[root@localhost ~]# ovs-ofctl dump-flows br0 cookie=0x0, duration=706691.312s, table=0, n_packets=84180530, n_bytes=7456796909, priority=0 actions=NORMAL cookie=0x0, duration=706444.352s, table=1, n_packets=0, n_bytes=0, ip,nw_dst=192.168.2.210 actions=mod_dl_dst:2e:a9:be:9e:4d:07 [root@localhost ~]# ovs-ofctl del-flows br0 [root@localhost ~]# ovs-ofctl del-flows br0 [root@localhost ~]# ovs-ofctl dump-flows br0 [root@localhost ~]#
虚拟机
qemu-system-aarch64 -name vm2 -nographic -enable-kvm -M virt,usb=off -cpu host -smp 2 -m 4096 -global virtio-blk-device.scsi=off -device virtio-scsi-device,id=scsi -kernel vmlinuz-4.18 --append "console=ttyAMA0 root=UUID=6a09973e-e8fd-4a6d-a8c0-1deb9556f477" -initrd initramfs-4.18 -drive file=vhuser-test1.qcow2 -m 2048M -numa node,memdev=mem -mem-prealloc -object memory-backend-file,id=mem,size=2048M,mem-path=/dev/hugepages,share=on -chardev socket,id=char1,path=$VHOST_SOCK_DIR/vhost-user1 -netdev type=vhost-user,id=mynet1,chardev=char1,vhostforce -device virtio-net-pci,netdev=mynet1,mac=00:00:00:00:00:01,mrg_rxbuf=off
[root@localhost ~]# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 00:00:00:00:00:01 brd ff:ff:ff:ff:ff:ff inet6 fe80::200:ff:fe00:1/64 scope link valid_lft forever preferred_lft forever [root@localhost ~]# ip a add 10.10.103.229/24 dev eth0 [root@localhost ~]# ping 10.10.103.81 PING 10.10.103.81 (10.10.103.81) 56(84) bytes of data. 64 bytes from 10.10.103.81: icmp_seq=1 ttl=64 time=0.374 ms 64 bytes from 10.10.103.81: icmp_seq=2 ttl=64 time=0.144 ms --- 10.10.103.81 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1001ms rtt min/avg/max/mdev = 0.144/0.259/0.374/0.115 ms
(gdb) b dp_netdev_upcall Breakpoint 1 at 0x96c638: file lib/dpif-netdev.c, line 6434. (gdb) c Continuing. [Switching to Thread 0xfffd53ffd510 (LWP 117402)] Breakpoint 1, dp_netdev_upcall (pmd=pmd@entry=0x18f60810, packet_=packet_@entry=0x16e0f4b80, flow=flow@entry=0xfffd53ff48d8, wc=wc@entry=0xfffd53ff4b78, ufid=ufid@entry=0xfffd53ff4328, type=type@entry=DPIF_UC_MISS, userdata=userdata@entry=0x0, actions=actions@entry=0xfffd53ff4348, put_actions=0xfffd53ff4388) at lib/dpif-netdev.c:6434 6434 { (gdb) bt #0 dp_netdev_upcall (pmd=pmd@entry=0x18f60810, packet_=packet_@entry=0x16e0f4b80, flow=flow@entry=0xfffd53ff48d8, wc=wc@entry=0xfffd53ff4b78, ufid=ufid@entry=0xfffd53ff4328, type=type@entry=DPIF_UC_MISS, userdata=userdata@entry=0x0, actions=actions@entry=0xfffd53ff4348, put_actions=0xfffd53ff4388) at lib/dpif-netdev.c:6434 #1 0x0000000000976558 in handle_packet_upcall (put_actions=0xfffd53ff4388, actions=0xfffd53ff4348, key=0xfffd53ff9350, packet=0x16e0f4b80, pmd=0x18f60810) at lib/dpif-netdev.c:6823 #2 fast_path_processing (pmd=pmd@entry=0x18f60810, packets_=packets_@entry=0xfffd53ffca80, keys=keys@entry=0xfffd53ff7d60, flow_map=flow_map@entry=0xfffd53ff5640, index_map=index_map@entry=0xfffd53ff5620 "", in_port=<optimized out>) at lib/dpif-netdev.c:6942 #3 0x0000000000977f58 in dp_netdev_input__ (pmd=pmd@entry=0x18f60810, packets=packets@entry=0xfffd53ffca80, md_is_valid=md_is_valid@entry=false, port_no=port_no@entry=2) at lib/dpif-netdev.c:7031 #4 0x0000000000978680 in dp_netdev_input (port_no=2, packets=0xfffd53ffca80, pmd=0x18f60810) at lib/dpif-netdev.c:7069 #5 dp_netdev_process_rxq_port (pmd=pmd@entry=0x18f60810, rxq=0x1721f440, port_no=2) at lib/dpif-netdev.c:4480 #6 0x0000000000978a24 in pmd_thread_main (f_=0x18f60810) at lib/dpif-netdev.c:5731 #7 0x00000000009fc5dc in ovsthread_wrapper (aux_=<optimized out>) at lib/ovs-thread.c:383 #8 0x0000ffffb19f7d38 in start_thread (arg=0xfffd53ffd510) at pthread_create.c:309 #9 0x0000ffffb16df690 in thread_start () from /lib64/libc.so.6 (gdb)
ovs
现在Open vSwitch主要由三个部分组成:
- ovsdb-server:OpenFlow本身被设计成网络数据包的一种处理流程,它没有考虑软件交换机的配 置,例如配置QoS,关联SDN控制器等。ovsdb-server是Open vSwitch对于OpenFlow实现的补 充,它作为OpenvSwitch的configuration database,保存Open vSwitch的持久化数据。
- ovs-vswitchd:运行在用户空间的转发程序,接收SDN控制器下发的OpenFlow规则。并且通知 OVS内核模块该如何处理网络数据包。
- OVS内核模块:运行在内核空间的转发程序,根据ovs-vswitchd的指示,处理网络数据包
Open vSwitch中有快速路径(fast path)和慢速路径(slow path)。其中ovs-vswitchd代表了slow path,OVS内核模块代表了fast path。现在OpenFlow存储在slow path中,但是为了快速转发,网络包 应该尽可能的在fast path中转发。因此,OpenVSwitch按照下面的逻辑完成转发。
当一个网络连接的第一个网络数据包(首包)被发出时,OVS内核模块会先收到这个数据包。但是内核 模块现在还不知道如何处理这个包,因为所有的OpenFlow都存在ovs-vswitchd,因此它的默认行为是 将这个包上送到ovs-vswitchd。ovs-vswitchd通过OpenFlow pipeline,处理完网络数据包送回给OVS内 核模块,同时,ovs-vswitchd还会生成一串类似于OpenFlow Action,但是更简单的datapath action。 这串datapath action会一起送到OVS内核模块。因为同一个网络连接的所有网络数据包特征(IP, MAC,端口号)都一样,当OVS内核模块收到其他网络包的时候,可以直接应用datapath action。
这样,成功的解决了之前的问题。首先,内核模块不用关心OpenFlow的变化,不用考虑OpenVSwitch的代码更新,这些都在ovs-vswitchd完成。其次,整个网络连接,只有首包需要经过OpenFlow pipeline的处理,其余的包在内核模块匹配网络包特征,直接应用datapath action,就可以完成转发。OVS内核模块通过缓存来保持datapath action的记录。稍微早期的内核模块实现了名为microflow的缓存,这个缓存就是一个hash map,key是所有OpenFlow可能匹配的值对应的hash值,包括了网络2-4层header数据和一些其他的metadata例如in_port,value就是datapath action。hash map可以实现O(1)的查找时间,这样可以在OVS内核模块中实现高效的查找转发。
kernel收包
通过vport注册的回调函数netdev_frame_hook()->netdev_frame_hook()-> netdev_port_receive()->ovs_vport_receive()处理接收报文,ovs_flow_key_extract()函数生成flow的key内容用以接下来进行流表匹配,最后调用ovs_dp_process_packet()函数进入真正的ovs数据包处理,代码流程如下:

action处理
ovs的action类型如下,使用nla_type()函数获取nl_type的值,入口处理函数为do_execute_actions()。

enum ovs_action_attr { OVS_ACTION_ATTR_UNSPEC, OVS_ACTION_ATTR_OUTPUT, /* u32 port number. */ OVS_ACTION_ATTR_USERSPACE, /* Nested OVS_USERSPACE_ATTR_*. */ OVS_ACTION_ATTR_SET, /* One nested OVS_KEY_ATTR_*. */ OVS_ACTION_ATTR_PUSH_VLAN, /* struct ovs_action_push_vlan. */ OVS_ACTION_ATTR_POP_VLAN, /* No argument. */ OVS_ACTION_ATTR_SAMPLE, /* Nested OVS_SAMPLE_ATTR_*. */ OVS_ACTION_ATTR_RECIRC, /* u32 recirc_id. */ OVS_ACTION_ATTR_HASH, /* struct ovs_action_hash. */ OVS_ACTION_ATTR_PUSH_MPLS, /* struct ovs_action_push_mpls. */ OVS_ACTION_ATTR_POP_MPLS, /* __be16 ethertype. */ OVS_ACTION_ATTR_SET_MASKED, /* One nested OVS_KEY_ATTR_* including * data immediately followed by a mask. * The data must be zero for the unmasked * bits. */ OVS_ACTION_ATTR_CT, /* Nested OVS_CT_ATTR_* . */ OVS_ACTION_ATTR_TRUNC, /* u32 struct ovs_action_trunc. */ OVS_ACTION_ATTR_PUSH_ETH, /* struct ovs_action_push_eth. */ OVS_ACTION_ATTR_POP_ETH, /* No argument. */ OVS_ACTION_ATTR_CT_CLEAR, /* No argument. */ OVS_ACTION_ATTR_PUSH_NSH, /* Nested OVS_NSH_KEY_ATTR_*. */ OVS_ACTION_ATTR_POP_NSH, /* No argument. */ OVS_ACTION_ATTR_METER, /* u32 meter ID. */ OVS_ACTION_ATTR_CLONE, /* Nested OVS_CLONE_ATTR_*. */ OVS_ACTION_ATTR_CHECK_PKT_LEN, /* Nested OVS_CHECK_PKT_LEN_ATTR_*. */ __OVS_ACTION_ATTR_MAX, /* Nothing past this will be accepted * from userspace. */ #ifdef __KERNEL__ OVS_ACTION_ATTR_SET_TO_MASKED, /* Kernel module internal masked * set action converted from * OVS_ACTION_ATTR_SET. */ #endif };
OVS_ACTION_ATTR_OUTPUT:获取port号,调用do_output()发送报文到该port;
OVS_ACTION_ATTR_USERSPACE:调用output_userspace()发送到用户态;
OVS_ACTION_ATTR_HASH:调用execute_hash()获取skb的hash赋值到ovs_flow_hash
OVS_ACTION_ATTR_PUSH_VLAN:调用push_vlan()增加vlan头部
upcall处理
当没有找到匹配的流表时,内核通过netlink发送报文到用户层处理,入口函数ovs_dp_upcall(),该函数调用queue_userspace_packet()构造发往用户层的skb,通过netlink通信机制发送到用户层,其中形成的主要数据格式如下: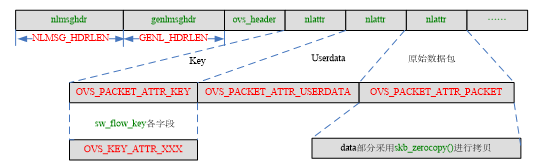
output_userspace ovs_dp_upcall queue_userspace_packet skb_zerocopy(user_skb, skb, skb->len, hlen); //upcall信息对象添加报文
void ovs_dp_process_packet(struct sk_buff *skb, struct sw_flow_key *key) { const struct vport *p = OVS_CB(skb)->input_vport; struct datapath *dp = p->dp; struct sw_flow *flow; struct sw_flow_actions *sf_acts; struct dp_stats_percpu *stats; u64 *stats_counter; u32 n_mask_hit; stats = this_cpu_ptr(dp->stats_percpu); /* Look up flow. */ flow = ovs_flow_tbl_lookup_stats(&dp->table, key, &n_mask_hit); if (unlikely(!flow)) { struct dp_upcall_info upcall; int error; memset(&upcall, 0, sizeof(upcall)); upcall.cmd = OVS_PACKET_CMD_MISS; upcall.portid = ovs_vport_find_upcall_portid(p, skb); upcall.mru = OVS_CB(skb)->mru; error = ovs_dp_upcall(dp, skb, key, &upcall, 0); if (unlikely(error)) kfree_skb(skb); else consume_skb(skb); stats_counter = &stats->n_missed; goto out; } ovs_flow_stats_update(flow, key->tp.flags, skb); sf_acts = rcu_dereference(flow->sf_acts); ovs_execute_actions(dp, skb, sf_acts, key); stats_counter = &stats->n_hit; out: /* Update datapath statistics. */ u64_stats_update_begin(&stats->syncp); (*stats_counter)++; stats->n_mask_hit += n_mask_hit; u64_stats_update_end(&stats->syncp); }
action
遍历所有的action,支持的有OFPACT_OUTPUT、OFPACT_GROUP、OFPACT_CONTROLLER、OFPACT_ENQUEUE、OFPACT_SET_VLAN_VID、OFPACT_SET_VLAN_PCP、OFPACT_STRIP_VLAN、OFPACT_PUSH_VLAN、OFPACT_SET_ETH_SRC、OFPACT_SET_ETH_DST、OFPACT_SET_IPV4_SRC、
OFPACT_SET_IPV4_DST、OFPACT_SET_IP_DSCP、OFPACT_SET_IP_ECN、OFPACT_SET_IP_TTL、OFPACT_SET_L4_SRC_PORT、OFPACT_SET_L4_DST_PORT、OFPACT_RESUBMIT、OFPACT_SET_TUNNEL、OFPACT_SET_QUEUE、OFPACT_POP_QUEUE、OFPACT_REG_MOVE、
OFPACT_SET_FIELD、OFPACT_STACK_PUSH、OFPACT_STACK_POP、OFPACT_PUSH_MPLS、OFPACT_POP_MPLS、OFPACT_SET_MPLS_LABEL、OFPACT_SET_MPLS_TC、OFPACT_SET_MPLS_TTL、OFPACT_DEC_MPLS_TTL、OFPACT_DEC_TTL、OFPACT_NOTE、OFPACT_MULTIPATH、
OFPACT_BUNDLE、OFPACT_OUTPUT_REG、OFPACT_OUTPUT_TRUNC、OFPACT_LEARN、OFPACT_CONJUNCTION、OFPACT_EXIT、OFPACT_UNROLL_XLATE、OFPACT_FIN_TIMEOUT、OFPACT_CLEAR_ACTIONS、OFPACT_WRITE_ACTIONS、OFPACT_WRITE_METADATA、OFPACT_METER、
OFPACT_GOTO_TABLE、OFPACT_SAMPLE、OFPACT_CLONE、OFPACT_CT、OFPACT_CT_CLEAR、OFPACT_NAT、OFPACT_DEBUG_RECIRC,
action太多,我们先介绍几个常用的
OFPACT_OUTPUT,xlate_output_action会根据端口情况进行一些操作,这块不细看了
OFPACT_CONTROLLER,execute_controller_action生成一个packet_in报文,然后发送
OFPACT_SET_ETH_SRC、OFPACT_SET_ETH_DST、OFPACT_SET_IPV4_SRC、OFPACT_SET_IPV4_DST、OFPACT_SET_IP_DSCP、OFPACT_SET_IP_ECN、OFPACT_SET_IP_TTL、OFPACT_SET_L4_SRC_PORT、OFPACT_SET_L4_DST_PORT,修改源目的mac、IP以及DSCP、ECN、TTL和L4的源目的端口
OFPACT_RESUBMIT,xlate_ofpact_resubmit会继续查找指定的table的流表
OFPACT_SET_TUNNEL,设置tunnel id
OFPACT_CT,compose_conntrack_action执行完ct的设置之后回调do_xlate_actions执行其他的action
packetin数据包
ovs-ofctl add-flow br0 in_port=1,actions=controller
OFPP_CONTROLLER xlate_actions ┣━do_xlate_actions(ofpacts, ofpacts_len, &ctx, true, false); ┣━xlate_output_action do_xlate_actions { switch (a->type) { case OFPACT_OUTPUT: xlate_output_action(ctx, ofpact_get_OUTPUT(a)->port, ofpact_get_OUTPUT(a)->max_len, true, last, false, group_bucket_action); break; } xlate_output_action(struct xlate_ctx *ctx, ofp_port_t port, uint16_t controller_len, bool may_packet_in, bool is_last_action, bool truncate, bool group_bucket_action) { case OFPP_CONTROLLER: xlate_controller_action(ctx, controller_len, (ctx->in_packet_out ? OFPR_PACKET_OUT : group_bucket_action ? OFPR_GROUP : ctx->in_action_set ? OFPR_ACTION_SET : OFPR_ACTION), 0, UINT32_MAX, NULL, 0); }
packetout数据包
处理controller发送的packetout数据包:
ofconn_run
|
handle_openflow
|
handle_packet_out
dpdk
(gdb) b odp_execute_actions Breakpoint 4 at 0x9ac7c0: file lib/odp-execute.c, line 849. (gdb) c Continuing. [Switching to Thread 0xfffd797ad510 (LWP 117399)] Breakpoint 4, odp_execute_actions (dp=dp@entry=0xfffd797a4338, batch=batch@entry=0xfffd797a43c8, steal=steal@entry=true, actions=0xfffd797a44e0, actions_len=8, dp_execute_action=dp_execute_action@entry=0x9799b4 <dp_execute_cb>) at lib/odp-execute.c:849 849 { (gdb) bt #0 odp_execute_actions (dp=dp@entry=0xfffd797a4338, batch=batch@entry=0xfffd797a43c8, steal=steal@entry=true, actions=0xfffd797a44e0, actions_len=8, dp_execute_action=dp_execute_action@entry=0x9799b4 <dp_execute_cb>) at lib/odp-execute.c:849 #1 0x00000000009765c0 in dp_netdev_execute_actions (actions_len=<optimized out>, actions=<optimized out>, flow=0xfffd797a48d8, should_steal=true, packets=0xfffd797a43c8, pmd=0x17dcfc70) at lib/dpif-netdev.c:7596 #2 handle_packet_upcall (put_actions=0xfffd797a4388, actions=0xfffd797a4348, key=0xfffd797a80d0, packet=0x21ed94b480, pmd=0x17dcfc70) at lib/dpif-netdev.c:6846 #3 fast_path_processing (pmd=pmd@entry=0x17dcfc70, packets_=packets_@entry=0xfffd797aca80, keys=keys@entry=0xfffd797a7d60, flow_map=flow_map@entry=0xfffd797a5640, index_map=index_map@entry=0xfffd797a5620 "", in_port=<optimized out>) at lib/dpif-netdev.c:6942 #4 0x0000000000977f58 in dp_netdev_input__ (pmd=pmd@entry=0x17dcfc70, packets=packets@entry=0xfffd797aca80, md_is_valid=md_is_valid@entry=false, port_no=port_no@entry=3) at lib/dpif-netdev.c:7031 #5 0x0000000000978680 in dp_netdev_input (port_no=3, packets=0xfffd797aca80, pmd=0x17dcfc70) at lib/dpif-netdev.c:7069 #6 dp_netdev_process_rxq_port (pmd=pmd@entry=0x17dcfc70, rxq=0x17432950, port_no=3) at lib/dpif-netdev.c:4480 #7 0x0000000000978a24 in pmd_thread_main (f_=0x17dcfc70) at lib/dpif-netdev.c:5731 #8 0x00000000009fc5dc in ovsthread_wrapper (aux_=<optimized out>) at lib/ovs-thread.c:383 #9 0x0000ffffb19f7d38 in start_thread (arg=0xfffd797ad510) at pthread_create.c:309 #10 0x0000ffffb16df690 in thread_start () from /lib64/libc.so.6 (gdb) quit A debugging session is active. Inferior 1 [process 116553] will be detached.
dp_execute_action
(gdb) b dp_execute_cb Breakpoint 2 at 0x9799b4: file lib/dpif-netdev.c, line 7237. (gdb) c Continuing. Breakpoint 2, dp_execute_cb (aux_=0xfffd53ff4338, packets_=0xfffd53ff43c8, a=0xfffd53ff44e0, should_steal=false) at lib/dpif-netdev.c:7237 7237 { (gdb) bt #0 dp_execute_cb (aux_=0xfffd53ff4338, packets_=0xfffd53ff43c8, a=0xfffd53ff44e0, should_steal=false) at lib/dpif-netdev.c:7237 #1 0x00000000009ac8ac in odp_execute_actions (dp=dp@entry=0xfffd53ff4338, batch=batch@entry=0xfffd53ff43c8, steal=steal@entry=true, actions=<optimized out>, actions_len=<optimized out>, dp_execute_action=dp_execute_action@entry=0x9799b4 <dp_execute_cb>) at lib/odp-execute.c:864 #2 0x00000000009765c0 in dp_netdev_execute_actions (actions_len=<optimized out>, actions=<optimized out>, flow=0xfffd53ff48d8, should_steal=true, packets=0xfffd53ff43c8, pmd=0x18f60810) at lib/dpif-netdev.c:7596 #3 handle_packet_upcall (put_actions=0xfffd53ff4388, actions=0xfffd53ff4348, key=0xfffd53ff8570, packet=0x16e027400, pmd=0x18f60810) at lib/dpif-netdev.c:6846 #4 fast_path_processing (pmd=pmd@entry=0x18f60810, packets_=packets_@entry=0xfffd53ffca80, keys=keys@entry=0xfffd53ff7d60, flow_map=flow_map@entry=0xfffd53ff5640, index_map=index_map@entry=0xfffd53ff5620 "", in_port=<optimized out>) at lib/dpif-netdev.c:6942 #5 0x0000000000977f58 in dp_netdev_input__ (pmd=pmd@entry=0x18f60810, packets=packets@entry=0xfffd53ffca80, md_is_valid=md_is_valid@entry=false, port_no=port_no@entry=2) at lib/dpif-netdev.c:7031 #6 0x0000000000978680 in dp_netdev_input (port_no=2, packets=0xfffd53ffca80, pmd=0x18f60810) at lib/dpif-netdev.c:7069 #7 dp_netdev_process_rxq_port (pmd=pmd@entry=0x18f60810, rxq=0x1721f440, port_no=2) at lib/dpif-netdev.c:4480 #8 0x0000000000978a24 in pmd_thread_main (f_=0x18f60810) at lib/dpif-netdev.c:5731 #9 0x00000000009fc5dc in ovsthread_wrapper (aux_=<optimized out>) at lib/ovs-thread.c:383 #10 0x0000ffffb19f7d38 in start_thread (arg=0xfffd53ffd510) at pthread_create.c:309 #11 0x0000ffffb16df690 in thread_start () from /lib64/libc.so.6 (gdb)
dp_netdev_process_rxq_port
dp_netdev_process_rxq_port(struct dp_netdev_pmd_thread *pmd, struct netdev_rxq *rx, odp_port_t port_no) { struct dp_packet_batch batch; int error; dp_packet_batch_init(&batch); cycles_count_start(pmd); /*通过调用netdev_class->rxq_recv从rx中收包存入batch中*/ error = netdev_rxq_recv(rx, &batch); cycles_count_end(pmd, PMD_CYCLES_POLLING); if (!error) { *recirc_depth_get() = 0; cycles_count_start(pmd); /*将batch中的包转入datapath中进行处理*/ dp_netdev_input(pmd, &batch, port_no); cycles_count_end(pmd, PMD_CYCLES_PROCESSING); } ... }
netdev_dpdk_rxq_recv
netdev_dpdk_rxq_recv(struct netdev_rxq *rxq, struct dp_packet_batch *batch) { /*调用dpdk接口rte_eth_rx_burst进行收包,一次最多收32个包*/ nb_rx = rte_eth_rx_burst(rx->port_id, rxq->queue_id, (struct rte_mbuf **) batch->packets, NETDEV_MAX_BURST); }
netdev_send
netdev_send(struct netdev *netdev, int qid, struct dp_packet_batch *batch, bool concurrent_txq) { int error; netdev_send_prepare_batch(netdev, batch); if (OVS_UNLIKELY(dp_packet_batch_is_empty(batch))) { return 0; } error = netdev->netdev_class->send(netdev, qid, batch, concurrent_txq); if (!error) { COVERAGE_INC(netdev_sent); } return error; }
lib/netdev-dpdk.c:5454:static const struct netdev_class dpdk_class = {
lib/netdev-dpdk.c:5462:static const struct netdev_class dpdk_ring_class = {
lib/netdev-dpdk.c:5470:static const struct netdev_class dpdk_vhost_class = {
lib/netdev-dpdk.c:5485:static const struct netdev_class dpdk_vhost_client_class = {
lib/netdev-dummy.c:1567:static const struct netdev_class dummy_class = {
lib/netdev-dummy.c:1572:static const struct netdev_class dummy_internal_class = {
lib/netdev-dummy.c:1577:static const struct netdev_class dummy_pmd_class = {
lib/netdev-linux.c:3552:const struct netdev_class netdev_linux_class = {
lib/netdev-linux.c:3568:const struct netdev_class netdev_tap_class = {
lib/netdev-linux.c:3583:const struct netdev_class netdev_internal_class = {
lib/netdev-linux.c:3598:const struct netdev_class netdev_afxdp_class = {
static const struct netdev_class dpdk_class = { .type = "dpdk", NETDEV_DPDK_CLASS_BASE, .construct = netdev_dpdk_construct, .set_config = netdev_dpdk_set_config, .send = netdev_dpdk_eth_send, }; static const struct netdev_class dpdk_ring_class = { .type = "dpdkr", NETDEV_DPDK_CLASS_BASE, .construct = netdev_dpdk_ring_construct, .set_config = netdev_dpdk_ring_set_config, .send = netdev_dpdk_ring_send, }; static const struct netdev_class dpdk_vhost_class = { .type = "dpdkvhostuser", NETDEV_DPDK_CLASS_COMMON, .construct = netdev_dpdk_vhost_construct, .destruct = netdev_dpdk_vhost_destruct, .send = netdev_dpdk_vhost_send, .get_carrier = netdev_dpdk_vhost_get_carrier, .get_stats = netdev_dpdk_vhost_get_stats, .get_custom_stats = netdev_dpdk_get_sw_custom_stats, .get_status = netdev_dpdk_vhost_user_get_status, .reconfigure = netdev_dpdk_vhost_reconfigure, .rxq_recv = netdev_dpdk_vhost_rxq_recv, .rxq_enabled = netdev_dpdk_vhost_rxq_enabled, };
gdb) s [Switching to Thread 0xfffd797ad510 (LWP 117399)] Breakpoint 5, netdev_send (netdev=0x1745d240, qid=qid@entry=0, batch=batch@entry=0xfffd4c004ea0, concurrent_txq=concurrent_txq@entry=true) at lib/netdev.c:893 893 error = netdev->netdev_class->send(netdev, qid, batch, concurrent_txq); (gdb) bt #0 netdev_send (netdev=0x1745d240, qid=qid@entry=0, batch=batch@entry=0xfffd4c004ea0, concurrent_txq=concurrent_txq@entry=true) at lib/netdev.c:893 #1 0x000000000096fae8 in dp_netdev_pmd_flush_output_on_port (pmd=pmd@entry=0x17dcfc70, p=p@entry=0xfffd4c004e70) at lib/dpif-netdev.c:4391 #2 0x000000000096fdfc in dp_netdev_pmd_flush_output_packets (pmd=pmd@entry=0x17dcfc70, force=force@entry=false) at lib/dpif-netdev.c:4431 #3 0x00000000009787d8 in dp_netdev_pmd_flush_output_packets (force=false, pmd=0x17dcfc70) at lib/dpif-netdev.c:4501 #4 dp_netdev_process_rxq_port (pmd=pmd@entry=0x17dcfc70, rxq=0x17432950, port_no=3) at lib/dpif-netdev.c:4486 #5 0x0000000000978a24 in pmd_thread_main (f_=0x17dcfc70) at lib/dpif-netdev.c:5731 #6 0x00000000009fc5dc in ovsthread_wrapper (aux_=<optimized out>) at lib/ovs-thread.c:383 #7 0x0000ffffb19f7d38 in start_thread (arg=0xfffd797ad510) at pthread_create.c:309 #8 0x0000ffffb16df690 in thread_start () from /lib64/libc.so.6 (gdb) s netdev_linux_send (netdev_=0x1745d240, qid=0, batch=0xfffd4c004ea0, concurrent_txq=true) at lib/netdev-linux.c:1696 1696 { (gdb) bt #0 netdev_linux_send (netdev_=0x1745d240, qid=0, batch=0xfffd4c004ea0, concurrent_txq=true) at lib/netdev-linux.c:1696 #1 0x00000000009a478c in netdev_send (netdev=0x1745d240, qid=qid@entry=0, batch=batch@entry=0xfffd4c004ea0, concurrent_txq=concurrent_txq@entry=true) at lib/netdev.c:893 #2 0x000000000096fae8 in dp_netdev_pmd_flush_output_on_port (pmd=pmd@entry=0x17dcfc70, p=p@entry=0xfffd4c004e70) at lib/dpif-netdev.c:4391 #3 0x000000000096fdfc in dp_netdev_pmd_flush_output_packets (pmd=pmd@entry=0x17dcfc70, force=force@entry=false) at lib/dpif-netdev.c:4431 #4 0x00000000009787d8 in dp_netdev_pmd_flush_output_packets (force=false, pmd=0x17dcfc70) at lib/dpif-netdev.c:4501 #5 dp_netdev_process_rxq_port (pmd=pmd@entry=0x17dcfc70, rxq=0x17432950, port_no=3) at lib/dpif-netdev.c:4486 #6 0x0000000000978a24 in pmd_thread_main (f_=0x17dcfc70) at lib/dpif-netdev.c:5731 #7 0x00000000009fc5dc in ovsthread_wrapper (aux_=<optimized out>) at lib/ovs-thread.c:383 #8 0x0000ffffb19f7d38 in start_thread (arg=0xfffd797ad510) at pthread_create.c:309 #9 0x0000ffffb16df690 in thread_start () from /lib64/libc.so.6 (gdb)
lib/netdev.c:883:netdev_send(struct netdev *netdev, int qid, struct dp_packet_batch *batch,
(gdb) b lib/netdev.c:883 Note: breakpoint 3 also set at pc 0x9a4568. Breakpoint 4 at 0x9a4568: file lib/netdev.c, line 883. (gdb) c Continuing. [New Thread 0xffffac55f910 (LWP 98082)] [Switching to Thread 0xfffd53ffd510 (LWP 117402)] Breakpoint 3, netdev_send (netdev=0x1745d240, qid=qid@entry=0, batch=batch@entry=0xfffd4408da40, concurrent_txq=concurrent_txq@entry=true) at lib/netdev.c:885 885 { (gdb) bt #0 netdev_send (netdev=0x1745d240, qid=qid@entry=0, batch=batch@entry=0xfffd4408da40, concurrent_txq=concurrent_txq@entry=true) at lib/netdev.c:885 #1 0x000000000096fae8 in dp_netdev_pmd_flush_output_on_port (pmd=pmd@entry=0x18f60810, p=p@entry=0xfffd4408da10) at lib/dpif-netdev.c:4391 #2 0x000000000096fdfc in dp_netdev_pmd_flush_output_packets (pmd=pmd@entry=0x18f60810, force=force@entry=false) at lib/dpif-netdev.c:4431 #3 0x00000000009787d8 in dp_netdev_pmd_flush_output_packets (force=false, pmd=0x18f60810) at lib/dpif-netdev.c:4501 #4 dp_netdev_process_rxq_port (pmd=pmd@entry=0x18f60810, rxq=0x1721f440, port_no=2) at lib/dpif-netdev.c:4486 #5 0x0000000000978a24 in pmd_thread_main (f_=0x18f60810) at lib/dpif-netdev.c:5731 #6 0x00000000009fc5dc in ovsthread_wrapper (aux_=<optimized out>) at lib/ovs-thread.c:383 #7 0x0000ffffb19f7d38 in start_thread (arg=0xfffd53ffd510) at pthread_create.c:309 #8 0x0000ffffb16df690 in thread_start () from /lib64/libc.so.6 (gdb) c Continuing. [Switching to Thread 0xfffd797ad510 (LWP 117399)] Breakpoint 3, netdev_send (netdev=0x1745d240, qid=qid@entry=0, batch=batch@entry=0xfffd4c004ea0, concurrent_txq=concurrent_txq@entry=true) at lib/netdev.c:885 885 { (gdb) bt #0 netdev_send (netdev=0x1745d240, qid=qid@entry=0, batch=batch@entry=0xfffd4c004ea0, concurrent_txq=concurrent_txq@entry=true) at lib/netdev.c:885 #1 0x000000000096fae8 in dp_netdev_pmd_flush_output_on_port (pmd=pmd@entry=0x17dcfc70, p=p@entry=0xfffd4c004e70) at lib/dpif-netdev.c:4391 #2 0x000000000096fdfc in dp_netdev_pmd_flush_output_packets (pmd=pmd@entry=0x17dcfc70, force=force@entry=false) at lib/dpif-netdev.c:4431 #3 0x00000000009787d8 in dp_netdev_pmd_flush_output_packets (force=false, pmd=0x17dcfc70) at lib/dpif-netdev.c:4501 #4 dp_netdev_process_rxq_port (pmd=pmd@entry=0x17dcfc70, rxq=0x17432950, port_no=3) at lib/dpif-netdev.c:4486 #5 0x0000000000978a24 in pmd_thread_main (f_=0x17dcfc70) at lib/dpif-netdev.c:5731 #6 0x00000000009fc5dc in ovsthread_wrapper (aux_=<optimized out>) at lib/ovs-thread.c:383 #7 0x0000ffffb19f7d38 in start_thread (arg=0xfffd797ad510) at pthread_create.c:309 #8 0x0000ffffb16df690 in thread_start () from /lib64/libc.so.6 (gdb)
netdev_dpdk_vhost
(gdb) bt #0 netdev_dpdk_vhost_send (netdev=0x16d6e3dc0, qid=0, batch=0xfffd440a1a20, concurrent_txq=true) at lib/netdev-dpdk.c:2887 #1 0x00000000009a478c in netdev_send (netdev=0x16d6e3dc0, qid=qid@entry=0, batch=batch@entry=0xfffd440a1a20, concurrent_txq=concurrent_txq@entry=true) at lib/netdev.c:893 #2 0x000000000096fae8 in dp_netdev_pmd_flush_output_on_port (pmd=pmd@entry=0x18f60810, p=p@entry=0xfffd440a19f0) at lib/dpif-netdev.c:4391 #3 0x000000000096fdfc in dp_netdev_pmd_flush_output_packets (pmd=pmd@entry=0x18f60810, force=force@entry=false) at lib/dpif-netdev.c:4431 #4 0x00000000009787d8 in dp_netdev_pmd_flush_output_packets (force=false, pmd=0x18f60810) at lib/dpif-netdev.c:4501 #5 dp_netdev_process_rxq_port (pmd=pmd@entry=0x18f60810, rxq=0x1721f440, port_no=2) at lib/dpif-netdev.c:4486 #6 0x0000000000978a24 in pmd_thread_main (f_=0x18f60810) at lib/dpif-netdev.c:5731 #7 0x00000000009fc5dc in ovsthread_wrapper (aux_=<optimized out>) at lib/ovs-thread.c:383 #8 0x0000ffffb19f7d38 in start_thread (arg=0xfffd53ffd510) at pthread_create.c:309 #9 0x0000ffffb16df690 in thread_start () from /lib64/libc.so.6 (gdb)
netdev_dpdk_eth_send
(gdb) bt #0 netdev_dpdk_eth_send (netdev=0x19feba4c0, qid=1, batch=0xfffd4c0050f0, concurrent_txq=false) at lib/netdev-dpdk.c:2960 #1 0x00000000009a478c in netdev_send (netdev=0x19feba4c0, qid=qid@entry=1, batch=batch@entry=0xfffd4c0050f0, concurrent_txq=concurrent_txq@entry=false) at lib/netdev.c:893 #2 0x000000000096fae8 in dp_netdev_pmd_flush_output_on_port (pmd=pmd@entry=0x17dcfc70, p=p@entry=0xfffd4c0050c0) at lib/dpif-netdev.c:4391 #3 0x000000000096fdfc in dp_netdev_pmd_flush_output_packets (pmd=pmd@entry=0x17dcfc70, force=force@entry=false) at lib/dpif-netdev.c:4431 #4 0x00000000009787d8 in dp_netdev_pmd_flush_output_packets (force=false, pmd=0x17dcfc70) at lib/dpif-netdev.c:4501 #5 dp_netdev_process_rxq_port (pmd=pmd@entry=0x17dcfc70, rxq=0x17432950, port_no=3) at lib/dpif-netdev.c:4486 #6 0x0000000000978a24 in pmd_thread_main (f_=0x17dcfc70) at lib/dpif-netdev.c:5731 #7 0x00000000009fc5dc in ovsthread_wrapper (aux_=<optimized out>) at lib/ovs-thread.c:383 #8 0x0000ffffb19f7d38 in start_thread (arg=0xfffd797ad510) at pthread_create.c:309 #9 0x0000ffffb16df690 in thread_start () from /lib64/libc.so.6 (gdb)
EMC + dpls + ofproto classifier
包从物理或者虚拟接口进入OVS-DPDK后根据包的头域将会得到一个唯一的标识或者hash,这个标识将会与以下3个交换表中的一条表项进行匹配。这三个交换表分别为:exact match cache(EMC),datapath classifier(dpcls),ofproto classifier。包将会按顺序遍历以上3个表直到找到表项与其匹配,匹配后包将执行匹配所指示的所有动作,然后进行转发。
EMC根据有限数量的表项对流提供快速的处理,在EMC中包标识必须与表项进行IP 5元组的精确匹配。若EMC未匹配上,那么包将进入dpcls。dpcls拥有多重子表来维持更多的表项,并且可使用通配(wildcard)对包标识进行匹配。当包与dpcls匹配后流表项将在EMC中进行设置,在此之后那些拥有与当前包相同标识的包可以根据EMC快速处理。若dpcls依旧未匹配上,那么包将进入ofproto classifier根据openflow控制器进行处理。若在ofproto classifier中匹配了相应的表项,那个该表项将项快速交换表分发,在此之后那些拥有相同流的包将被快速处理。(翻译自:https://software.intel.com/en-us/articles/open-vswitch-with-dpdk-overview)
注意:EMC是以PMD为边界的,每个PMD拥有自己的EMC;dpcls是以端口为边界的,每个端口拥有自己的dpcls;ofproto classifier是以桥为边界的,每个桥拥有自己的ofproto classifier
dp_netdev_input__(struct dp_netdev_pmd_thread *pmd, struct dp_packet_batch *packets, bool md_is_valid, odp_port_t port_no) { int cnt = packets->count; #if !defined(__CHECKER__) && !defined(_WIN32) const size_t PKT_ARRAY_SIZE = cnt; #else /* Sparse or MSVC doesn't like variable length array. */ enum { PKT_ARRAY_SIZE = NETDEV_MAX_BURST }; #endif OVS_ALIGNED_VAR(CACHE_LINE_SIZE) struct netdev_flow_key keys[PKT_ARRAY_SIZE]; struct packet_batch_per_flow batches[PKT_ARRAY_SIZE]; long long now = time_msec(); size_t newcnt, n_batches, i; odp_port_t in_port; n_batches = 0; /*将dp_packet_batch中的所有包送入EMC(pmd->flow_cache)处理 *返回要被送入fast_path_processing中处理的包数 *同时若md_is_valid该函数还将根据port_no初始化metadata*/ newcnt = emc_processing(pmd, packets, keys, batches, &n_batches, md_is_valid, port_no); if (OVS_UNLIKELY(newcnt)) { packets->count = newcnt; /* Get ingress port from first packet's metadata. */ in_port = packets->packets[0]->md.in_port.odp_port; fast_path_processing(pmd, packets, keys, batches, &n_batches, in_port, now); } }
packet_batch_per_flow_execute
(gdb) bt
#0 dp_netdev_execute_actions (actions_len=16, actions=0xfffd4c004ab4, flow=0xfffd4c005620, should_steal=true, packets=0xfffd797a5960, pmd=0x17dcfc70) at lib/dpif-netdev.c:7594
#1 packet_batch_per_flow_execute (pmd=0x17dcfc70, batch=0xfffd797a5950) at lib/dpif-netdev.c:6551
#2 dp_netdev_input__ (pmd=pmd@entry=0x17dcfc70, packets=packets@entry=0xfffd797aca80, md_is_valid=md_is_valid@entry=false, port_no=port_no@entry=3) at lib/dpif-netdev.c:7060
#3 0x0000000000978680 in dp_netdev_input (port_no=3, packets=0xfffd797aca80, pmd=0x17dcfc70) at lib/dpif-netdev.c:7069
#4 dp_netdev_process_rxq_port (pmd=pmd@entry=0x17dcfc70, rxq=0x17432950, port_no=3) at lib/dpif-netdev.c:4480
#5 0x0000000000978a24 in pmd_thread_main (f_=0x17dcfc70) at lib/dpif-netdev.c:5731
#6 0x00000000009fc5dc in ovsthread_wrapper (aux_=<optimized out>) at lib/ovs-thread.c:383
#7 0x0000ffffb19f7d38 in start_thread (arg=0xfffd797ad510) at pthread_create.c:309
#8 0x0000ffffb16df690 in thread_start () from /lib64/libc.so.6
(gdb)
(gdb) bt #0 packet_batch_per_flow_execute (pmd=0x17dcfc70, batch=0xfffd797a5950) at lib/dpif-netdev.c:6543 #1 dp_netdev_input__ (pmd=pmd@entry=0x17dcfc70, packets=packets@entry=0xfffd797aca80, md_is_valid=md_is_valid@entry=false, port_no=port_no@entry=3) at lib/dpif-netdev.c:7060 #2 0x0000000000978680 in dp_netdev_input (port_no=3, packets=0xfffd797aca80, pmd=0x17dcfc70) at lib/dpif-netdev.c:7069 #3 dp_netdev_process_rxq_port (pmd=pmd@entry=0x17dcfc70, rxq=0x17432950, port_no=3) at lib/dpif-netdev.c:4480 #4 0x0000000000978a24 in pmd_thread_main (f_=0x17dcfc70) at lib/dpif-netdev.c:5731 #5 0x00000000009fc5dc in ovsthread_wrapper (aux_=<optimized out>) at lib/ovs-thread.c:383 #6 0x0000ffffb19f7d38 in start_thread (arg=0xfffd797ad510) at pthread_create.c:309 #7 0x0000ffffb16df690 in thread_start () from /lib64/libc.so.6 (gdb)
upcall_receive
Breakpoint 5, upcall_receive (upcall=upcall@entry=0xfffd797aa730, backer=0x1746b1e0, packet=0x21ede43280, type=DPIF_UC_MISS, userdata=0x0, flow=flow@entry=0xfffd797ab768, mru=mru@entry=0, ufid=0xfffd797ab1b8, pmd_id=3) at ofproto/ofproto-dpif-upcall.c:1114 1114 { (gdb) bt #0 upcall_receive (upcall=upcall@entry=0xfffd797aa730, backer=0x1746b1e0, packet=0x21ede43280, type=DPIF_UC_MISS, userdata=0x0, flow=flow@entry=0xfffd797ab768, mru=mru@entry=0, ufid=0xfffd797ab1b8, pmd_id=3) at ofproto/ofproto-dpif-upcall.c:1114 #1 0x0000000000943620 in upcall_cb (packet=<optimized out>, flow=0xfffd797ab768, ufid=<optimized out>, pmd_id=<optimized out>, type=<optimized out>, userdata=<optimized out>, actions=0xfffd797ab1d8, wc=0xfffd797aba08, put_actions=0xfffd797ab218, aux=0x17463ac0) at ofproto/ofproto-dpif-upcall.c:1315 #2 0x000000000096c6e8 in dp_netdev_upcall (pmd=pmd@entry=0x17dcfc70, packet_=packet_@entry=0x21ede43280, flow=flow@entry=0xfffd797ab768, wc=wc@entry=0xfffd797aba08, ufid=ufid@entry=0xfffd797ab1b8, type=type@entry=DPIF_UC_MISS, userdata=userdata@entry=0x0, actions=actions@entry=0xfffd797ab1d8, put_actions=0xfffd797ab218) at lib/dpif-netdev.c:6466 #3 0x0000000000976558 in handle_packet_upcall (put_actions=0xfffd797ab218, actions=0xfffd797ab1d8, key=0xfffd797ac640, packet=0x21ede43280, pmd=0x17dcfc70) at lib/dpif-netdev.c:6823 #4 fast_path_processing (pmd=pmd@entry=0x17dcfc70, packets_=packets_@entry=0xfffd797aca80, keys=keys@entry=0xfffd797ac610, flow_map=flow_map@entry=0xfffd797ac4c0, index_map=index_map@entry=0xfffd797ac4b0 "", in_port=<optimized out>) at lib/dpif-netdev.c:6942 #5 0x0000000000977f58 in dp_netdev_input__ (pmd=pmd@entry=0x17dcfc70, packets=packets@entry=0xfffd797aca80, md_is_valid=md_is_valid@entry=false, port_no=port_no@entry=3) at lib/dpif-netdev.c:7031 #6 0x0000000000978680 in dp_netdev_input (port_no=3, packets=0xfffd797aca80, pmd=0x17dcfc70) at lib/dpif-netdev.c:7069 #7 dp_netdev_process_rxq_port (pmd=pmd@entry=0x17dcfc70, rxq=0x17432950, port_no=3) at lib/dpif-netdev.c:4480 #8 0x0000000000978a24 in pmd_thread_main (f_=0x17dcfc70) at lib/dpif-netdev.c:5731 #9 0x00000000009fc5dc in ovsthread_wrapper (aux_=<optimized out>) at lib/ovs-thread.c:383 #10 0x0000ffffb19f7d38 in start_thread (arg=0xfffd797ad510) at pthread_create.c:309 #11 0x0000ffffb16df690 in thread_start () from /lib64/libc.so.6 (gdb)
handle_packet_upcall
fast_path_processing 调用 handle_packet_upcall,fast_path_processing继续到ofproto classifier的流表查找 dp_netdev_input__ --> handle_packet_upcall ┣━ dp_netdev_upcall | ┣━ upcall_cb | ┣━ upcall_receive | ┣━ process_upcall ┣━dp_netdev_execute_actions ┣━ dp_netdev_flow_add
udpif_upcall_handler
udpif_upcall_handler
┣━ recv_upcalls
┣━dpif_recv
┣━upcall_receive
┣━process_upcall
▏ ┣━upcall_xlate
▏ ┣━xlate_actions
┣━handle_upcalls
┣━dpif_operate
┣━dpif->dpif_class->operate( dpif_netlink_operate)
- 内核匹配不到流表通过netlink发送到用户态处理,用户态 udpif_upcall_handler线程接收内核发送的upcall信息;
- 调用xlate_actions 进行动作处理,此函数会调用rule_dpif_lookup_from_table 在flow table 中进行规则查找,查找到规则后调用do_xlate_actions,根据action的不同执行不同的操作。
- handle_upcalls ,调用dpif_netlink_operate 修改内核中的datapath flow 规则。
dpif_recv(struct dpif *dpif, uint32_t handler_id, struct dpif_upcall *upcall, struct ofpbuf *buf) { int error = EAGAIN; if (dpif->dpif_class->recv) { error = dpif->dpif_class->recv(dpif, handler_id, upcall, buf); if (!error) { dpif_print_packet(dpif, upcall); } else if (error != EAGAIN) { log_operation(dpif, "recv", error); } } return error; }
const struct dpif_class dpif_netlink_class = { "system", false, /* cleanup_required */ NULL, /* init */ dpif_netlink_recv,
dpif_netlink_operate
dpif_netlink_operate ┣━try_send_to_netdev-->try_send_to_netdev-->parse_flow_put-->netdev_flow_put-->netdev_tc_flow_put ┣━dpif_netlink_operate_chunks ┣━dpif_netlink_operate__

调用process_upcall处理upcall信息,upcall类型分为
enum upcall_type {
BAD_UPCALL, /*Some kind of bug somewhere. */
MISS_UPCALL, /* Aflow miss. */
SFLOW_UPCALL, /*sFlow sample. */
FLOW_SAMPLE_UPCALL, /*Per-flow sampling. */
IPFIX_UPCALL /*Per-bridge sampling. */
};
内核datapath未匹配的类型为MISS_UPCALL。
调用xlate_actions 进行动作处理,此函数会调用rule_dpif_lookup_from_table 在flow table 中进行规则查找,查找到规则后调用do_xlate_actions,根据action的不同执行不同的操作。
OVS send部分
kernel
netdev_frame_hook-->netdev_port_receive-->ovs_vport_receive-->ovs_dp_process_packet-->ovs_execute_actions-->do_execute_actions-->do_output这里会根据dev的mtu和报文的mru比较需要不需要分片,通常情况下报文的mru是0,不需要分片,但是因为重组函数handle_fragments重组时设置了报文的mru,所以分片时也根据此项来判定。调用ovs_fragment分片完成之后会调用ovs_vport_send-->dev_queue_xmit-->dev_hard_start_xmit-->ops->ndo_start_xmit-->bond_start_xmit进行报文发送。
另一种的报文分片是VM中设置了TSO、GSO、UFO等features,导致报文比较大,这个时候需要根据标志判定是否需要分片。
netdev_frame_hook-->netdev_port_receive-->ovs_vport_receive-->ovs_dp_process_packet-->ovs_execute_actions-->do_execute_actions-->do_output-->ovs_vport_send-->dev_queue_xmit-->dev_hard_start_xmit这里会根据gso进行分片,分片完成后继续调用ops->ndo_start_xmit-->bond_start_xmit进行报文发送。其实此处也会根据其他的一些特性来判定,一般比如带了TSO之类的需要网卡去分片。
OVS-DPDK
pmd_thread_main-->dp_netdev_process_rxq_port-->dp_netdev_input-->dp_netdev_input__-->packet_batch_per_flow_execute-->dp_netdev_execute_actions-->dp_execute_cb-->netdev_send-->netdev_dpdk_eth_send一般会根据网卡的特性来判定是不是分片。
PKT_RX_FDIR_ID flag
/* Bit masks for the 'ol_flags' member of the 'dp_packet' structure. */ enum dp_packet_offload_mask { /* Value 0 is not used. */ /* Is the 'rss_hash' valid? */ DEF_OL_FLAG(DP_PACKET_OL_RSS_HASH, PKT_RX_RSS_HASH, 0x1), /* Is the 'flow_mark' valid? */ DEF_OL_FLAG(DP_PACKET_OL_FLOW_MARK, PKT_RX_FDIR_ID, 0x2), /* Bad L4 checksum in the packet. */ DEF_OL_FLAG(DP_PACKET_OL_RX_L4_CKSUM_BAD, PKT_RX_L4_CKSUM_BAD, 0x4), /* Bad IP checksum in the packet. */ DEF_OL_FLAG(DP_PACKET_OL_RX_IP_CKSUM_BAD, PKT_RX_IP_CKSUM_BAD, 0x8), /* Valid L4 checksum in the packet. */ DEF_OL_FLAG(DP_PACKET_OL_RX_L4_CKSUM_GOOD, PKT_RX_L4_CKSUM_GOOD, 0x10), /* Valid IP checksum in the packet. */ DEF_OL_FLAG(DP_PACKET_OL_RX_IP_CKSUM_GOOD, PKT_RX_IP_CKSUM_GOOD, 0x20), /* TCP Segmentation Offload. */ DEF_OL_FLAG(DP_PACKET_OL_TX_TCP_SEG, PKT_TX_TCP_SEG, 0x40), /* Offloaded packet is IPv4. */ DEF_OL_FLAG(DP_PACKET_OL_TX_IPV4, PKT_TX_IPV4, 0x80), /* Offloaded packet is IPv6. */ DEF_OL_FLAG(DP_PACKET_OL_TX_IPV6, PKT_TX_IPV6, 0x100), /* Offload TCP checksum. */ DEF_OL_FLAG(DP_PACKET_OL_TX_TCP_CKSUM, PKT_TX_TCP_CKSUM, 0x200), /* Offload UDP checksum. */ DEF_OL_FLAG(DP_PACKET_OL_TX_UDP_CKSUM, PKT_TX_UDP_CKSUM, 0x400), /* Offload SCTP checksum. */ DEF_OL_FLAG(DP_PACKET_OL_TX_SCTP_CKSUM, PKT_TX_SCTP_CKSUM, 0x800), /* Adding new field requires adding to DP_PACKET_OL_SUPPORTED_MASK. */ };
DPDK PMD收到报文后,通过检测rte_mbuf.flag中包含PKT_RX_FDIR_ID flag
dp_netdev_input__
dfc_processing
dp_packet_has_flow_mark(struct dp_packet *p OVS_UNUSED, uint32_t *mark OVS_UNUSED) { #ifdef DPDK_NETDEV if (p->mbuf.ol_flags & PKT_RX_FDIR_ID) { *mark = p->mbuf.hash.fdir.hi; return true; } #endif return false; }
dp_packet_has_flow_mark(const struct dp_packet *p, uint32_t *mark) { if (*dp_packet_ol_flags_ptr(p) & DP_PACKET_OL_FLOW_MARK) { *mark = *dp_packet_flow_mark_ptr(p); return true; } return false; }
if ((*recirc_depth_get() == 0) && dp_packet_has_flow_mark(packet, &mark)) { flow = mark_to_flow_find(pmd, mark); if (OVS_LIKELY(flow)) { tcp_flags = parse_tcp_flags(packet); if (OVS_LIKELY(batch_enable)) { dp_netdev_queue_batches(packet, flow, tcp_flags, batches, n_batches); } else { /* Flow batching should be performed only after fast-path * processing is also completed for packets with emc miss * or else it will result in reordering of packets with * same datapath flows. */ packet_enqueue_to_flow_map(packet, flow, tcp_flags, flow_map, map_cnt++); } continue; } }
struct rte_flow_action_mark
netdev_dpdk_add_rte_flow_offload(struct netdev *netdev, const struct match *match, struct nlattr *nl_actions OVS_UNUSED, size_t actions_len OVS_UNUSED, const ovs_u128 *ufid, struct offload_info *info) { struct netdev_dpdk *dev = netdev_dpdk_cast(netdev); const struct rte_flow_attr flow_attr = { .group = 0, .priority = 0, .ingress = 1, .egress = 0 }; struct flow_patterns patterns = { .items = NULL, .cnt = 0 }; struct flow_actions actions = { .actions = NULL, .cnt = 0 }; struct rte_flow *flow; struct rte_flow_error error; uint8_t *ipv4_next_proto_mask = NULL; int ret = 0; /* Eth */ struct rte_flow_item_eth eth_spec; struct rte_flow_item_eth eth_mask; memset(ð_spec, 0, sizeof(eth_spec)); memset(ð_mask, 0, sizeof(eth_mask)); if (!eth_addr_is_zero(match->wc.masks.dl_src) || !eth_addr_is_zero(match->wc.masks.dl_dst)) { rte_memcpy(ð_spec.dst, &match->flow.dl_dst, sizeof(eth_spec.dst)); rte_memcpy(ð_spec.src, &match->flow.dl_src, sizeof(eth_spec.src)); eth_spec.type = match->flow.dl_type; rte_memcpy(ð_mask.dst, &match->wc.masks.dl_dst, sizeof(eth_mask.dst)); rte_memcpy(ð_mask.src, &match->wc.masks.dl_src, sizeof(eth_mask.src)); eth_mask.type = match->wc.masks.dl_type; add_flow_pattern(&patterns, RTE_FLOW_ITEM_TYPE_ETH, ð_spec, ð_mask); } else { /* * If user specifies a flow (like UDP flow) without L2 patterns, * OVS will at least set the dl_type. Normally, it's enough to * create an eth pattern just with it. Unluckily, some Intel's * NIC (such as XL710) doesn't support that. Below is a workaround, * which simply matches any L2 pkts. */ add_flow_pattern(&patterns, RTE_FLOW_ITEM_TYPE_ETH, NULL, NULL); } /* VLAN */ struct rte_flow_item_vlan vlan_spec; struct rte_flow_item_vlan vlan_mask; memset(&vlan_spec, 0, sizeof(vlan_spec)); memset(&vlan_mask, 0, sizeof(vlan_mask)); if (match->wc.masks.vlans[0].tci && match->flow.vlans[0].tci) { vlan_spec.tci = match->flow.vlans[0].tci & ~htons(VLAN_CFI); vlan_mask.tci = match->wc.masks.vlans[0].tci & ~htons(VLAN_CFI); /* match any protocols */ vlan_mask.tpid = 0; add_flow_pattern(&patterns, RTE_FLOW_ITEM_TYPE_VLAN, &vlan_spec, &vlan_mask); } /* IP v4 */ uint8_t proto = 0; struct rte_flow_item_ipv4 ipv4_spec; struct rte_flow_item_ipv4 ipv4_mask; memset(&ipv4_spec, 0, sizeof(ipv4_spec)); memset(&ipv4_mask, 0, sizeof(ipv4_mask)); if (match->flow.dl_type == htons(ETH_TYPE_IP)) { ipv4_spec.hdr.type_of_service = match->flow.nw_tos; ipv4_spec.hdr.time_to_live = match->flow.nw_ttl; ipv4_spec.hdr.next_proto_id = match->flow.nw_proto; ipv4_spec.hdr.src_addr = match->flow.nw_src; ipv4_spec.hdr.dst_addr = match->flow.nw_dst; ipv4_mask.hdr.type_of_service = match->wc.masks.nw_tos; ipv4_mask.hdr.time_to_live = match->wc.masks.nw_ttl; ipv4_mask.hdr.next_proto_id = match->wc.masks.nw_proto; ipv4_mask.hdr.src_addr = match->wc.masks.nw_src; ipv4_mask.hdr.dst_addr = match->wc.masks.nw_dst; add_flow_pattern(&patterns, RTE_FLOW_ITEM_TYPE_IPV4, &ipv4_spec, &ipv4_mask); /* Save proto for L4 protocol setup */ proto = ipv4_spec.hdr.next_proto_id & ipv4_mask.hdr.next_proto_id; /* Remember proto mask address for later modification */ ipv4_next_proto_mask = &ipv4_mask.hdr.next_proto_id; } if (proto != IPPROTO_ICMP && proto != IPPROTO_UDP && proto != IPPROTO_SCTP && proto != IPPROTO_TCP && (match->wc.masks.tp_src || match->wc.masks.tp_dst || match->wc.masks.tcp_flags)) { VLOG_DBG("L4 Protocol (%u) not supported", proto); ret = -1; goto out; } if ((match->wc.masks.tp_src && match->wc.masks.tp_src != OVS_BE16_MAX) || (match->wc.masks.tp_dst && match->wc.masks.tp_dst != OVS_BE16_MAX)) { ret = -1; goto out; } struct rte_flow_item_tcp tcp_spec; struct rte_flow_item_tcp tcp_mask; memset(&tcp_spec, 0, sizeof(tcp_spec)); memset(&tcp_mask, 0, sizeof(tcp_mask)); if (proto == IPPROTO_TCP) { tcp_spec.hdr.src_port = match->flow.tp_src; tcp_spec.hdr.dst_port = match->flow.tp_dst; tcp_spec.hdr.data_off = ntohs(match->flow.tcp_flags) >> 8; tcp_spec.hdr.tcp_flags = ntohs(match->flow.tcp_flags) & 0xff; tcp_mask.hdr.src_port = match->wc.masks.tp_src; tcp_mask.hdr.dst_port = match->wc.masks.tp_dst; tcp_mask.hdr.data_off = ntohs(match->wc.masks.tcp_flags) >> 8; tcp_mask.hdr.tcp_flags = ntohs(match->wc.masks.tcp_flags) & 0xff; add_flow_pattern(&patterns, RTE_FLOW_ITEM_TYPE_TCP, &tcp_spec, &tcp_mask); /* proto == TCP and ITEM_TYPE_TCP, thus no need for proto match */ if (ipv4_next_proto_mask) { *ipv4_next_proto_mask = 0; } goto end_proto_check; } struct rte_flow_item_udp udp_spec; struct rte_flow_item_udp udp_mask; memset(&udp_spec, 0, sizeof(udp_spec)); memset(&udp_mask, 0, sizeof(udp_mask)); if (proto == IPPROTO_UDP) { udp_spec.hdr.src_port = match->flow.tp_src; udp_spec.hdr.dst_port = match->flow.tp_dst; udp_mask.hdr.src_port = match->wc.masks.tp_src; udp_mask.hdr.dst_port = match->wc.masks.tp_dst; add_flow_pattern(&patterns, RTE_FLOW_ITEM_TYPE_UDP, &udp_spec, &udp_mask); /* proto == UDP and ITEM_TYPE_UDP, thus no need for proto match */ if (ipv4_next_proto_mask) { *ipv4_next_proto_mask = 0; } goto end_proto_check; } struct rte_flow_item_sctp sctp_spec; struct rte_flow_item_sctp sctp_mask; memset(&sctp_spec, 0, sizeof(sctp_spec)); memset(&sctp_mask, 0, sizeof(sctp_mask)); if (proto == IPPROTO_SCTP) { sctp_spec.hdr.src_port = match->flow.tp_src; sctp_spec.hdr.dst_port = match->flow.tp_dst; sctp_mask.hdr.src_port = match->wc.masks.tp_src; sctp_mask.hdr.dst_port = match->wc.masks.tp_dst; add_flow_pattern(&patterns, RTE_FLOW_ITEM_TYPE_SCTP, &sctp_spec, &sctp_mask); /* proto == SCTP and ITEM_TYPE_SCTP, thus no need for proto match */ if (ipv4_next_proto_mask) { *ipv4_next_proto_mask = 0; } goto end_proto_check; } struct rte_flow_item_icmp icmp_spec; struct rte_flow_item_icmp icmp_mask; memset(&icmp_spec, 0, sizeof(icmp_spec)); memset(&icmp_mask, 0, sizeof(icmp_mask)); if (proto == IPPROTO_ICMP) { icmp_spec.hdr.icmp_type = (uint8_t)ntohs(match->flow.tp_src); icmp_spec.hdr.icmp_code = (uint8_t)ntohs(match->flow.tp_dst); icmp_mask.hdr.icmp_type = (uint8_t)ntohs(match->wc.masks.tp_src); icmp_mask.hdr.icmp_code = (uint8_t)ntohs(match->wc.masks.tp_dst); add_flow_pattern(&patterns, RTE_FLOW_ITEM_TYPE_ICMP, &icmp_spec, &icmp_mask); /* proto == ICMP and ITEM_TYPE_ICMP, thus no need for proto match */ if (ipv4_next_proto_mask) { *ipv4_next_proto_mask = 0; } goto end_proto_check; } end_proto_check: add_flow_pattern(&patterns, RTE_FLOW_ITEM_TYPE_END, NULL, NULL); struct rte_flow_action_mark mark; mark.id = info->flow_mark; add_flow_action(&actions, RTE_FLOW_ACTION_TYPE_MARK, &mark); struct rte_flow_action_rss *rss; rss = add_flow_rss_action(&actions, netdev); add_flow_action(&actions, RTE_FLOW_ACTION_TYPE_END, NULL); flow = rte_flow_create(dev->port_id, &flow_attr, patterns.items, actions.actions, &error); free(rss); if (!flow) { VLOG_ERR("rte flow creat error: %u : message : %s ", error.type, error.message); ret = -1; goto out; } ufid_to_rte_flow_associate(ufid, flow); VLOG_DBG("installed flow %p by ufid "UUID_FMT" ", flow, UUID_ARGS((struct uuid *)ufid));
Overview
This article describes the design and implementation of Open vSwitch* (OvS) with the Data Plane Development Kit (DPDK) (OvS-DPDK) datapath classifier, also known as dpcls. We recommend that you first read the introductory article where we introduce the high-level dpcls design, the Tuple-Space search (TSS) implementation and its performance optimization strategy, and a few other scenarios. Part 2 (this article) focuses on call graphs and the subroutines involved.
OvS-DPDK has three-tier look-up tables/caches. Incoming packets are first matched against Exact Match Cache (EMC) and in case of a miss are sent to the dpcls (megaflow cache). The dpcls is implemented as a tuple space search (TSS) that supports arbitrary bitwise matching on packet header fields. Packets that miss the dpcls are sent to the OpenFlow* pipeline, also known as ofproto classifier, configured by an SDN controller as depicted in Figure 1.

Figure 1. Open vSwitch* three-tier cache architecture.
Packet Reception Path
The poll mode driver (PMD) thread continuously polls the input ports in its poll list. From each port it can retrieve a burst of packets not exceeding 32 (NETDEV_MAX_BURST). Each input packet then can be classified based on the set of active flow rules. The purpose of classification is to find a matching flow so that the packet can be processed accordingly. Packets are grouped per flow and each group will be processed to execute the specified actions. Figure 2 shows the stages of packet processing.

Figure 2. Packet-processing stages.
Flows are defined by dp_netdev_flow data structure (not to be confused with the struct flow) and are stored into a hash table called flow_table. Some of the information stored in a flow are
- Rule
- Actions
- Statistics
- Batch (queue for processing the packets that matched this flow)
- Thread ID (owning this flow)
- Reference count
Often the words “flows” and “rules” are used interchangeably; however, note that the rule is part of the flow.
The entries stored in the dpcls subtables are {rule, flow pointer} couples. The dpcls classification can then be summarized as a two-step process where:
- A matching rule is found from the subtables after lookup.
- The actions of the corresponding flow (from the flow pointer) are then executed.
Figure 3 shows a call graph for packet classification and action execution.

Figure 3. Lookup, batching, and action execution call graph.
When a packet is received, the packet header fields get extracted and stored into a “miniflow” data structure as part of EMC processing. The miniflow is a compressed representation of the packet that helps in reducing the memory footprint and cache lines.
Various actions can be executed on the classified packet, such as forwarding it to a certain port. Other actions are available, for example adding a VLAN tag, dropping the packet, or sending the packet to the Connection Tracker module.
EMC Call Graph
EMC is implemented as a hash table where the match must occur exactly on the whole miniflow structure. The hash value can be pre-computed by the network interface card (NIC) when the RSS mode is enabled; otherwise hash is computed in the software using miniflow_hash_5tuple().

Figure 4. EMC processing call graph.
In emc_processing(), after the miniflow extraction and hash computation, a lookup is performed in EMC for a match. When a valid entry is found, an exact match check will be carried out to compare that entry with the miniflow extracted from the packet. In case of a miss, the check is repeated on the next linked entry, if any. If no match is found, the packet will be later checked against the dpcls, the second level cache. Figure 4 depicts the call graph of packet processing in exact match cache.
Datapath Classifier Call Graph
Figure 5 shows the main dpcls functions involved in the overall classification and batching processes.

Figure 5. dpcls call graph.
As described in our introductory article a dpcls lookup is performed by traversing all its subtables. For each subtable the miniflow extracted from the packet is used to derive a search key in conjunction with the subtable mask. See netdev_flow_key_hash_in_mask() function in Figure 6 where also hash functions are displayed.

Figure 6. dpcls lookup call graph.
A dpcls lookup involves an iterative search over multiple subtables until a match is found. On a miss, the ofproto table will be consulted. On a hit, the retrieved value is a pointer to the matching flow which will determine the actions to be performed for the packet. A lookup on a subtable involves the following operations:
- The subtable mask will determine the subset of the packet miniflow fields to consider. The mask is then applied on the subset of fields to obtain a search-key.
- A hash value is computed on the search-key to point to a subtable entry.
- If an entry is found, due to the possibility of collisions (as is the behavior in hash table data structures), a check has to be performed to determine whether or not that entry matches with the search key. If it doesn’t match, the check is repeated on the chained list of entries, if any.
Due to their wildcarded nature, the entries stored in dpcls are also referred to as “megaflows,” because an entry can be matched by “several” packets. For example with “Src IP = 21.2.10.*”, incoming packets with Src IPs “21.2.10.1” or “21.2.10.2” or “21.2.10.88” will match the above rule. On the other hand, the entries stored in EMC are referred to as “microflows” (not to be confused with the miniflow data structure).
Note that the term “fast path” comes from the vanilla OvS kernel datapath implementation where the two-level caches are located in kernel space. “Slow path” refers to the user-space datapath that involves the ofproto table and requires a context switch.
Subtables Creation and Destruction
The order of subtables in the datapath classifier is random, and the subtables can be created and destroyed at runtime. Each subtable can collect rules with a specific predefined mask, see the introductory article for more details. When a new rule has to be inserted into the classifier, all the existing subtables are traversed until a suitable subtable matching the rule mask is found. Otherwise a new subtable will be created to store the new rule. The subtable creation call graph is depicted in Figure 7.

Figure 7. Rule insertion and subtable creation call graph.
When the last rule in a subtable is deleted, the subtable becomes empty and can be destroyed. The subtable deletion call graph is depicted in Figure 8.

Figure 8. Subtable deletion call graph.
Slow Path Call Graph
On a dpcls lookup miss, the packet will be classified by the ofproto table, see Figure 9.
An “upcall” is triggered by means of dp_netdev_upcall(). The reply from Ofproto layer will contain all the information about the packet classification. In addition to the execution of actions, a learning mechanism will be activated: a new flow will be stored, a new wildcarded rule will be inserted into the dpcls, and an exact-match rule will be inserted into EMC. This way the two-layer caches will be able to directly manage similar packets in the future.

Figure 9. Upcall processing call graph.
Packet Batching
Packet classification categorizes packets with the active flows. The set of received packets is divided into groups depending on the flows that were matched. Each group is enqueued into a batch specific to the flow, as depicted in Figure 10.

Figure 10. Packet are grouped depending on the matching flow.
All packets enqueued into the same batch will be processed with the list of actions defined by that flow. To improve the packet forwarding performance, the packets belonging to the same flow are batched and processed together.
In some cases there could be very few packets in a batch. In a worst case scenario each packet of the fetched set is hitting a distinct flow, so each batch will enqueue only one packet. That becomes particularly inefficient when it comes to transmitting fewer packets over the DPDK interfaces as it incurs expensive MMIO writes. In order to optimize the MMIO transactions and improve the performance, an intermediate queue is implemented. Enqueued packets are transmitted when their count is greater than or equal to 32. Figure 11 depicts how the packet batching is triggered from emc_processing() and fast_path_processing().

Figure 11. Packet batching call graph.
Action Execution Call Graph
The action execution is done on a batch basis. A typical example of an action can be to forward the packets on the output interface. Figure 12 depicts the case where the packets are sent on the output port by calling netdev_send().

Figure 12. Action execution call graph.
Example of Packet Forwarding to a Physical Port

Figure 13. Overall call graph in case of a forwarding to a physical port.
The call graph in Figure 13 depicts an overall picture of the packet path from ingress until the action execution stage, wherein the packet of interest is forwarded to a certain output physical port.
command:
ovs-ofctl dump-flows br0
ovs-ofctl del-flows br0
ovs-ofctl -O openflow13 dump-flows s1
ovs-ofctl add-flow br0 "priority=0,actions=NORMAL"
https://software.intel.com/content/www/us/en/develop/articles/ovs-dpdk-datapath-classifier-part-2.html
OVS-DPDK DataPath Classifier反向设计
https://www.sdnlab.com/20901.html
OpenVSwitch实现浅谈(一)
https://zhuanlan.zhihu.com/p/66216907
Open vSwitch源码阅读笔记
https://www.sdnlab.com/18668.html