间,拥有很大的决策空间,导致无法直接使用 Discounted UCB。TCP-RL使用强化学习的目标之一是需要快速的搜索初始窗口决策空间,找到最优的初始窗口。如果把 Discounted UCB 的初始窗口决策空间定义得过大,会导致算法浪费很多时间在探索新的决策上,最终算法的开销会很高。为了解决上述问题,TCP-RL提出一种快速滑动决策空间(Sliding-Decision-SpaceMethod)的方法,快速收敛到最优的初始窗口。算法初始化时采用了一个很小的初始窗口决策空间 (比如固定 5 个初始窗口的取值),随后该决策空间中的初始窗口的取值会随时他们得到的奖励动态变化而变化,具体如图2。
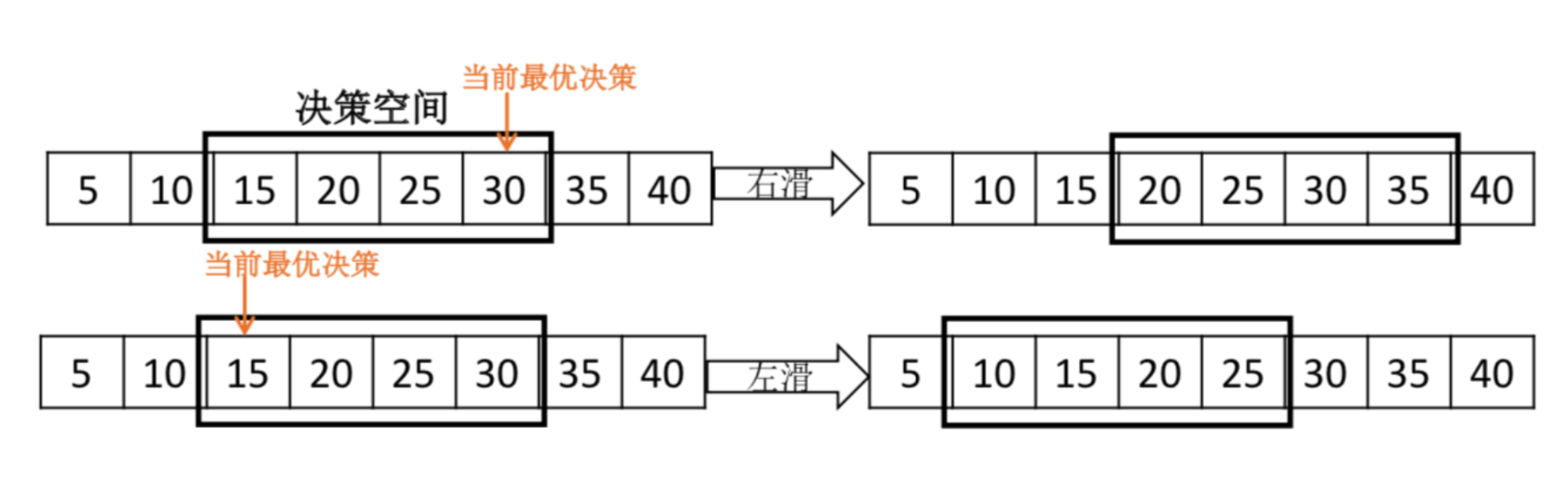
<图2>快速滑动决策空间的过程
2、用户分组算法
用户分组方法核心思想是找到所有用户中最细粒度的用户分组,使得每个用户分组都能满足运行强化学习的条件,即用户的网络环境保持一致性和连续性。算法的基本流程是自底向上的搜索过程,搜索满足运行强化学习条件的用户,用户需要同时满足拥有足够多的采样点和网络环境具有一致性和连续性,利用前文提到的奖励函数来量化网络环境,同时考虑环境的带宽和 RTT。为了量化用户网络环境的一致性和连续性,本文定义一种网络抖动指标。
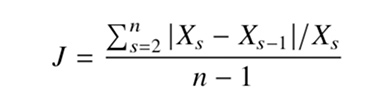
n 表示时间窗口的数目,时间窗口的长度为 t, Xs 表示用户在时间窗口 s 的获得的奖励值。由于初始窗口会影响奖励的计算,所以计算用户的网络抖动指标 J 时,保持用户的初始窗口保持不变。最后通过 J 来量化网络环境的一致性和连续性。如果 J 很小,说明用户的网络环境变化很小。在此定义一个 J 的阈值 T,如果用户组计算出来的 J < T, 则可以利用强化学习算 法学习用户组的最优初始窗口。图3为用户分组算法的基本流程。
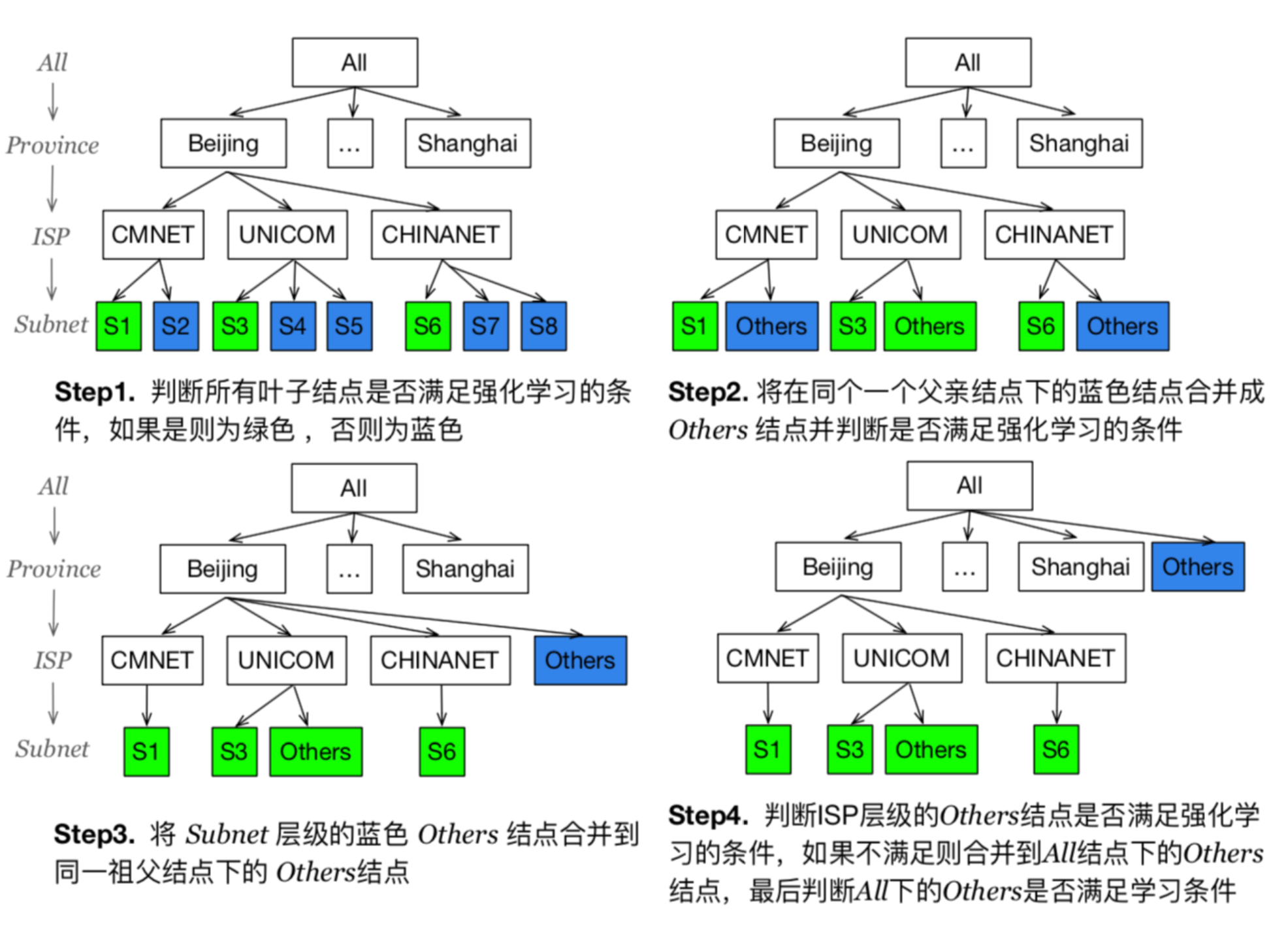
<图3>用户分组算法
拥塞控制选择算法
为了在不同的网络环境下自动选出最佳拥塞控制算法,TCP-RL 系统使用了深度强化学习算法来做动态的拥塞控制算法选择。具体来说,TCP-RL 离线训练了一个深度强化学习模型,并将其用于给定的网络环境下在线选择最佳拥塞控制算法。此外,为了适应动态变化的网络环境,本节训练了一个网络变化感知模型来检测网络环境是否发生变化,并用于辅助深度强化学习算法适应于随时间变化的网络环境。相比在服务级别 (Service-Level) 静态人工选择拥塞控制算法的方法, TCP-RL 这种流级别 (Flow-Level) 的自动、动态的拥塞控制算法选择方法在动态变化的网络环境下的性能会有很大提高。
图4展示了用深度强化学习算法A3C学习拥塞控制算法选择的过程。与传统强化学习算法类似,深度强化学习的目标是个体 (Agent) 在环境 (Environment) 中作出决策 (Action) 来获得最大化累积奖励 (Reward), 从而训练模型在不同环境下做出最佳决策。不同于传统的在线探索-利用机制,深 度强化学习方法通常采用神经网络利用历史经验数据来学习策略(Policy),即在给 定环境下由状态 (State) s 到决策 a 的转移矩阵。具体来说,在拥塞控制算法选择问题中,个体的决策是不同的拥塞控制算法,而个体的状态则包括服务端的各种 TCP 测量数据 (吞吐量(Throughput)、往返时间 (RTT)、丢包率(Loss rate))。TCP-RL 采集当前服务端的TCP 测量数据作为状态输入,利用神经网络学习拥塞控制算法 的选择策略,即建立一个从观测到的网络状态到对应决策(拥塞控制算法的选择) 的映射。根据策略选择一个拥塞控制算法后,测量当前环境 (Environment) 下使用 该算法进行拥塞控制的 TCP 测量数据作为下一步的状态,并用吞吐量与往返时间的比值作为当前环境下采用此决策的奖励 (Reward),表征当前网络的性能状况。以 最大化累积奖励为目标(即动态选择算法来达到最佳网络传输性能),通过大量的离线训练得到深度强化学习模型,从而用于在线的动态网络环境下拥塞控制算法选择。
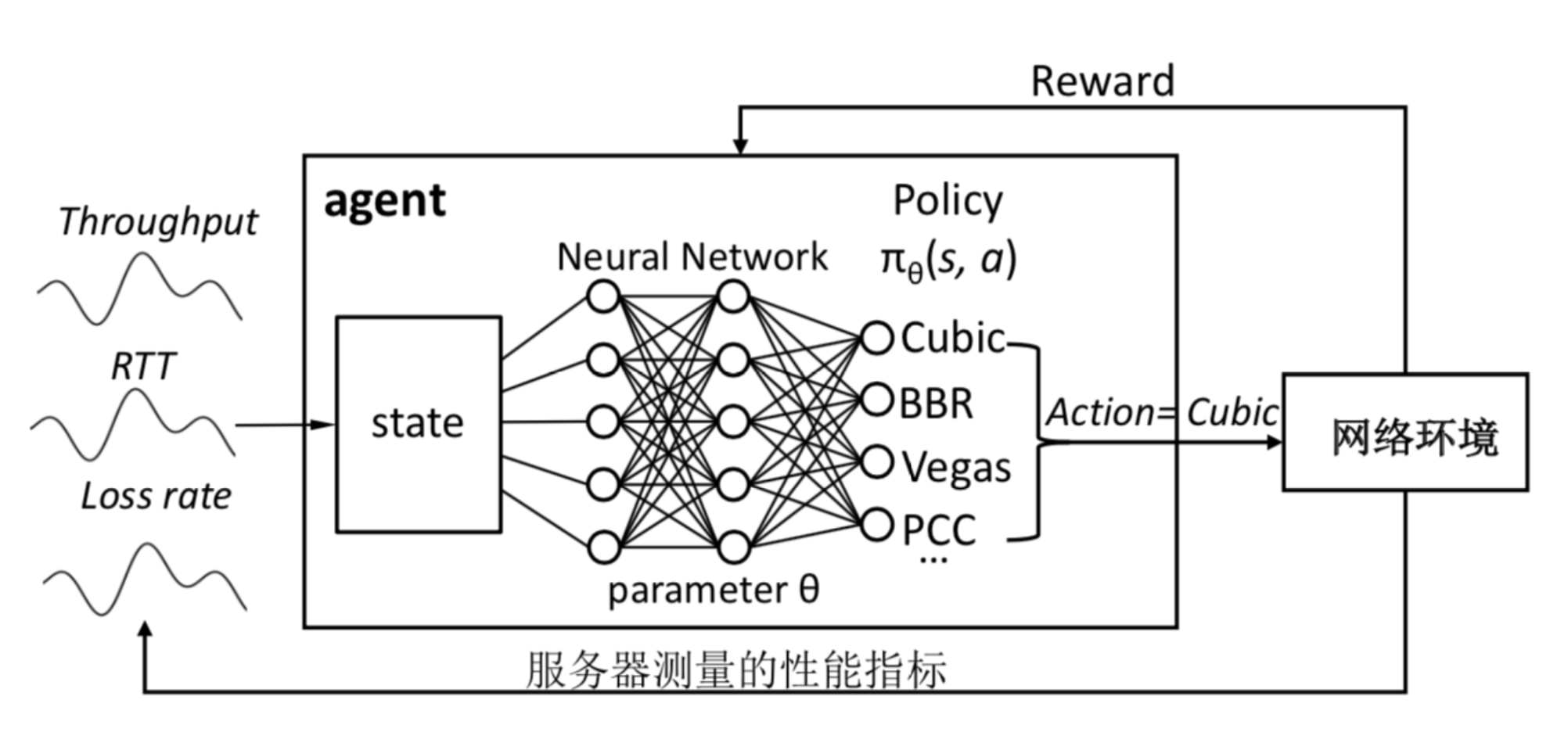
<图4>使用深度强化学习模型进行拥塞控制算法选择
实验
1. 初始窗口优化实验
TCP-RL实际被用在百度公司的无线搜索业务 (Mobile Search) 上,用于加速无线搜索业务的网页数据的传输,选择无线搜索业务做评估的主要因为它是典型短流主导的 Web 应用,此外它也是百度公司最重要的业务之一,最终通过在线 A/B testing的方法评估结果,证明相比传统的方法 TCP-10, TCP-RL能够为业务整体持续减少约 23% 左右的平均网络传输延迟。对于特定的用户组,它能够减少约 30% 的平均网络传输延迟。
图5为两组方法得到的平均网络传输延迟。在 2017 年 09 月 12 日 10:00:00之前,两组机器都采用 TCP-10 的方法,初始窗口都设置成 10,从数据上看,两组机器的网络传输延迟一样。在 2017 年 09 月 13 日 10:00:00 之后,其中一组机器 开始采用 TCP-RL的方法,可见平均网络传输延迟在逐渐地减少,并且之后能够持续比TCP-10的平均网络传输延迟小约23%的比例。同样图6反映了TCP-RL在整个网络传输延迟的分布上都能够带来性能的提升,比如网络传输延迟的 50、 80 分位数都有约 25% 的性能提升,甚至在 99 分位数都有约 5%。TCP-RL主要是通过提升初始窗口带来性能的提升,从本节可以看出本次实验并没有造成过多的拥塞丢包, 没有导致 99 分位数的延迟变高。

<图5>TCP-RL 和 TCP-10 的平均网络传输延迟
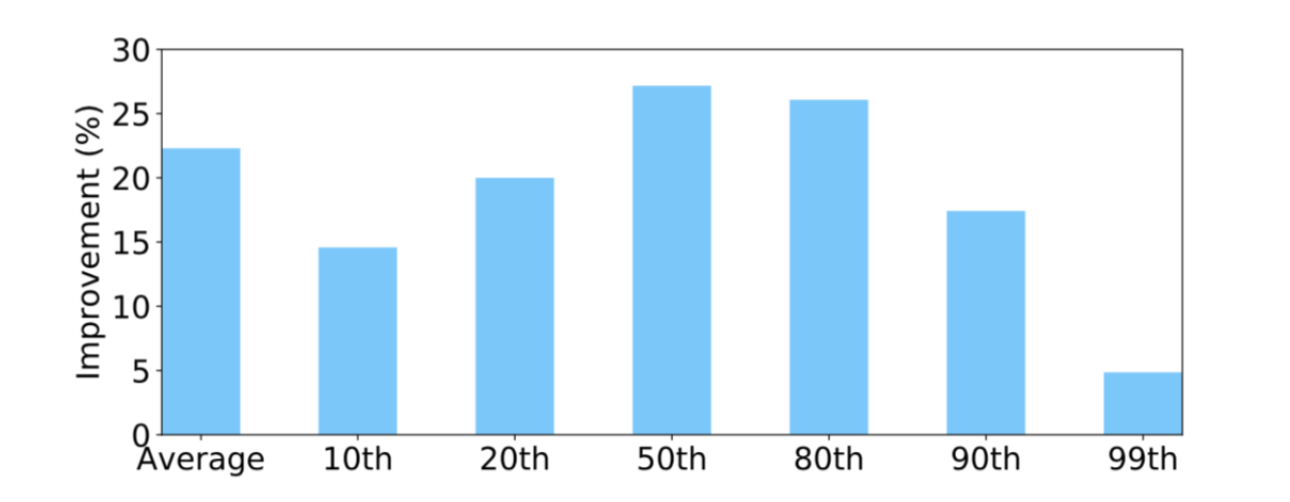
<图6>相比 TCP-10,TCP-RL在网络传输延迟分布的各个分位数性能都有提升
2. 拥塞控制算法优化实验
在文中主要通过模拟真实数据传输的方法来系统的评估 TCP-RL。具体搭 建了一个实验平台,它具有重放线上流量和使用不同的TCP拥塞控制算法的功能。通过实验得到以下结论:
- 在不同的网络环境下,不同拥塞控制算法的性能排名不一样,目前不存在一 种拥塞控制算法能够在所有的网络环境下保持性能最佳。
- TCP-RL 训练的拥塞控制算法选择的神经网络模型只需 1 到 2 步就能找到一 个性能最佳或良好的拥塞控制算法。对比现有的 14 种拥塞控制算法,TCP- RL 能够在 288 种不同的静态网络环境下性能排名前 5,对于其中 90% 的情 况,其性能与最佳的性能相比,最多只差 12%。在动态变化的网络环境下, TCP-RL 能够自动感知网络变化并且快速适应,最终保持性能最佳。
- 在单条流传输过程中,如果网络环境发生变化,TCP-RL 能够感知并且重新收敛到新的拥塞控制算法。
为了测试不同拥塞控制算法在不同的网络环境下的性能,TCP-RL 基于Pantheon平台开发了新的实验平台。Pantheon 平台提供了权威的拥塞控制算法的实现,此外TCP-RL 利用mahimahi作为网络模拟的工具,mahimahi 能够在实际的物理机器上为每条 TCP 流模拟不同的网络环境。TCP-RL 利用了 288 种网络环境来训练拥塞控制算法选择的神经网络模型。每种网络环境主要确定带宽、RTT 和丢包率。288 种网络环境是由带宽 ∈ (1, 5, 10, 20, 50, 70, 100, 150, 200 Mbps), RTT ∈ (10, 20, 40,60, 80, 100, 150, 200ms), 丢包率 ∈ (0, 1%, 2%, 10%) 排列组合而成。
图7展示了不同拥塞控制算法在 288 种网络环境下性能排名第一的比例分布,这个结果证明了之前的结论:目前不存在一种拥塞控制算法能够在所有的网络环境下保持性能最佳。Copa 协议在 28% 的网络环境下拥有最佳的性能,属于性能良好的拥塞控制算法。Cubic、 Fillp 这些拥塞控制在288 种网络环境下都不能达到最佳的性能排名。
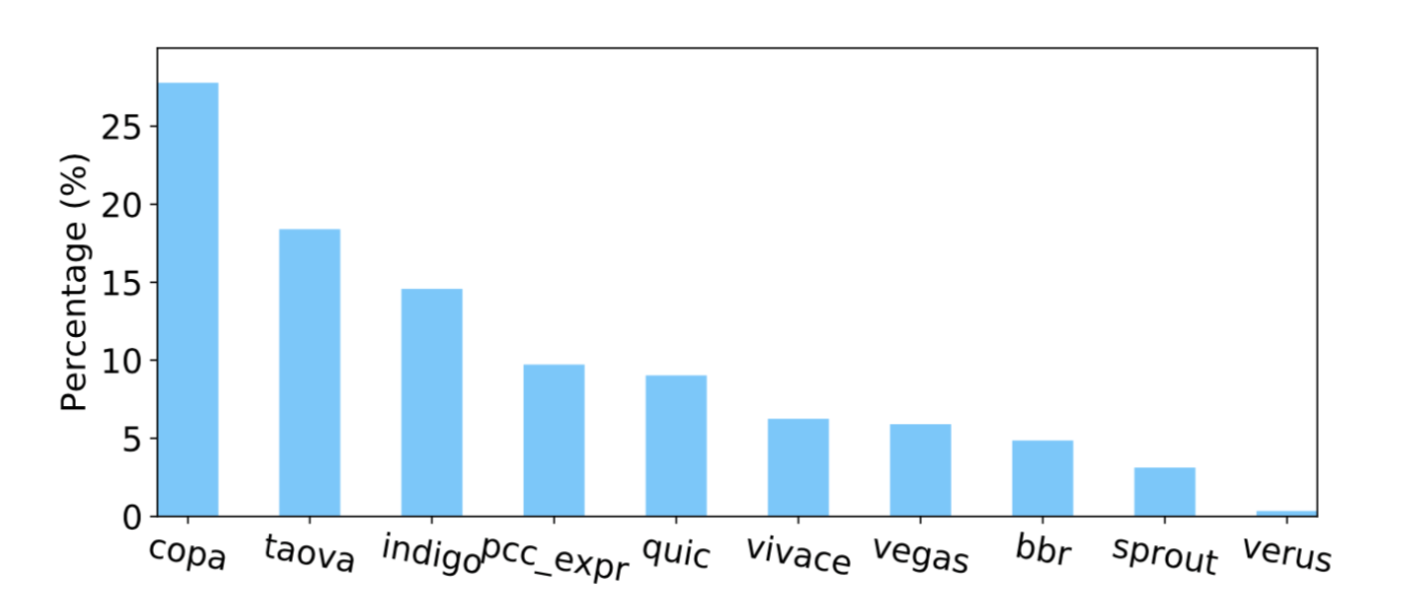
<图7>拥塞控制算法在 288 种网络环境下性能最佳的比例分布
TCP-RL 在 288 种网络环境下测试了 TCP-RL 学习出来的拥塞控制算法选择的神经网络模型,图8表示在不同网络环境下 TCP-RL 选择的拥塞控制算法性能排名的累积分布,可见约 85% 的情况下 TCP-RL 能够选出性能排名前 5 的算法。
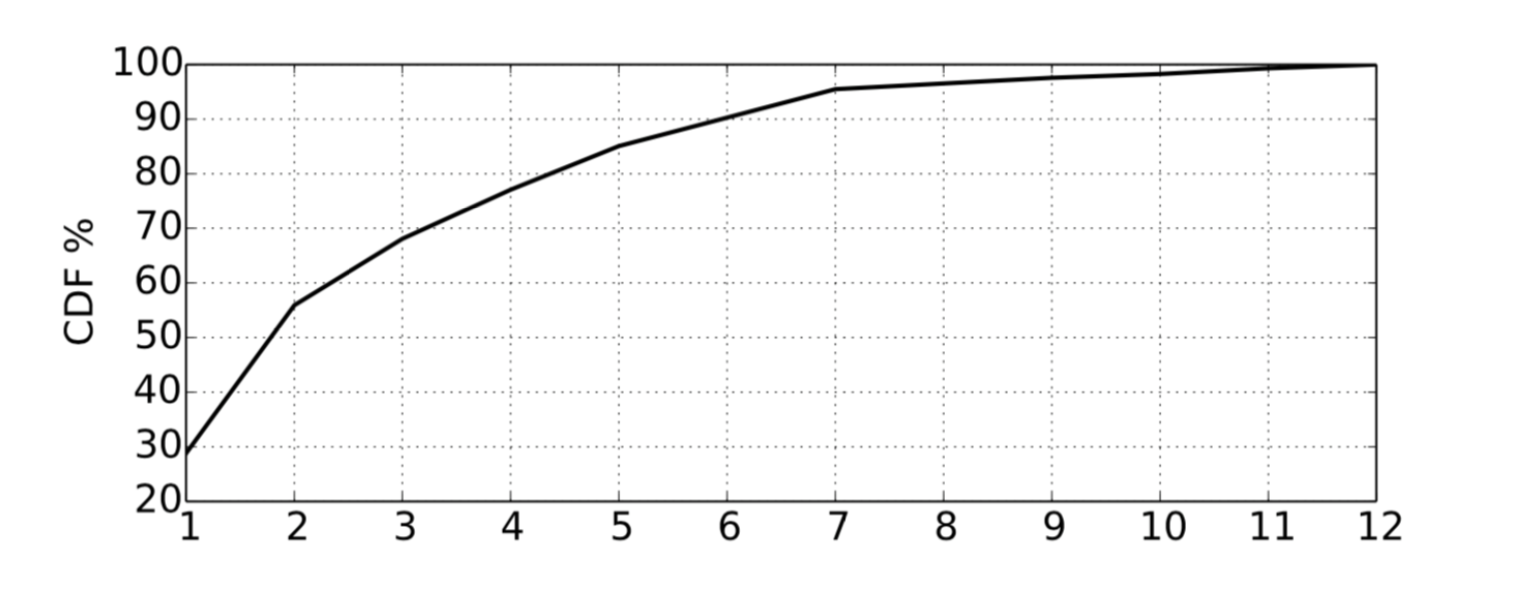
<图8>TCP-RL 选择的拥塞控制算法性能排名
实际链路的网络环境会随着时间变化,TCP-RL 随机的模拟了一种网络环境随时间变化的情况,每分钟变化一次网络的参数,其(带宽,RTT,丢包率)的变化 轨迹为 (20Mbps, 20 ms, 2%) → (50 Mbps, 40 ms, 1%) → (150 Mbps, 20 ms, 10%) → (200 M bps,20 ms, 1%)。表2展示了所有算法的传输性能指标(平均奖励、平均吞吐率、平均的 95 分位 RTT、平均丢包率)。其中奖励值、吞吐率越大越好,RTT 和丢包率越小越好。从结果可以看出 TCP-RL 是性能最好的方案。
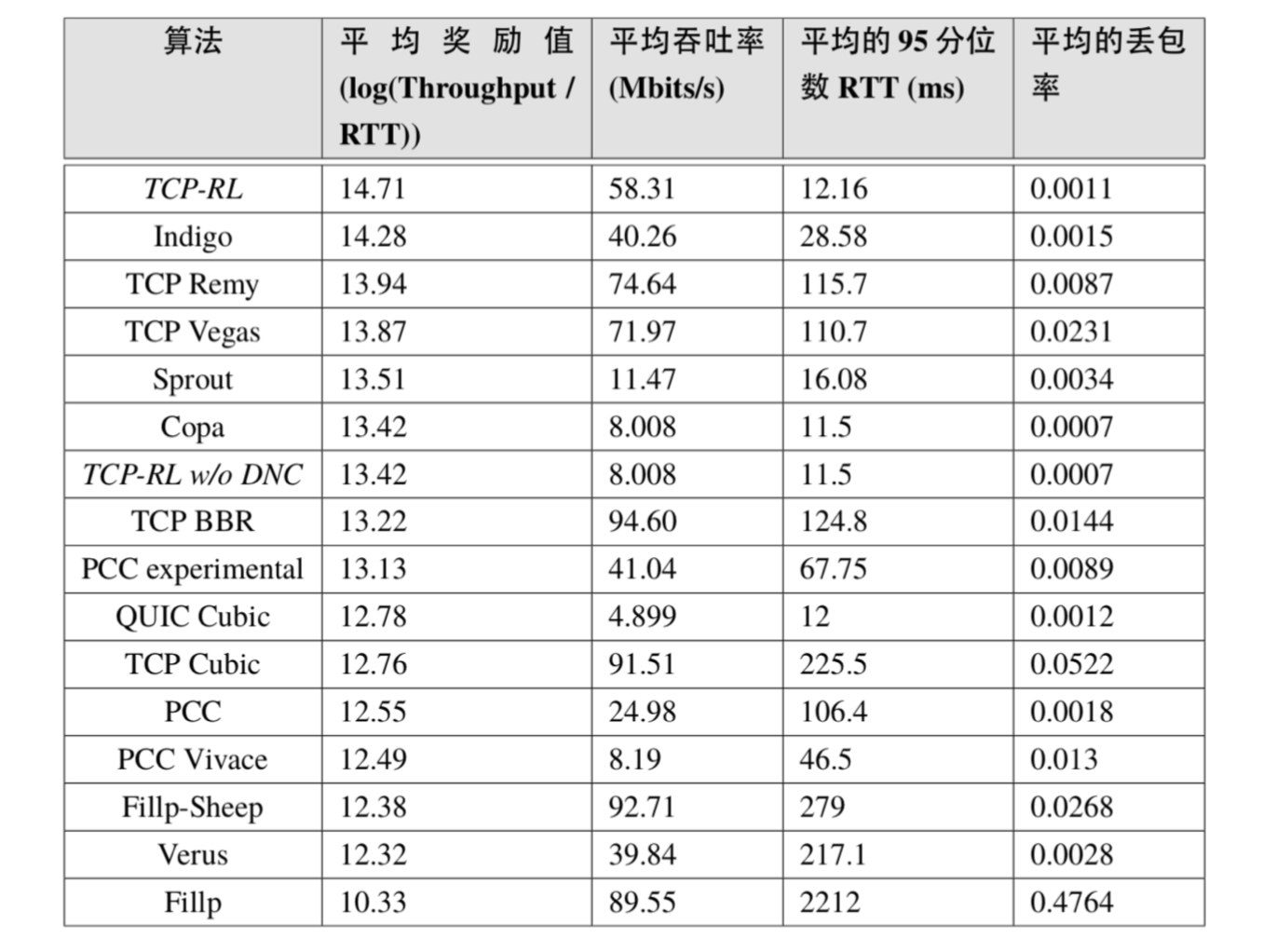
<表格2> TCP-RL 与现有算法性能对比结果
结论
针对短流主导的 Web 应用,本文测量了实际百度无线搜索业务的数据验证了导致网络传输延迟高的主要问题是TCP流启动慢。针对长流主导的Web应用,不同网络环境应该使用不同的拥塞控制算法,当前使用单一的拥塞控制控制算法性能存在问题。为了解决这两个问题,本章设计并实现了TCP-RL系统,为了加速短流的数据传输,在 TCP 流传输之前,TCP-RL通过分组强化学习方法实时学习最优的 TCP 初始窗口大小并且动态地设置。通过大规模试验验证TCP-RL能够减少约 23%~29% 的网络传输延迟。为了加速长流的数据传输,相比一些前人不断提出新的拥塞控制算法的工作,TCP-RL核心思路是充分利用现有的拥塞控制算法,通过利用深度强化学习的技术,根据当前网络环境动态选择与之对应最佳的拥塞控制算法。最终通过大规模的真实网络环境的模拟实验验证,对比现有的 14 种拥塞控制算法,TCP-RL 能够在 288 种不同的静态网络环境下性能排名前 5,综合性能排名第一。此外,TCP-RL整体系统容易部署,只需要修改服务器端,不需要客户端做任何的修改即可运行生效。